1-1. filter( )로 조건에 맞는 행 선택

- 설명 : 조건을 만족하는 모든 행을 남기는 데이터 프레임 서브셋팅(Subsetting) 함수
- 조건의 결과가 TRUE인 모든 행을 남기며, FALSE나 NA를 반환 시에는 해당 행은 출력하지 않는다.
- dot-dot-dot (...)에 (논리)조건이 들어가며 여러 개의 조건이 들어가면 & 연산으로 묶여서 계산
- [advanced] Lazy Evaluation을 지원하므로 결과를 필요로 하기 전까지 필터링 조건을 평가하지 않음
- 유용한 필터링 함수
- 논리연산자 : &(and), |(or), !(not), xor
- between(x, a, b) : [a, b]에 포함되는 x는 TRUE 반환
- x %in% y : x가 y에 포함되는지 반환하는 논리함수
- near(x, y, tol) : 부등소수점 비교시 유용
- is.na(x) : x의 값이 NA인지 확인하는 논리함수
- str_detect : 문자열에 정규표현식(Regex)가 포함되어 있는지 확인하는 함수
- [참고] Grouping 연산 지원하므로 grouped data / ungrouped data에 따라 결과가 다를 수 있다.
test <- tibble(name = rep(letters[1:3], each=3), num = 1:9)
test |> filter(num >= mean(num))
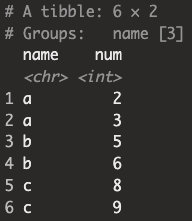
test |> group_by(name) %>% filter(num >= mean(num))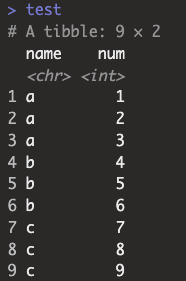
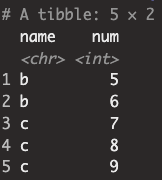
- [코드설명] 그룹화 되지 않은 경우에는 전체 평균(1~9의 평균인 5)보다 같거나 큰 값들이 출력
- [코드설명] 그룹화 된 경우에는 각 그룹(a, b, c)에서의 평균을 구하여(2, 5, 8) 각 그룹의 원소가 그룹의 평균보다 큰 경우에 출력
[참고-advanced] 다양한 테이블에 동일한 조건 필터링을 해야하는 경우 expr함수와 !!를 사용할 수 있다.
expr함수를 사용해 코드를 실행시키지 않고 표현식을 반환하고 추후에 필요한 부분에 평가하여(!!) 다양한 테이블에 동일한 연산을 수행할 수 있도록 한다.
my_condition <- rlang::expr(Sepal.Length > 3 & Species %in% c("setosa", "virginica"))
iris |> filter(!!my_condition)
1-2. Slice( )로 위치에 따른 행 선택

- 행 선택, 행 제거, 행 중복 등 다양하게 활용할 수 있음 ( https://moogie.tistory.com/83 참고 )
- dot-dot-dot (...)에 정수형 벡터를 지정할 수 있으며 양수인 경우는 해당 행을 출력, 음수인 경우에는 해당 행 제외한 결과 출력
- Grouping 연산을 지원하므로 grouped data / ungrouped data에 따라 결과가 다를 수 있다.
- 관련 함수 설명
- slice_head와 slice_tail은 각각 첫번째, 마지막부터 n개의 행을 선택 (prop 인자 제공시 nrow(data)*prop의 수만큼)
- slice_sample은 행을 랜덤하게 선택 (argument : replace, weight_by)
- slice_min, slice_max 함수는 주어진 변수(order_by)의 가장 작은/큰 행의 모든 열과 함께 보여준다. (with_ties로 동점 처리 설정)
1-3. distinct( )로 중복되지 않은 행 선택
- 각 데이터포인트(인스턴스)가 유일한 데이터 포인트만 반환하여 모든 변수의 값이 같은 행은 제거
- unique.data.frame 함수와 동작 방식이 유사하며 distinct(df, col1, col2)는 unqiue(select(df, col1, col2))와 같다.
- [참고] count(x, ...) 함수를 사용하여 1개 이상의 변수 값의 유일값의 개수 또는 각 그룹에서의 관측치 수를 반환하는 함수로
count(df, a, b)는 group_by(df, a, b) |> summarise(n=n())와 같다.
flights |> distinct() # remove duplicate rows
flights |> distinct(origin, dest)

1-4. arrange( )로 값의 크기에 따른 행 정렬

- 열의 값을 기준으로 데이터 프레임의 행을 정렬하는 함수
- Grouping 연산을 지원하지 않으므로 그룹화 연산을 원한다면 인자 .by_group = T를 사용해야 함
iris_test <- iris |> group_by(Species) |> slice_sample(n=2)
iris_test |> arrange(Sepal.Width, Petal.Width)
iris_test |> arrange(Sepal.Width, Petal.Width, .by_group = T)


- 기본적으로 오름차순으로 정렬하나 내림차순 정렬하려면 desc( ) 함수를 사용해야 함
- 결측값 NA는 항상 마지막에 정렬되지만, desc함수와 is.na 함수를 활용해 처음에 나오도록 할 수 있다.
- 데이터가 큰 경우에 여러 열을 기준으로 정렬하면 속도가 느릴 수 있으므로 data.table::setorder를 활용
# 5천만개의 데이터를 정렬하는 시간 비교
# dplyr::arrange --> 100회 평균 13초
# data.table::setorder --> 100회 평균 2초
bigdata <- diamonds |> slice(rep(1:50000, 1000))
microbenchmark::microbenchmark(
"dplyr"=bigdata |> arrange(carat, price),
"data.table"=bigdata |> data.table::setorder(carat, price),
times = 100)
# Unit: seconds
# expr min lq mean median uq max neval
# dplyr 4.231359 12.185045 13.52448 12.856467 13.717012 39.87647 100
# data.table 1.633217 1.683112 2.07923 1.841243 1.990142 26.06883 100
- Selection helper(선택도우미) 함수를 지원하지 않으므로 pick, across 함수와 활용하면 좋음
- pick(...) : 데이터 마스킹을 지원하는 함수(mutate, arrange, summarise, group_by) 등에서 select 구문을 사용하여 주어진 데이터 열의 하위 집합을 쉽게 선택하는 함수
- across(.cols, .fns, ...) : 데이터 마스킹을 지원하는 함수(mutate, arrange, summarise, group_by) 등에서 select 구문을 사용하여 다수의 열에 동일한 변환을 적용하는 함수
- 두 함수 모두 select( ) 구문을 사용하므로 pick, across 함수 내부에서 선택도우미 함수 사용 가능
iris |> arrange(Sepal.Length, Sepal.Width) # work!
iris |> arrange(starts_with("Sepal")) # error
iris |> arrange(pick(starts_with("Sepal"))) # work!# same results
iris |> arrange(across(starts_with("Sepal"), desc))
iris |> arrange(desc(Sepal.Length), desc(Sepal.Width))
2-1. select( )로 열 선택

- 열의 이름이나 종류(type), 위치 등을 이용해서 열 출력을 유지하거나 드랍하는 함수
- (열이름1:열이름2) 와 같이 사용하면 데이터 내 열이름1 ~ 열이름2 사이에 있는 열들이 자동으로 선택됨
- -(열이름), !(열이름) 와 같이 사용하면 해당 열이름을 제외한 나머지 열들을 선택
- rename(dataset, 변경할이름 = 기존변수명), select(dataset, 변경할변수명 = 기존변수명)
(purrr::set_names에 unamed vector를 제공하여 일괄로 변경할 수 있음)
(janitor::clean_names를 사용해 복잡한 변수 명을 문자와 숫자, _로 이루어진 유연한 변수 명으로 변환) - 동일한 열을 여러번 입력해도 한번만 출력되며, 열의 이름을 바꿀때 데이터프레임에 동일한 열이름이 있으면 에러 발생
- Selection Helper Function (선택 도우미 함수)
| starts_with("abc") | "abc"로 시작하는 열과 매칭 | everything( ) | 모든 열과 매칭 |
| ends_with("xyz") | "xyz"로 끝나는 열과 매칭 | last_col() | 데이터의 마지막 열을 매칭 |
| contains("ijk") | "ijk"를 포함하는 열과 매칭 | group_cols() | 모든 그룹핑 변수 매칭 |
| matches("regexp") | 정규표현식을 포함하는 열과 매칭 | all_of / any_of | 문자형 벡터에 속한 이름의 열과 매칭 (https://moogie.tistory.com/75) |
| num_range("x", 1:3) | "x1", "x2", "x3"에매칭 | where | 모든 열에 함수를 적용하여 TRUE를 반환하는 열과 매칭 |
2-2. Keep( ), Discard( ), Compact( )로 원하는 조건의 열 남기기

- keep 함수는 논리함수의 결과 참인 열을 남기며, discard 함수는 논리함수의 결과가 참이 아닌 열을 남기는 함수
- compact 함수는 NULL인 요소나 길이가 0인 요소를 제거한 결과를 출력하는 함수
- predicate function을 나타내는 .p인자에는 일반함수, anonymous 함수, formula가 올 수 있다.
예시) mpg에서 문자형 열만 출력하기 위해 select / keep / discard 함수를 활용한 코드
mpg |> select(where(is_character))
mpg |> keep(is_character)
mpg |> discard(~!is_character(.))
2-3. Pull( )로 원하는 열 선택하기

- subsetting operation "$"와 유사하나 pipe에서 보기 좋게 작동함
- 추출하고자 하는 요소의 값을 var에 지정할 수 있으며 변수이름, 양의정수, 음의정수가 올 수 있다.
3. mutate( )로 새로운 변수 추가
- 기존 변수에 다양한 함수를 적용하여 새로운 열을 추가하는 함수
- Grouping 연산을 지원하므로 grouped data / ungrouped data에 따라 결과가 다를 수 있다.
- [파라미터 설명] .before / .after : 기본적으로 새로운 열은 맨 오른쪽에 추가되나 .before, .after 인자를 사용해 신규 열의 위치를 조정할 수 있다.
- [파라미터 설명] .keep : 새로운 열과 함께 반환할 기존 열을 지정하는 옵션으로 기본값으로는 all(모든값)이나 used(mutate에 사용된 변수만 남길때), unused(mutate에 사용되지 않은 변수만), none(변수를 남기지 않음) 옵션 존재
- [파라미터 설명] .by : 새로운 열을 만들때, 특정 열의 값을 그룹으로 함수를 적용하는 경우 사용 (group_by 처럼 작동)
- [참고] mutate(data, 삭제할열이름=NULL)로 설정시 열삭제(Column Drop) 가능 (단, 실제 data에 반영되지는 않음)
- [참고] transmute( )는 새로운 변수만 남기는 함수로 mutate(.keep = "none")와 유사
- [참고] 유용한 함수
| 함수 | 설명 | 함수 | 설명 |
| min_rank | 값이 같으면 공동 랭킹을 갖는 랭킹 함수로 rank(ties.method="min")와 동일하며 1, 2, 2, 4, ... 와 같이 진행한다 |
row_number | 값이 같으면 관측이 빠른 값을 더 작은 랭킹 값으로 rank(ties.method="first")와 동일하며 1, 2, 3, 4, ... 와 같이 진행한다 |
| dense_rank | min_rank와 유사하나 랭킹간에 갭이 동일한 랭킹 함수 | percent_rank | min_rank를 [0, 1]로 리스케일링 한 랭킹 함수 |
| cume_dist | 해당 값의 누적 분포 함수 | ntile | 지정된 집단 수 n에 따라 랭킹을 매김 이때 각 집단의 수는 비슷하게 설정 |
| lead(x) | 벡터에서 다음값을 찾는 함수로 한칸씩 당겨온다 lead(1:5, 1) >> 2, 3, 4, 5, NA |
lag(x) | 벡터에서 이전값을 찾는 함수로 한칸씩 뒤로 민다. lag(1:5, 1) >> NA, 1, 2, 3, 4 |
| pmax / pmin | pmax(변수1, 변수2, 변수3)이면 변수1, 변수2, 변수3에서 제일 큰 값을 각 행마다 반환 | first / last / nth | 첫번째 / 마지막/ n번째 값을 추출한다. |
| cum* function | cumsum, cummean, cummin, cummax | na_if(x, y) | x와 y의 값이 동일하면 해당 x의 값을 NA로 변환 |
| coalesce | missing value의 값을 특정 값으로 변환 | replace_na | NA를 특정 값으로 변환 |
| case_match (.x, ...) |
switch 함수와 사용이 유사하며 여러 switch 구문의 벡터화가 허락된다. 이때 각 케이스는 two-sided formula로 작성 |
case_when (...) |
여러 if_else 구문의 벡터화를 제공하는 함수로 처음으로 조건(condition)에 일치하는 값을 반환하므로 순서에 주의 |
case_when(
x %in% c("a", "b") ~ 1,
x %in% "c" ~ 2,
x %in% c("d", "e") ~ 3
)
case_match(
x,
c("a", "b") ~ 1,
"c" ~ 2,
c("d", "e") ~ 3
)
아래 문제를 풀 때, 파이프 연산자를 사용해 댓글에 남겨주세요.
[Q] iris 데이터에서 모든 수치형 변수를 각 변수 내에서의 값의 순위(rank)로 변환하시오.

[Q] diamonds 데이터셋에서 각 관측값의 price와 해당 관측값이 속한 cut 그룹의 price 평균 간의 차이의 제곱을 구하시오.
4-1. group_by( )로 그룹화
- 그룹화 된 데이터를 다루는 유용한 함수
- group_data : 그룹화된 구조를 정의하는 데이터프레임을 반환 (각 그룹과 List-Column 형식으로 각 그룹별 데이터 위치 제공)
- group_keys : 그룹화에 사용된 유일한 변수의 값을 데이터 프레임 형식으로 반환
- group_rows : 각 그룹에 속한 데이터의 위치를 List 형식으로 반환
- group_indices : 각 데이터가 속한 그룹의 고유번호 반환
- group_vars : 그룹화에 사용된 변수의 이름을 문자형 벡터로 반환
- group_size : 각 그룹의 원소 수를 반환
- n_groups : 그룹의 수를 반환
- ungroup 함수를 통해 그룹화 해제
- purrr-style function (함수형 프로그래밍 함수)
- group_map(.data, .f, ...) : 각 그룹별로 .f 함수를 적용하여 나온 결과를 리스트로 반환
- group_modify(.data, .f, ...) : 각 그룹별로 .f 함수를 적용하여 나온 결과를 재구성해 데이터 프레임으로 반환
(.f로 함수나 formula가 올 수 있는데, formula인 경우 "."(또는 ".x")은 각 그룹데이터를 나타내며, ".y"는 키를 나타내는 티블
- 기타 유용한 함수
- group_nest : grouping specification을 통한 중첩(nest) 티블 반환
- group_split : 데이터 프레임을 각 그룹 기준으로 분리하는 함수로 리스트 반환
- group_trim : 데이터에 존재하지 않는 그룹화 범주를 제거(Drop)하는 함수
4-2. summarise( )로 그룹화 요약

- 새로운 데이터 프레임을 생성하며 그룹 변수의 각 조합별로 요약된 값을 반환한다. (그룹화된 데이터가 아닐시 전체 데이터 요약)
- ...에는 이름과 요약을 수행할 함수가 지정되어야 하며 반환 값은 길이가 1인 벡터이거나 데이터 프레임이여야 함
- [파라미터 설명] 그룹화 된 데이터 프레임에 summarise를 적용하는 경우 기본적으로 마지막 그룹화 변수를 벗겨내지만(peel off) .groups 옵션을 통해서 제어할 수 있다. (default = "drop_last", "drop"(그룹화 해제), "keep"(그룹화 유지))
- summarise에 유용한 함수
- n( ) : 그룹 내 관측수를 반환
- n_distinct( ) : 그룹 내 유일값의 수를 반환
'Data Science > Manipulation' 카테고리의 다른 글
| [Data Science With R] 6. 파싱(Parsing) (202405) (0) | 2023.03.31 |
|---|---|
| [Data Science With R] 5. readr로 파일 읽기 (202503) (0) | 2023.03.31 |
| [Data Science With R] 4. 티블(Tibble) (202406) (1) | 2023.03.30 |
| [Data Science With R] 3. 탐색적 데이터 분석 (Exploratory Data Analysis) (202405) (0) | 2023.03.29 |
| [Data Science with R] 1. 데이터 시각화 (202405) (1) | 2023.03.29 |