0. 개요
챕터 12에서부터 다루고 있는 하이퍼파라미터는 일반적인 파라미터와 다르게 학습데이터에서 직접적으로 추정할 수 없습니다.
챕터 13에서는 그리드서치(Grid Search)라는 방법을 통해 사전에 지정해놓은 여러개의 후보들을 평가하는 내용을 다루었습니다.
챕터 14에서는 Iterative Search이라는 방법을 소개하는데, 현재 주어진 하이퍼파라미터의 값들을 통해 스스로 성능이 좋을 것으로 기대되는 하이퍼파라미터 값을 예측하고 평가하는 방식으로 최적의 값을 찾아냅니다.
14 Iterative Search | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
본문에서는 SVM(Support Vector Machine) 모델을 사용해 Iterative Search에 대해 소개하고 있지만,
여기서는 저번 포스팅에서 사용한 부스팅 모델을 사용하였습니다.
# Load Package
library(tidymodels)
library(tidyverse)
library(usemodels)
# Split Data
data(cells)
cells <- modeldata::cells
cells |> ggplot(mapping=aes(x=class, fill=class)) + geom_bar()
cells_split <- cells |> rsample::initial_split(strata = class, prop=0.75)
cells_train <- cells_split |> training()
cells_test <- cells_split |> testing()
cells_folds <- cells_train %>% rsample::vfold_cv(v=10, repeats = 5, strata = class)
# model spec and recipe
xgboost_recipe <- recipe(formula = class ~ ., data = cells_train) |>
update_role(case, new_role = "splitting variable") |>
step_nzv(all_predictors()) |>
step_normalize(all_predictors()) |>
step_pca(all_double_predictors(), num_comp = tune())
xgboost_model <-
boost_tree(mtry = tune(), trees=100, tree_depth = tune(),
learn_rate = tune(), loss_reduction = tune()) |>
set_mode(mode = "classification") |>
set_engine(engine = "xgboost")
xgboost_workflow <-
workflow() |> add_recipe(xgboost_recipe) |> add_model(xgboost_model)
# parameter setting
xgboost_param <- xgboost_workflow |> extract_parameter_set_dials()
xgboost_param$object
xgboost_param <- xgboost_param |>
update(num_comp = num_comp(range = c(0, unknown()))) |>
finalize(cells_train)
xgboost_param$object
또한, Iterative Search로 소개할 방법 모두 사전에 하이퍼파라미터에 대한 Resampled Performance를 필요로 하므로 아래 코드와 같이 작은 규모의 tune_grid를 수행하였습니다.
# Iterative Search를 진행하기 위해서 사전에 resampled performance를 필요로 함
library(doMC)
library(kernlab)
registerDoMC(cores=8)
start_grid <- xgboost_param |> grid_regular(levels=3)
xgboost_initial <- xgboost_workflow |>
tune_grid(resamples = cells_folds,
grid = start_grid,
metrics = metric_set(roc_auc))
xgboost_initial |> autoplot()
이제 준비는 끝났습니다. Iterative Search에는 다양한 방법이 존재하지만, 책에서 소개하는 통계적 기법의 베이지안 최적화(Bayesian Optimization)과 전역 탐색 방법인 시뮬레이티드 어닐링(Simulated Annealing)에 대해 요약하도록 하겠습니다.
1. Bayesian Optimization (베이지안 최적화)
- 하이퍼파라미터 최적화를 위한 순차적 설계 기법
- 이전 평가 결과를 바탕으로 다음 평가할 지점을 "똑똑하게" 선택하는 방법
- [장점] 그리드서치(grid search)나 랜덤서치(random search)보다 효율적으로 최적값을 찾을 수 있음
- [단점] 초기 설정이 복잡하고 계산 비용이 높음
- Peter I. Frazier "A Tutorial on Bayesian Optimization" 참고 (https://arxiv.org/abs/1807.02811)
1-1. Gaussian Process Model (GP Model)
- Bayesian Optimization에 많이 사용되는 모델
- 함수의 분포를 학습하여 데이터가 관측되지 않은 구간에서도 예측할 수 있는 "함수 공간"을 형성하고 적절한 함수가 선택 될 확률분포를 학습
- 적합과정은 아래와 같음
- 커널함수(Kernel Function)을 사용하여 데이터 간의 유사도를 계산한다.
- 유사도를 통해 공분산 행렬을 구한다,
- 가우시안 프로세스 모델에서 특정 값을 예측하기 위해 평균함수와 공분산함수를 사용해 예측 분포를 형성
(평균함수는 예측값의 중심, 공분산함수는 유사도를 나타냄) - 데이터가 주어지면 각 데이터 포인트에서의 함수 값이 어떤 분포(즉, 평균함수의 값, 공분산함수의 값)을 가질 지 계산
(관측된 값이랑 가까운 구간에서는 예측 분산이 작아지는 특징이 있음)
회귀분석이랑 비슷하다고 생각할 수 있습니다. 다만 회귀분석은 잔차가 정규분포를 따른다고 가정하여 사전에 설정한 함수의 형태(일반적으로 직선)을 데이터에 알맞게 적합하지만, GP 모델에서는 데이터가 따르는 함수 자체를 확률 분포로 가정하며 모든 점에서의 함수 값이 정규분포를 따르며 함수의 형태를 유사도를 통해 학습하여 유연한 학습이 가능하다는 차이가 있습니다.
이제 GP모델을 학습시켰으니 어떤 (하이퍼파라미터) 지점에서 성능이 제일 좋을지 예측해야 합니다.
- 첫번째로, 공간 채우기 설계와 같은 방식을 사용해 다양한 값을 가지는 하이퍼파라미터 후보 집합을 생성합니다.
- 두번재로, 후보 집합 각각의 지점에 대해 학습된 GP모델을 적용하여 새로운 점에서의 평균함수의 값와 공분산 함수의 값을 구합니다.
- 마지막으로, 최적의 지점을 찾기 위해서 평균함수와 공분산함수를 사용하는 획득함수(Acquisition function)를 활용합니다.
획득함수(Acquisition function) : 평균함수와 공분산함수 사이의 벨런스를 맞추는 역할
- 평균과 분산의 관계를 통해 과감한 지점과 안전한 지점 사이의 Trade-Off를 조절함
(* 과감한 지점 : 예측된 평균 함수의 값은 낮지만 분산이 커서 신뢰구간의 상한이 잠재적으로 더 높을 파라미터의 값)
(* 안전한 지점 : 예측된 평균 함수의 값이 높고 분산이 작아 안정적인 지점) - 목적은 더 나은 성과지표를 내는 하이퍼파라미터 값을 추천하는 예측 모델의 생성
- 획득함수로는 기대 개선(Expected Improvement, EI)이나 상한신뢰구간(UCB) 등을 사용
- 기대 개선 : $EI(x) = E[\max(f(x) - f(x^+), 0)]$로 $f(x^+)$는 현재까지의 최적값을 의미하며
현재 최적의 함수 값 대비해서 개선 정도를 측정해 개선이 큰 지점으로 샘플링을 유도 - 상한신뢰구간 : $UCB(x) = \mu(x) + \kappa \cdot \sigma(x)$로 $\mu(x),\;\sigma(x)$는 각각 예측 평균과 예측 분산을 의미하며 신뢰구간의 상한이 큰 지점으로 샘플링을 유도
- 기대 개선 : $EI(x) = E[\max(f(x) - f(x^+), 0)]$로 $f(x^+)$는 현재까지의 최적값을 의미하며

1-2. BO(Bayesian Optimization) in tidymodels
tune_bayes 함수 : Bayesian Optimization 적용하여 iterative search 구현
- object : parsnip model specification / 학습되지 않은 workflow 객체
- resamples : 리샘플링 데이터
- objective : Acqusition function (exp_improve, conf_bound, prob_imporve)
- initial : 초기값으로 정수나 tune_grid로 측정된 결과를 사용
- iter : 최대 반복 수 (default = 5)
- [Option] metrics : 성능 평가 측도로 yardstick::metric_set 또는 NULL(default 성과 측도 사용)
- [Option] param_info : dials::parameters / extract_workflow_set_dials 객체
- [Option] control : tune_bayes 함수 사용 시 제어하는 구문으로 control_bayes의 결과를 사용
ctrl_bayes <- control_bayes(verbose = T, no_improve = 7, uncertain = 4, verbose_iter = T)
xgboost_bayesian_optim <-
xgboost_workflow |>
tune_bayes(resamples = cells_folds,
metrics = metric_set(roc_auc),
initial = xgboost_initial,
objective = tune::exp_improve(),
param_info = xgboost_param,
iter = 30,
control = ctrl_bayes)
튜닝을 진행하면 아래와 같이 반복 횟수(Iteration)과 관련된 정보들이 나오며 간략하게 정리했습니다.
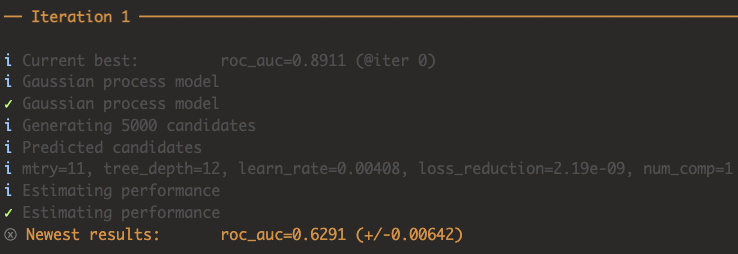
- 현재 최고 성능은 ROC AUC 기준으로 0.8911입니다. (*사전에 제공된 리샘플링 성능에서 최고 성능 지점 기준 (iter 0))
- 5000개의 하이퍼파라미터 후보 셋을 생성합니다.
- GP 모델을 5000개의 지점에 적용하여 평균함수 및 공분산함수의 값을 구하고, 획득 함수를 적용해 성능이 제일 좋을 것이라 기대되는 지점은 (mtry=11, tree_depth=12, learn_rate=0.00408, loss_reduction=2.19e-09, num_comp=1) 입니다.
- 해당 지점의 성능은 ROC AUC 기준으로 0.6291입니다.
tune_grid와 마찬가지로 autoplot이나 show_best, select_best와 같이 유용한 함수를 적용할 수 있습니다.
xgboost_bayesian_optim |> autoplot(type="parameters")
xgboost_bayesian_optim |> autoplot(type="performance")

2. Simulated Annealing (시뮬레이트드 어닐링, SA) - 전역 검색 기법
금속을 다루는 과정에서 영감을 받은 알고리즘입니다. 마치 뜨거운 금속이 천천히 식으면서 강해지는 것처럼 작동합니다.
- "온도"라는 개념을 사용해 탐색 범위를 조절하며 온도가 높은 초기에는 많은 후보를 탐색하지만 시간이 지남에 따라 온도를 낮춰가면서 최적해에 가까운 위치로 수렴
- 높은 온도에서 최적해가 아닐 것 같은 방향으로도 이동할 수 있어서 Local Optimum에 빠지지 않고 넓은 영역을 탐색할 수 있음
( 대신 새로운 지점은 이전 지점에서 크게 벗어나지 않으며 본문에서는 local neighborhood로 표현 ) - 탐색하려는 방향이 나쁜 결과를 내더라도 특정 확률로 해당 방향으로 이동하는 것을 허락함
( 단, 반복될수록 "온도"가 낮아지며 "온도"가 낮아질수록 허락할 확률이 감소함 )
( 또한, 만약 새로운 지점에 대해 성능이 갱신되면 accepted )
$$ \text{Pr[Accept suboptimal paramters at iteration i]}\;= \exp(c \times D_i \times i)$$
여기서 $c$는 상수, $D_i$는 이전 지점과 새로운 지점의 성능 백분율 차이, i는 반복횟수입니다.
또한, 시간이 지남에 따라 반복횟수 i가 커지므로 확률값은 커지는데 이를 random uniform과 비교하여 random uniform의 값이 더 클때, 나쁜 결과를 내더라도 해당 방향으로 탐색하는 것을 허락도록해 시간이 지날수록 나쁜 결과를 내는 방향으로 탐색하는 것을 잘 허락하지 않게 됩니다.
시뮬레이티드 어닐링은 위 설명과 같이 통해 많은 영역을 탐색하고 시간이 지날수록 안정화되며 아래와 같은 특징이 있습니다.
- 결과(=성과 지표)를 얻기 위해 리샘플링 사용
- General nonlinear global search routine으로 불연속적인 함수를 포함하는 다양한 경로를 탐색하며 gradient-based 최적화와 달리 이전 값도 재평가 될 수 있음
- 통계학에서 배우는 최적화 방법들(뉴턴-랩슨, 경사하강법 등)과 비교하면, 시뮬레이팅 어닐링은 더 유연하고 강건한(robust) 방법
2-1. SA(Simulated Annealing) in Tidymodels
tune_sim_anneal( ) function simulated annealing을 통한 iterative search 구현
- object : parsnip model specification / 학습되지 않은 workflow 객체
- resamples : 리샘플링 데이터
- iter : 최대 반복 수 (default = 5)
- initial : 초기값으로 정수나 tune_gird 함수의 결과를 사용
- [Option] metrics : 성능 평가 측도로 yardstick::metric_set 또는 NULL(default 성과 측도 사용)
- [Option] param_info : dials::parameters / extract_workflow_set_dials 객체
- [Option] control : tune_sim_anneal 함수 사용 시 제어하는 구문으로 control_sim_anneal의 결과를 사용
control_sim_anneal의 주요 인자는 아래와 같습니다.
- no_improve(Integer, 최고 성능 점 찾지 못하는 경우 종료)
- restart(Integer, 최고 성능 점 찾지 못하는 경우 이전 최고 점으로 이동)
- radius(numeric vector, local neighborhood 정의)
- cooling_coef가 있다.
library(finetune)
ctrl_simulated_anneal <-
control_sim_anneal(verbose = T,
verbose_iter = T,
no_improve = 25,
restart = 10)
xgboost_simulated_anneal <-
xgboost_workflow |>
tune_sim_anneal(
resamples = cells_folds,
metrics = metric_set(roc_auc),
initial = xgboost_initial,
param_info = xgboost_param,
iter = 50,
control = ctrl_simulated_anneal)
또한, 다른 튜닝 함수와 같이 autoplot, select_best, show_best 등의 유용한 함수를 제공합니다.
xgboost_simulated_anneal |> autoplot(type = "parameters")
xgboost_simulated_anneal |> autoplot(type = "performance")
xgboost_simulated_anneal |> autoplot(type = "marginals")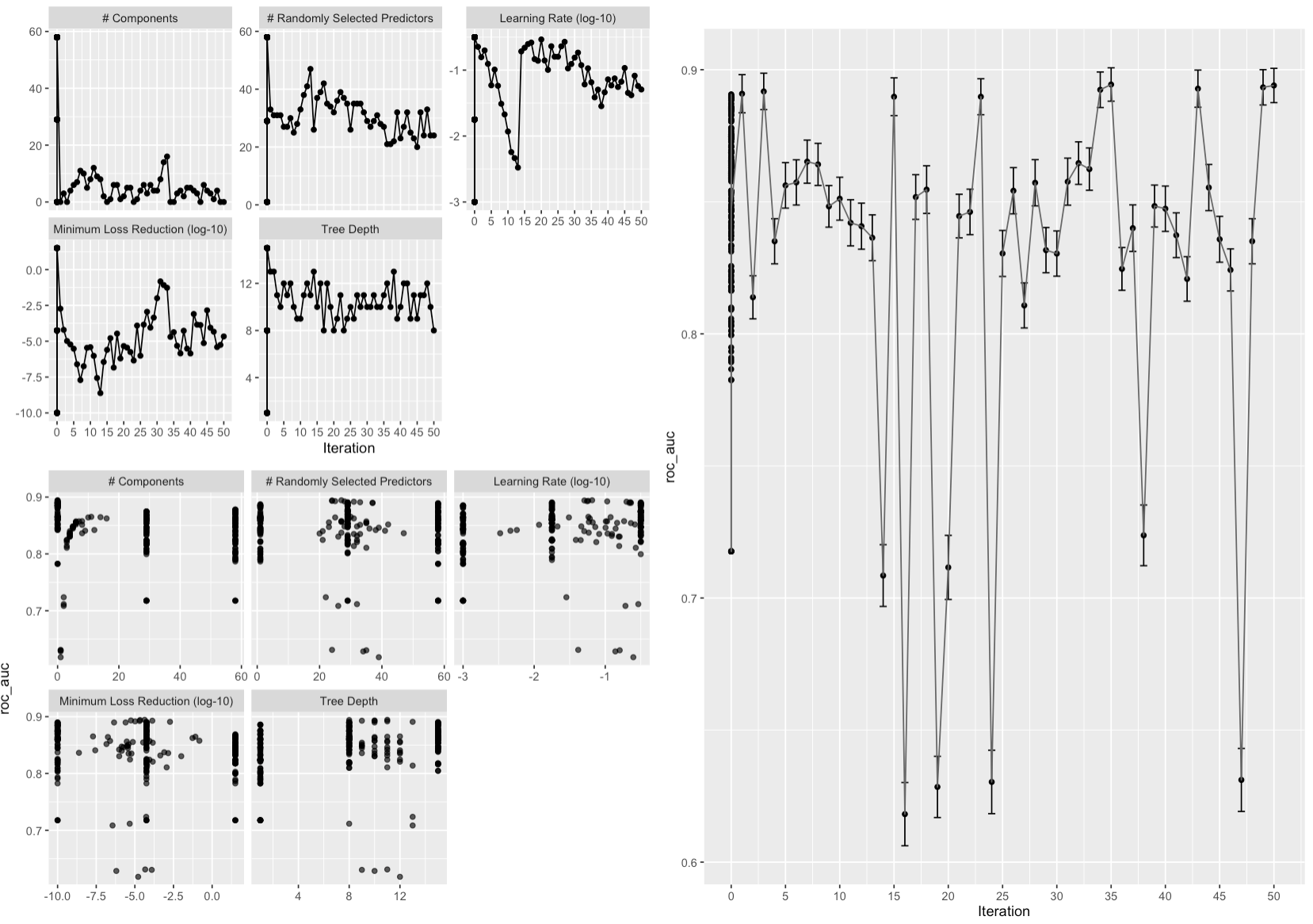
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 16. 차원 축소(Dimensionality Reduction) (2) | 2024.01.07 |
|---|---|
| [Tidy Modeling with R] 15. Many Models with Workflow sets (0) | 2024.01.01 |
| [Tidy Modeling With R] 13. Grid Search with XGBoost (2) | 2023.12.22 |
| [Tidy Modeling with R] 12. 하이퍼파라미터 튜닝 (0) | 2023.10.11 |
| [Tidy Modeling with R] 11. Model Comparison (모델 비교) (0) | 2023.10.09 |