0. 개요
안녕하세요. 이전에 공부한 내용을 복습할 겸 이전 포스팅에 오류가 있는지 확인하느라 시간이 좀 걸렸네요.
하여튼 이번 포스팅에서는 기술통계량과 통계에서 사용하는 탐색적 데이터 분석에 대해 알아보도록 하겠습니다.
챕터가 올라갈수록 개념도 점점 어려워지고 수식도 많아지는 경향이 있는데, 개인적으로 챕터6이 최고점이지 않을까 싶습니다.
또한, 이후 챕터에서는 챕터 6의 내용이 중요하기 때문에 잘 따라와주세요.
챕터 6에서 처음으로 포스팅 할 내용은 기술통계량과 탐색적 데이터 분석 파트입니다.
통계는 수식을 통해 결론을 도출하는 점에서 데이터 분석에서 많이 사용되지만, 데이터의 이해를 높이기 위해 데이터의 분포를 확인하는 시각화 또한 중요합니다. 예를 들어, 팀에서 연간 사용자 수를 분석하기로 했는데 분기별로 14932명, 29341명, 25932명, 59823명 이렇게 숫자로 쓰여있으면 한눈에 추세를 파악하기 힘들지만 그래프를 통해서 표현하면 데이터의 추세를 단번에 파악할 수 있다는 이점이 있습니다.
챕터 2와 챕터 3에서 언급한 것 처럼 변수에는 이산형변수(Discrete Variable)과 연속형변수(Continuous Variable) 두 가지로 분류할 수 있습니다. 이산형변수는 셀 수 있는 표본공간(Sample Space)를 가지고 있으므로 각 값에 따른 빈도수를 사용해서 시각화 할 수 있을 것 입니다. 반면에 연속형변수는 구간(Interval)을 표본공간(Sample Space)로 가지고 있으며 개별값이 나올 확률을 0으로 정의하고 있어서 이산형변수와 같이 시각화하기는 어려움이 있습니다. 따라서 히스토그램이라는 시각화 기법을 많이 사용하는데요. 히스토그램은 연속형 변수의 값을 그룹화하여 시각화하는 방식으로 아래와 같은 방법으로 그릴 수 있습니다.
1. Histogram 생성하는 방법
- 연속형 변수의 관측값의 범위(R) = Maximum - Minimum과 관측수(n)을 고려하여 몇 개의 구간으로 나눌지 결정한다.
- K개의 구간으로 나누기로 했으면 구간끼리 겹치지않고 최솟값과 최댓값이 첫 구간과 마지막 구간에 포함될 수 있도록 길이를 조정한다.(일반적으로 구간의 길이는 동일하게 둡니다)
- 각 구간별로 관측값의 수($f_i$)와 중간점(Midpoint)를 구한다.
- 구간 별 관측값의 수($f_i$)를 사각형의 높이로 하고, 각 구간의 경계를 사각형의 밑변으로 하는 사각형을 구간별로 그린다. (관측수가 아닌 비율 $\frac{fi}{\sum_{i=1}^{k} f_i}$로 할 수 있다.
* 이때, 상대 빈도 히스토그램(Relative Frequency Histogram)은 히스토그램에 높이에 해당되는 관측값의 수를 $h_i = \frac{f_i}{\sum_{i=1}^{k} f_i} / (구간의 길이)$로 하여 구할 수 있다. (넓이의 합이 1이 되도록 하기 위함)
* 상대 빈도 폴리곤(Relative Frequency Polygon)은 구간의 길이가 같은 상대 빈도 히스토그램에서 (Midpoint, $h_i$)을 직선으로 연결해서 그릴 수 있다.
히스토그램은 ggplot의 래퍼로 아래와 같이 작성할 수 있으나.... Base함수 hist, ggplot2::geom_histogram을 사용하면 편리합니다.
draw_histogram_ggplot2 <- function(data, bins){
diff_range <- function(data){
rng <- range(data)
return (rng[2] - rng[1])}
data <- data[is.finite(data)]
n <- length(data) # finite data's number
if(n<bins){bins <- n}
y1 <- min(data)
yn <- max(data)
len = diff_range(data) / bins
class <- seq(min(data), max(data), by=len)
group <- cut(data, class, include.lowest = T)
p <- tibble(data=data, group=group) %>%
count(group) %>%
ggplot(mapping=aes(x=group, y=n)) + geom_col() +
labs(x = substitute(data), y = "Observation")
print(p)
}
draw_histogram_ggplot2(data=iris$Sepal.Length, bins=10)
draw_histogram_ggplot2(data=iris$Sepal.Length, bins=30)
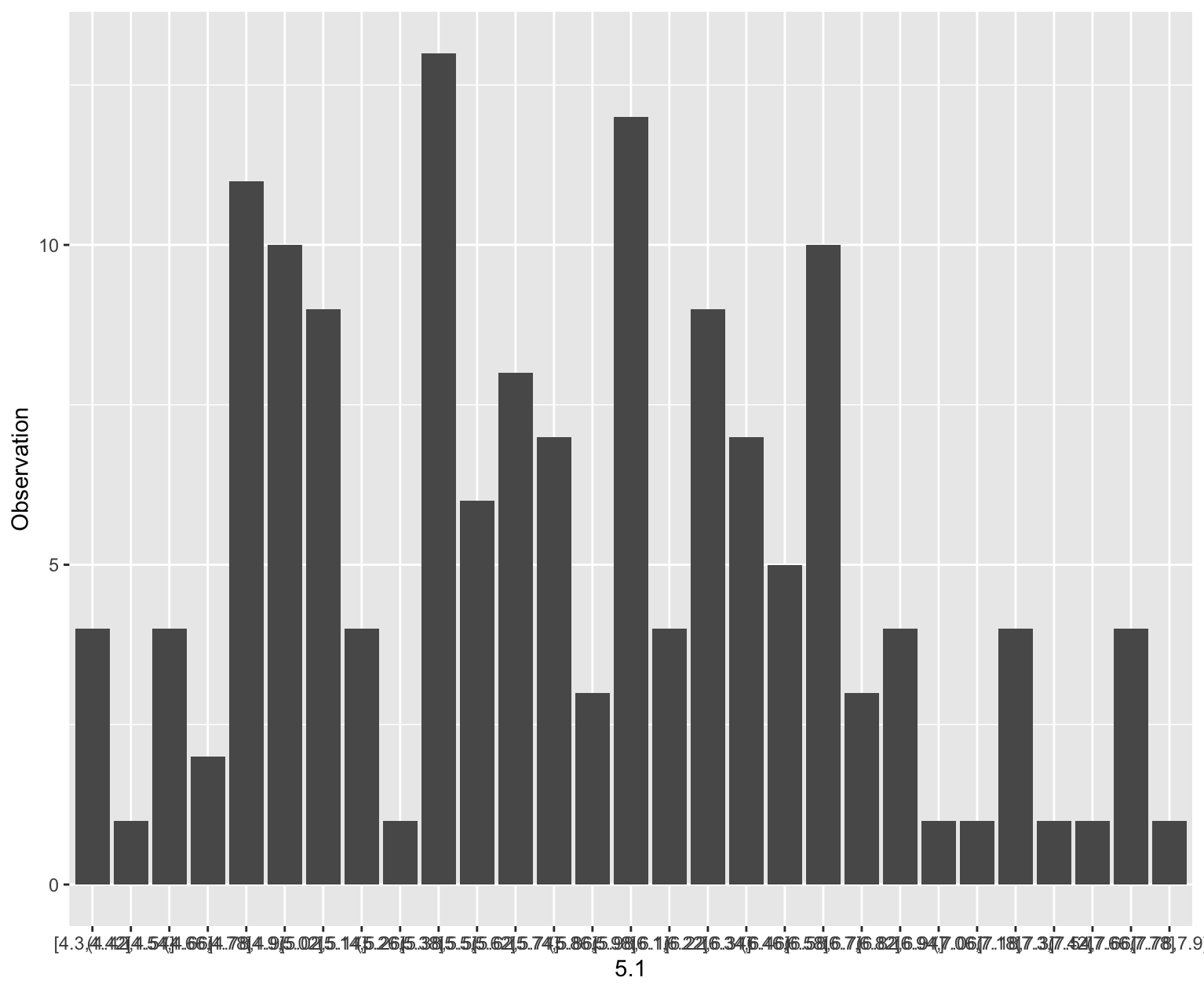
2. 경험적 분포(Empirical Distribution)
특정 실험을 n회 수행하서 얻은 관측값 $x_1, x_2, \cdots, x_n$을 확률분포의 Sample(표본)이라고 생각할 수 있으며, 인공적으로 각 관측이 일어날 확률이 $\frac{1}{n}$인 확률분포를 만들면 경험적 분포(Empirical Distribution)이라고 말합니다.
또한 경험적 분포에서의 평균, 분산을 표본평균, 표본분산이라고 말합니다.
- 표본평균(Sample Mean) : $\overline{x} = \frac{\sum_{i=1}^{n} x_i}{n}$
- 표본분산(Sample Variance) : $s^2 = \frac{\sum_{i=1}^{n} (x_i-\overline{x})^2}{n-1}$
Empirical Rule은 $x_1, x_2, \cdots, x_n$이 표본평균 $\overline{x}$, 표본분산 $s^2$일때, 분포의 형태가 종모양이고 표본의 수가 많은 경우 대해 다음이 근사적으로 성립합니다.
- $(\overline{x}-s, \overline{x}+s)$ 범위에 전체 데이터의 대략 68%가 포함되어 있다.
- $(\overline{x}-2s, \overline{x}+2s)$ 범위에 전체 데이터의 대략 95%가 포함되어 있다.
- $(\overline{x}-3s, \overline{x}+3s)$ 범위에 전체 데이터의 대략 99.7%가 포함되어 있다.
3. 줄기-잎 그림(Stem and Leaf Plot)
또한, 히스토그램에서는 데이터의 값이 그룹화된 값으로 대체되어 정보를 손실하는 단점이 있어 줄기-잎 그림(Stem and Leaf plot)을 통해 본래의 값을 잃지 않으면서 분포의 형태를 파악할 수 있습니다. R에서는 stem 함수를 사용해서 시각화 할 수 있습니다.
stem(iris$Sepal.Length)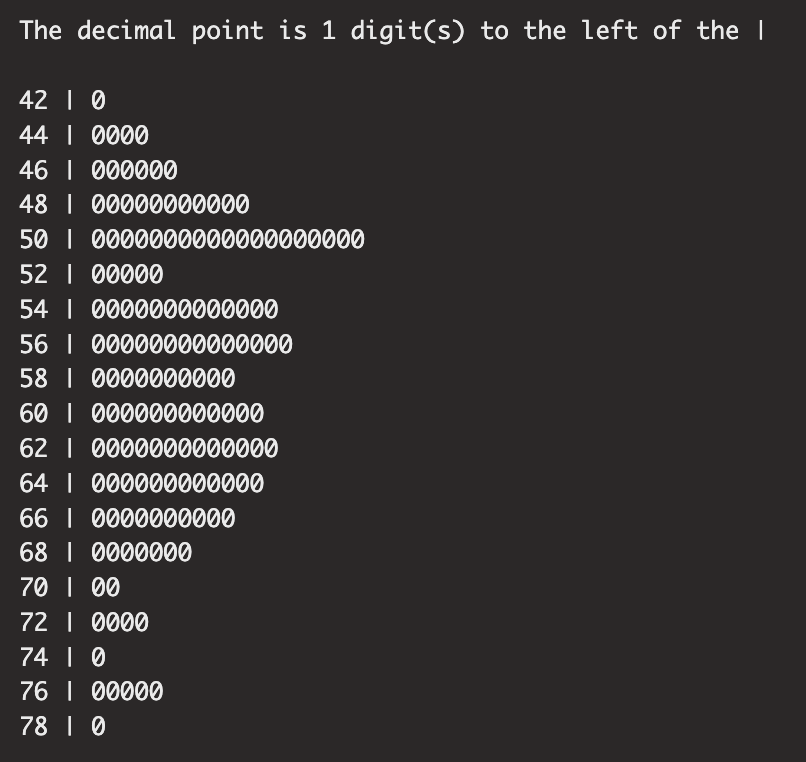
4. Sample Percentile(표본 백분위수)
기호로는 $\tilde{\pi_p}$인 표본 백분위 수(100pth sample percentile)에 대해서 알아볼건데요.
$x_1, x_2, \cdots, x_n$ 표본이 있으면 관측치를 작은값부터 큰값까지 크기 순대로 정렬하여 $y_1 = Min(x_1, x_2, \cdots, x_n) < y_2 < \cdots < y_n = Max(x_1, x_2, \cdots, x_n)$와 같이 만들어줍니다.
여기서 백분위 수는 정렬된 표본을 100등분을 했을 때, 대략 100p번째 관측치를 의미합니다.
따라서 p가 0에 가까울 수록 작은 관측치를 의미하고, p가 1에 가까울수록 표본에서 큰 관측치를 의미하게 됩니다.
그러므로 n개의 표본이 있다고 가정하면 대략 np개의 관측치가 $\tilde{\pi_p}$보다는 작고, n(1-p)개의 관측치는 $\tilde{\pi_p}$보다 커야하겠죠.
좀 더 정확하게 표본 백분위 수를 구하는 방법은 $r=(n+1)p$를 구하고 $r$이 정수라면 $y_r$을, $r$이 정수가 아니라면 $y_r$과 $y_{r+1}$의 가중평균을 구해서 얻을 수 있습니다.
이런 표본 백분위 수는 당연하게도 표본 사분위 수와 연관시킬 수 있는데요.
$p=0.25$인 제 25백분위수($\tilde{\pi_{0.25}}$) 같은 경우에는 1사분위수와 같으며, $p=0.5$인 제 50백분위수($\tilde{\pi_{0.25}}$) 같은 경우에는 2사분위수나 중위수, $p=0.75$인 제 75백분위수($\tilde{\pi_{0.75}}$) 같은 경우에는 3사분위수와 같습니다.
- $\tilde{\pi_{0.25}} = \tilde{q_1}$
- $\tilde{\pi_{0.5}} = \tilde{q_2} = \tilde{m}$
- $\tilde{\pi_{0.75}} = \tilde{q_3}$
또한 IQR(Interquartile Range)라고 해서 $\tilde{q_3} - \tilde{q_1}$ = $\tilde{\pi_{0.75}} - \tilde{\pi_{0.25}}$로 계산되며 3사분위수와 1사분위수의 차이로 계산할 수 있습니다.
아래 예시를 참고하면 이해하는데 도움이 될 듯 합니다.

5. 박스플롯(Box-Plot)
수치형변수의 분포를 파악하고자 할때 효과적인 박스플롯은 5개의 통계량을 포함하는 Five-number summary를 통해 그릴 수 있습니다.
Five-number summary는 최소값, 1사분위수, 중앙값, 2사분위수, 최대값으로 구성되어 있습니다. 아래 그려진 박스플롯에서 상자에서 가장 왼쪽이나 부분은 1사분위수이며, 가장 오른쪽이에 있는 부분은 3사분위수입니다. 박스 가운데 그려진 부분은 중앙값을 의미합니다. 함수에 따라 다른점이 있지만 R에서는 분위수에서 1.5*IQR이내에 있는 최솟값과 최댓값을 수염의 끝으로 설정합니다.
data <- iris$Sepal.Length
fivenum(data) # 4.3 5.1 5.8 6.4 7.9
boxplot(data, outline = T, horizontal = T, col = "skyblue")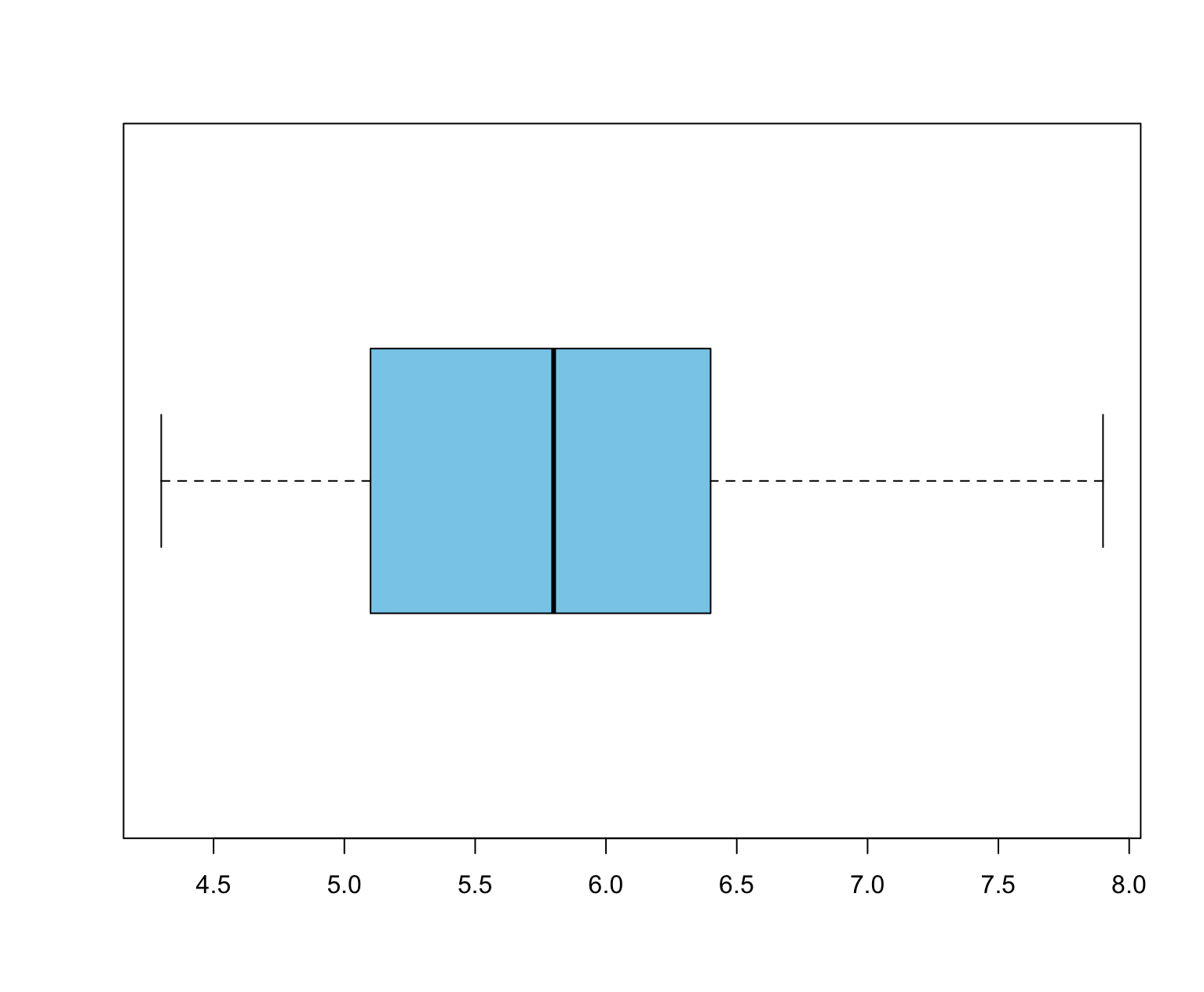
참고사항
1. 히스토그램의 구간의 너비가 너무 넓으면 확률 분포 형태의 많은 정보를 제공하지 않고, 너무 좁으면 빈도가 0인 구간이 많이 발생하고 데이터에 과적합 하는 경향을 보이므로 적당한 구간 선택이 중요
2. 히스토그램은 확률분포함수의 샘플링으로 생각할 수 있으며 그러므로 확률분포함수의 추정치로 생각될 수 있다.
3. 잘 작동하는 근사적인 확률 모델은 아래와 같다. (단, $p(i)$는 데이터가 구간 i에 속할 확률, $N_i$는 구간 i에 속한 데이터의 수, $i(x)$는 임의의 $x$에 대해 구간 $i$를 반환하는 함수)
$$p(i) = \frac{N_i + \alpha}{\sum_{k}[N_k + \alpha]} \quad and \quad \tilde{f(x)} = \frac{p(i(x))}{{\Delta_{i(x)}}}$$
4. Jackknife log - likelihood L은 아래와 같다. (잭나이프는 LOO-CV와 비슷하게 작동)
$$ L = \sum_{i} N_i ln(\frac{N_i + \alpha - 1}{{\Delta_{i}}[\sum_{k}(N_k + \alpha) - 1]}) $$
Hogg, D. W (2008) Choosing the binning for a histogram
5. 좋은 히스토그램 모델 $h(x)$는 실제 underlying PDF $f(x)$에 대해 $\int(h(x)-f(x))^2dx$를 최소하는 모델을 선택
6. 데이터가 정규분포를 만족할때, 히스토그램의 구간 길이를 $3.49sn^{-\frac{1}{3}}$으로 할 것으로 제안
(출처 D. W. Scott, On optimal and data-based histograms, Biometrika 66 (1979), 605–610.)
'Statistics > Mathmetical Statistics' 카테고리의 다른 글
| [확률과 통계적 추론] 6-3. Maximum likelihood Estimation (최대가능도추정) (0) | 2024.02.13 |
|---|---|
| [확률과 통계적 추론] 6-2. 순서통계량(Order Statistics) (1) | 2024.02.08 |
| [확률과 통계적 추론] 5-8. Chebyshev's Inequality (체비쇼프 부등식) (0) | 2024.01.21 |
| [확률과 통계적 추론] 5-7. 연속성 수정 (Continuity Correction) (0) | 2024.01.20 |
| [확률과 통계적 추론] 5-6. 중심극한정리(Central Limit Theorem) (0) | 2024.01.19 |