
0. 개요
확률분포를 공부하다 보면 각 분포의 평균과 분산이 공식으로만 주어지는 경우가 많습니다.
하지만 "왜 이런 형태가 나오는지"를 한 번쯤 직접 유도해 보는 것이 분포를 이해하는 데 훨씬 도움이 됩니다.
초기하분포(Hypergeometric distribution)는 이항분포와 유한 모집단에서 샘플을 추출한다는 점에서 동일하지만,
비복원추출이라는 차이로 인해 분산에서 약간의 차이가 발생합니다.
그래서 이번 포스팅에서는 초기하분포의 정의를 간단히 정리한 뒤,
평균과 분산을 직접 유도해보고 이항분포와의 차이를 함께 살펴보도록 하겠습니다.
1. 초기하분포의 정의
모집단의 크기가 $N$이고, 그중 관심있는 항목이 $N_1$개, 그 외 항목이 $N_2$개라고 하면,
$$ N = N_1 + N_2 $$
이 모집단에서 비복원으로 $n$개를 추출할 때, 성공의 개수를 확률변수 $X$라 하면 아래와 같이 표시할 수 있습니다.
$$ X \sim \text{Hypergeom}(N, N_1, n) $$
이때, 확률질량함수는 아래와 같습니다.
$$ f_X(x) = \frac{\binom{N_1}{x}\binom{N_2}{n-x}}{\binom{N}{n}}$$
2. 초기하분포의 평균 유도
기댓값의 정의에 따라 초기하분포의 평균을 아래와 같이 유도할 수 있습니다.

전체 $N$개 중 관심있는 항목의 개수가 $N_1$개가 존재하고 그 중 $n$개를 추출하므로 결과는 직관적이라고 볼 수 있습니다.
이항분포도 관심있는 항목이 나올 확률이 $p$인데, $n$개를 추출하므로 기댓값이 $np$인 것과 비슷합니다.
3. 초기하분포의 분산 유도
초기하분포의 분산 역시 평균과 비슷하게 유도할 수 있습니다.
분산의 공식 $Var(X) = E[X^2] - E[X]^2$에서 $E[X^2]$를 구하는 과정입니다.
이때, 약간의 트릭을 사용했습니다. $x^2$항을 $x(x-1) + x$로 분리해 보다 쉽게 분산을 구할 수 있습니다.
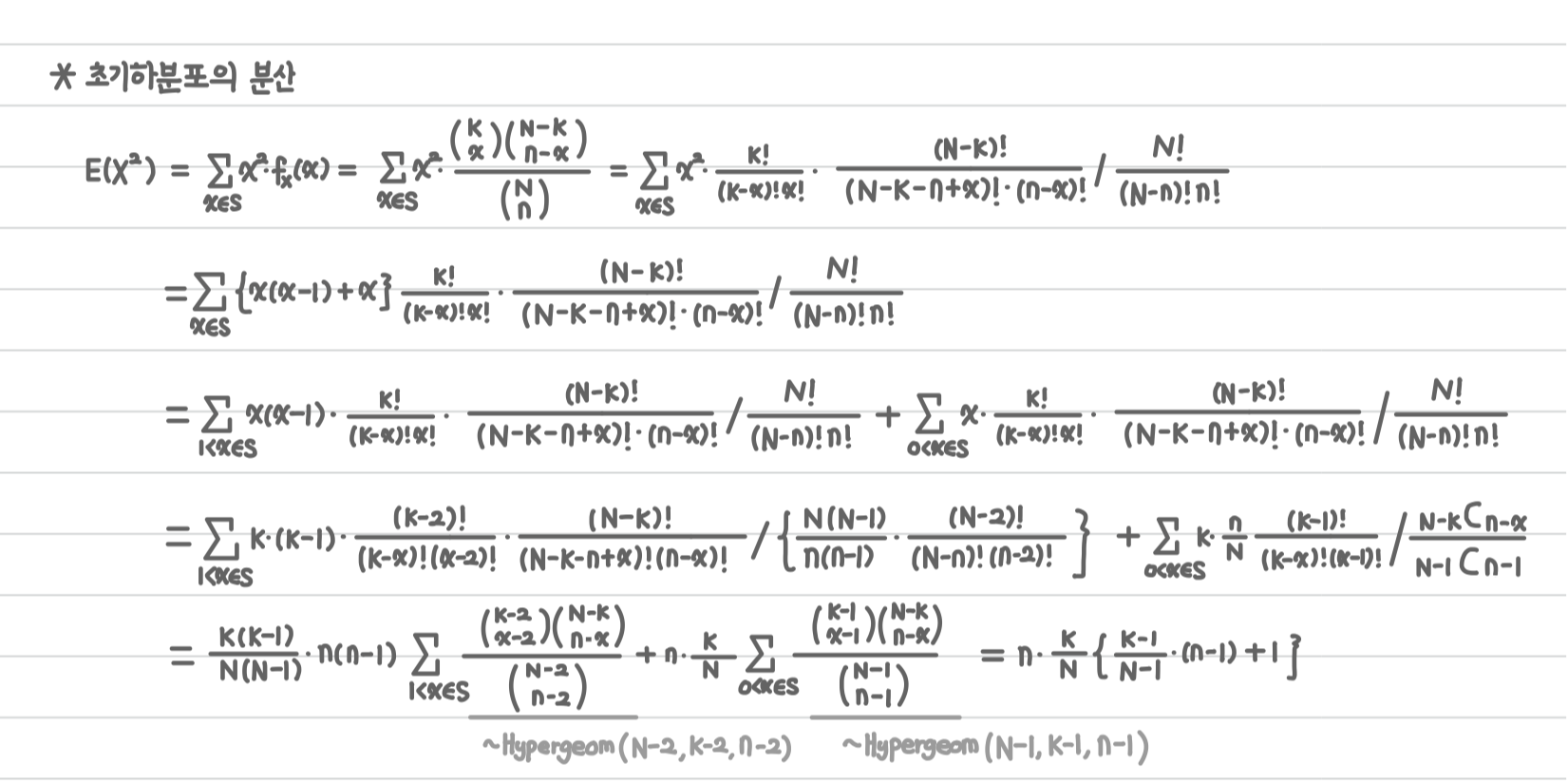
1차 및 2차 모멘트를 구했으므로 아래와 같이 분산을 구할 수 있습니다!
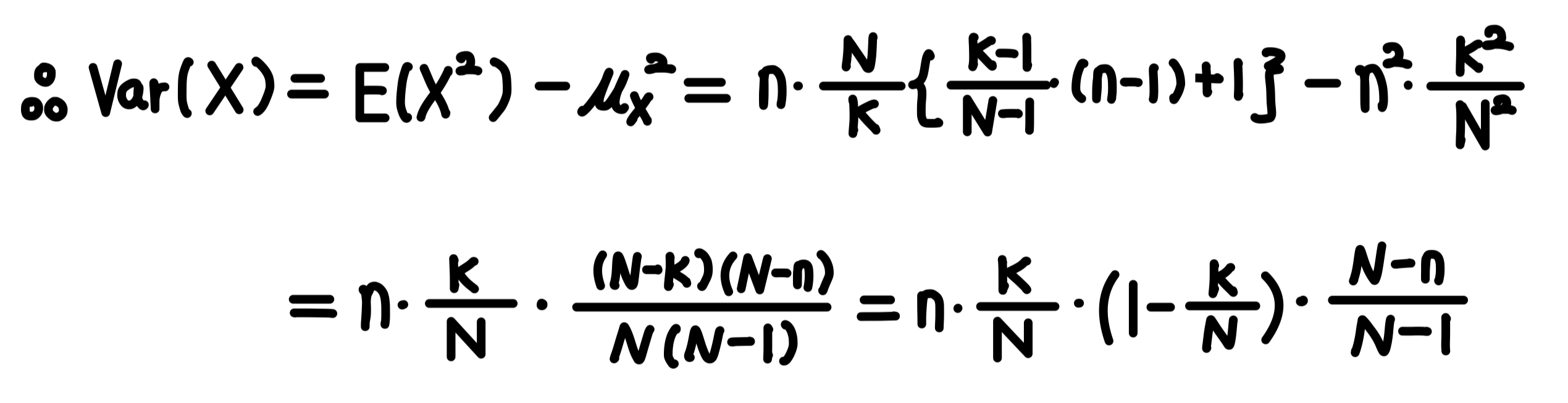
분산에 $\frac{N-n}{N-1}$이 곱해져 있는데 이는 초기하분포가 비복원추출 방식이기 때문입니다.
원하는 항목이 한 번 뽑히면, 다음 시행에서 그 항목이 뽑힐 확률은 감소합니다.
따라서 $n$개를 추출할 때 관심 있는 항목이 많이 나올 확률은 이항분포보다 작아지고, 그 결과 분산 역시 더 작아지게 됩니다.
참고로 이 보정항을 유한모집단 보정(finite population correction)이라고 부릅니다.
4. 예시: 마케팅 샘플링 캠페인
기업에서 신규 제품 출시를 앞두고 기존 고객을 대상으로 샘플 증정 이벤트를 진행한다고 합시다.
전체 고객 수는 1,000명이고, 그중 최근 3개월 이내 구매 이력이 있는 활성 고객(active user)이 300명, 그 외 고객이 700명이라고 가정하겠습니다.
이 중에서 무작위로 50명에게만 샘플을 증정할 계획이며, 샘플을 받은 고객 중 활성 고객의 수를 확률변수 $X$라고 하겠습니다.
그러면 아래와 같이 두 가지 상황을 고려해야 합니다.
1) 샘플을 받은 고객이 다시 뽑히지 않는 경우
2) 샘플을 받은 고객이 다시 뽑힐 수 있는 경우
1)의 경우 비복원추출로, 초기하분포를 사용해 모델링할 수 있습니다.
초기하분포의 평균은 $E(X) = n \cdot \frac{N_1}{N}$ 이므로, $E(X) = 50 \cdot \frac{300}{1000} = 15$
즉, 50명에게 샘플을 주면 평균적으로 15명 정도가 활성 고객일 것이라고 기대할 수 있습니다.
이때 분산은 $Var(X) = 50 \cdot \frac{300}{1000} \cdot \frac{700}{1000} \cdot \frac{1000-50}{1000-1} = 9.985$입니다.
2)의 경우 복원추출로, 이항분포를 사용해 모델링할 수 있습니다.
활성 고객은 전체 고객의 $\frac{300}{300+700} = 0.3$을 차지하므로 $X \sim B(50, 0.3)$으로 볼 수 있습니다. 이항분포의 평균은 $E(X) = n \cdot p = 50 * 0.3 = 15$로,
초기하분포와 마찬가지로 50명에게 샘플을 주면 평균적으로 15명 정도가 활성 고객일 것이라고 기대할 수 있습니다.
이때 분산은 $Var(X) = 50 \cdot 0.3 \cdot 0.7 = 10.5$로 초기하분포보다 큰 것을 확인할 수 있습니다.
'Statistics > Mathmetical Statistics' 카테고리의 다른 글
| 표본분산(Sample Variance)의 특징 (0) | 2024.12.22 |
|---|---|
| 모비율 신뢰구간 with Chebyshev & Hoeffding Inequality (0) | 2024.12.18 |
| 주축량(Pivotal Quantity)과 지수분포에서 모수의 신뢰구간 - 시뮬레이션 (0) | 2024.12.18 |
| 주축량(Pivotal Quantity)과 지수분포에서 모수의 신뢰구간 - 이론 (1) | 2024.12.17 |
| [확률과 통계적 추론] 8-4. 비모수적 검정 (Non-parametric Test) (0) | 2024.03.25 |