1. Overview
단순선형회귀(Simple Linear Regression)는 하나의 양적 설명변수 X에 기초하여 양적 반응변수 Y를 나타내는 기법으로 선형적 상관관계가 존재할때 적용할 수 있습니다.
- 모델(Model) : $ Y = \beta_{0} + \beta_{1} + \varepsilon $ (단, $\varepsilon \sim N(0, \sigma^2)$
- 예측(Prediction) : $ \widehat{Y} = \widehat{\beta_{0}} + \widehat{\beta_{1}}X $
- 파라미터(Parameter) : $\beta_{0}$은 회귀모형의 절편(Intercept), $\beta_{1}$은 회귀모형의 기울기(Slope)를 의미
- 파라미터 계수 추정 : 최소제곱법(Least Square Method) or 최대우도법(MLE)
- 목적 : 주어진 데이터를 이용해 회귀선을 추정하여 추론 및 예측에 사용
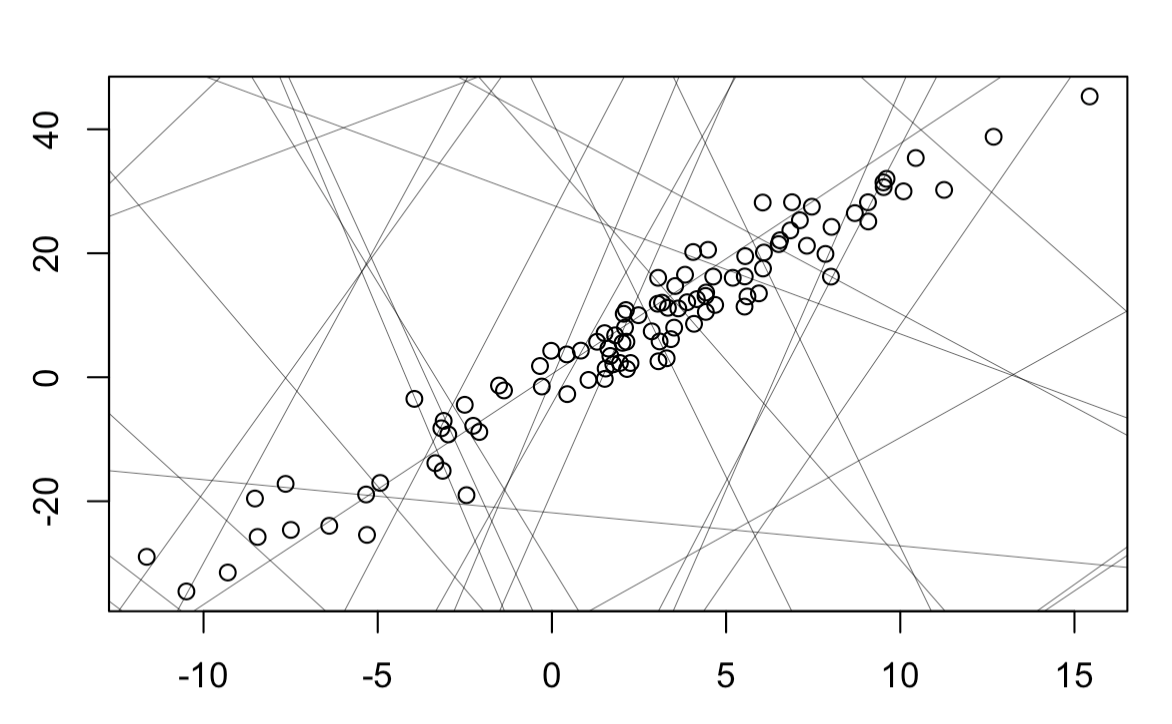
x <- rnorm(n=100, mean=2, sd=5)
y = 3*x + rnorm(n=100, sd=4)
plot(x,y, xlab="", ylab="")
slope <- runif(n=30, min=-100, max=100)
intercept <- runif(n=30, min=-15, max=15)
for(i in 1:30){
abline(slope[i], intercept[i], lwd=0.3)
}
2. 최소제곱법을 이용한 계수 추청
이제 회귀분석의 계수를 추정하는 방법에 대해 알아보겠습니다. 추정하는 방법은 최소제곱법, MLE, Gradient Descent 등 여러가지가 존재하지만 최소제곱법을 사용하여 계수를 추정하겠습니다. 우선 간단하게 생각해보면 위 그래프를 보면 데이터가 점으로 표시되어 있고, 다양한 직선들이 그 위를 지나고 있는게 보이시나요? 그리고 만약에 다른사람에게 하나의 직선을 통해 데이터를 설명하기 위해서는 직관적으로 점들에 가깝게 지나는 직선을 기준으로 설명할 겁니다. 이를 좀 더 수식적으로 표현해 보면 다음과 같습니다.
만약, 회귀선을 하나 설정했다면 우리는 지금 두가지 데이터를 가지고 있습니다. 하나는 실제데이터, 다른 하나는 예측데이터이죠.
실제데이터는 $( x_i, y_i )$, 예측데이터는 $(x_i, \widehat{y_i})$로 표현할 수 있겠네요. 이때 예측한 $ \widehat{y_i} $의 값과 실제 $y_i$의 값이 같으면 같을수록 좋습니다. 그래야지 예측한게 실제데이터에 비슷해지니까요.
여기서 잔차의 개념이 나오는데, 잔차는 $e$로 표현하며 $e = y - \widehat{y} $로 표현할 수 있습니다. 이것은 관측된 반응변수의 값에서 회귀모델에 의해 예측된 반응변수의 차이를 의미합니다. 또 잔차에 제곱을 해서 모두 더해주게 되는데요. 이를 잔차제곱합(RSS, Residual Sum of Squares)라고 하며 수식적으로 표현하면 아래와 같습니다.
$$ RSS = e_1^2 + e_2^2 + \cdots + e_n^2 = \sum_{i=1}^{n}{e_i^2} = \sum_{i=1}^{n}{(y_i - \widehat{y_i})^2}$$
처음에 $\widehat{y_i} = \widehat{\beta_{0}} + \widehat{\beta_{1}}x$로 정의했으므로 RSS 정의에 해당 식을 대입하면 다음과 같이 표현할 수 있겠습니다.
$$ RSS = \sum_{i=1}^{n}{(y_i - \widehat{\beta_{0}} + \widehat{\beta_{1}}x)^2} $$
최소제곱법은 잔차제곱합(RSS)를 최소로 만드는 것이 목표이므로 수식을 각 $\beta_{0}$와 $\beta_{1}$에 대해 편미분을 해서 풀어주면 됩니다. 해당 증명 과정은 다음과 같습니다.

즉 결론적으로 회귀선의 파라미터 계수는 아래와 같이 표현할 수 있습니다.
$\beta_{1}^{LSM} = \frac{Cov(X,Y)}{ Var(X)}$ $\beta_{0}^{LSM} = \overline{y} - \beta_{1}^{LSM}\overline{x}$
3. R을 이용한 실습
MASS 라이브러리에 있는 Boston 데이터셋을 가지고 선형회귀분석을 실습해 보려고합니다.
Boston 데이터셋은 Boston 교회 506개 지역의 주택 가격 중앙값(medv)와 주택당 평균 방의 개수(rm), 주택 연령(age)와 같은 변수로 구성되어 있는데, 주택당 평균 방의 개수(rm)을 이용하여 주택 가격(medv)를 적합해보려고 합니다.
library(MASS)
library(tidyverse)
Boston %>%
ggplot(mapping=aes(x=rm, y=medv)) +
geom_point(alpha=0.7) + geom_smooth(formula=y~x, method='lm')
lm.fit = lm(formula=medv~rm, data=Boston)
sprintf("Intercept : %.2f Slope : %.4f", lm.fit$coefficients[1], lm.fit$coefficients[2])
beta1 = cov(Boston$rm, Boston$medv)/var(Boston$rm)
beta0 = mean(Boston$medv) - beta0 * mean(Boston$rm)
sprintf("Intercept : %.2f Slope : %.4f", beta0, beta1)

함수를 이용했을 때와 직접 계산했을 때 같은 값이 나오는 것을 확인할 수 있습니다.
다음에는 회귀분석의 계수 추정값의 표준오차와 모델의 정확도에 대해서 알아보겠습니다.
'AI > Machine Learning' 카테고리의 다른 글
| [ISR] 3. 선형회귀(Linear Regression) Part 4 (0) | 2023.03.09 |
|---|---|
| [ISR] 3. 선형회귀(Linear Regression) Part 3 (0) | 2023.03.08 |
| [ISR] 3. 선형회귀(Linear Regression) Part 2 (0) | 2023.03.08 |
| [ISR] 2. Bayes Classifier & KNN (2) | 2023.02.20 |
| [ISR] 2. 통계학습(Statistical Learning) (0) | 2023.02.20 |