저번 포스팅에서는 텐서플로를 이용한 회귀분석과 실습을 해보았는데요!
이번에는 종속변수가 수치형이였던 회귀와는 조금은 다른 분류에 대해서 포스팅하려고 합니다.
실생활에서는 서류를 정리하거나 합격자/불합격자의 명단을 나눌때 분류라는 단어를 사용하죠.
이와 유사하게 분류는 무엇을 특정한 기준에 따라 나누는 것을 의미하는데요.
데이터 사이언스에서는 특정한 기준이 몇개인지에 따라 분류를 이항분류와 다항분류로 구분합니다.
이항분류는 기준이 2개로 어떤 사진이 주어졌을 때 이 사진이 고양이사진인지 강아지사진인지 구분하는 것을 의미합니다.
사진을 여러개 주여져도 무조건 고양이나 강아지 사진으로 분류하지 범고래 사진이라고 분류하지 않아요!
반면에 다항분류는 기준이 여러개로 어떤 사람이 쓴 숫자가 0~9 중 어떤 숫자인지를 구분할때 사용합니다!

분류는 머신러닝 및 딥러닝으로 구축할 수 있고 구축된 모델로 이산형인 자료(discrete-valued quantity)인 y값을 예측하는데 사용할 수 있습니다.
유명한 예로는 캐글에서 다양한 변수와 유방암 여부를 주고 새로운 데이터가 주어졌을 때 이 사람이 유방암인지 아닌지를 구분하는 대회가 있었습니다.
- Input Feature : $ x ^{(i)} \in R ^{n} $, i = 1, ... ,m
- output Feature : $ y^{(i)} \in Y $, i = 1, ..., m
이번에는 와인 데이터셋을 사용하여 분류를 진행하겠습니다.
URL을 변수로 저장하여 pd.read_csv를 활용해 불러왔습니다. 목표는 레드와인과 화이트와인을 다른 변수를 활용해 분류하는 모델을 만드는 것인데 레드와인과 화이트와인 데이터가 따로 있어서 type이라는 변수를 새로 만들어 레드와인에는 0, 화이트 라인에는 1이라는 값을 입력하였습니다.
import pandas as pd
import numpy as np
import tensorflow as tf
redWineURL = "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
whiteWineURL = "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv"
red = pd.read_csv(redWineURL, sep=";"); red['type'] = 0
white = pd.read_csv(whiteWineURL, sep=";"); white['type'] = 1
wine = pd.concat([red, white])
print(wine.shape)
print(wine.head())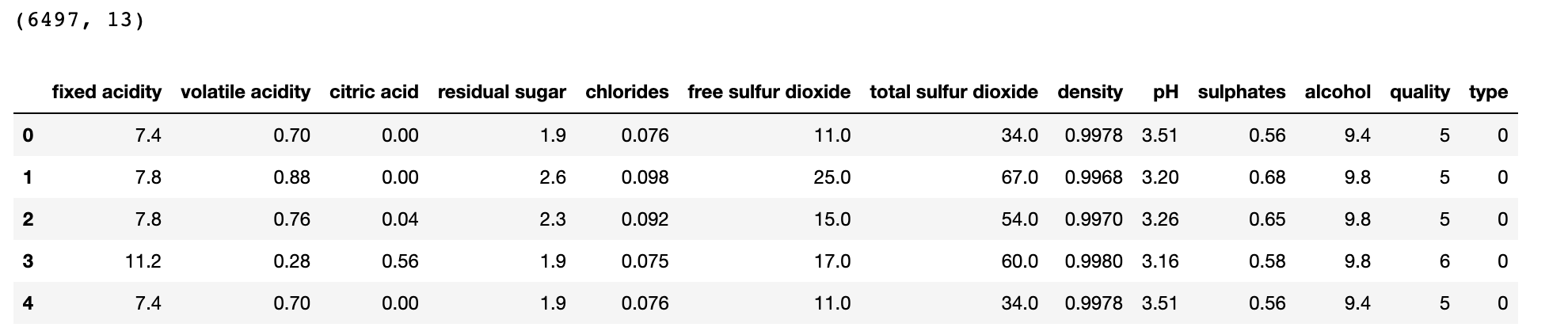
- 전체데이터는 6497개이며 변수는 13개가 있는 것을 확인할 수 있습니다
- pd.concat([df1, df2])를 사용하여 df1과 df2를 하나의 데이터프레임으로 만들었습니다.
wine.info()
- 메모리는 710KB를 사용하고 있으며 12개의 변수 모두 NULL값이 없는 것을 확인할 수 있습니다.
wine.describe()
- 간단하게 변수들의 분포 요약을 살펴보겠습니다. 일부값들이 평균으로부터 멀리 떨어져 있는 것으로 보입니다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
sns.boxplot(data=wine, orient="h")
- 그래프에서 점으로 찍힌 데이터는 IQR Rule 관점에서 이상치로 판단할 수 있으나 이상치에 덜 민감한 딥러닝 방식에서는 따로 전처리 진행하지 않겠습니다.
- 각 변수들을 보면 규모의 차이가 존재하므로 딥러닝 학습전에 Normalization (or Standardization)을 진행해야 합니다.
# independence variable visualization
fig, axs = plt.subplots(ncols=6, nrows=2, figsize=(25,15))
index = 0
axs = axs.flatten()
for val_name, val_data in wine.items() :
sns.histplot(data=wine[val_name], ax=axs[index])
index = index + 1
if index == 12 :
break
plt.tight_layout(pad=20, w_pad=2, h_pad=2)
- density 변수와 같이 일부 변수에서 극단치 혹은 이상치가 존재하는 것으로 보입니다.
- quality 변수는 연속형변수가 아닌 순서형(Ordinal) 데이터로 보입니다.
다음으로 종속변수 Y의 데이터 분포를 살펴보겠습니다.
# target variable visualization
sns.countplot(data=wine, x="type")
plt.show()
print(wine["type"].value_counts())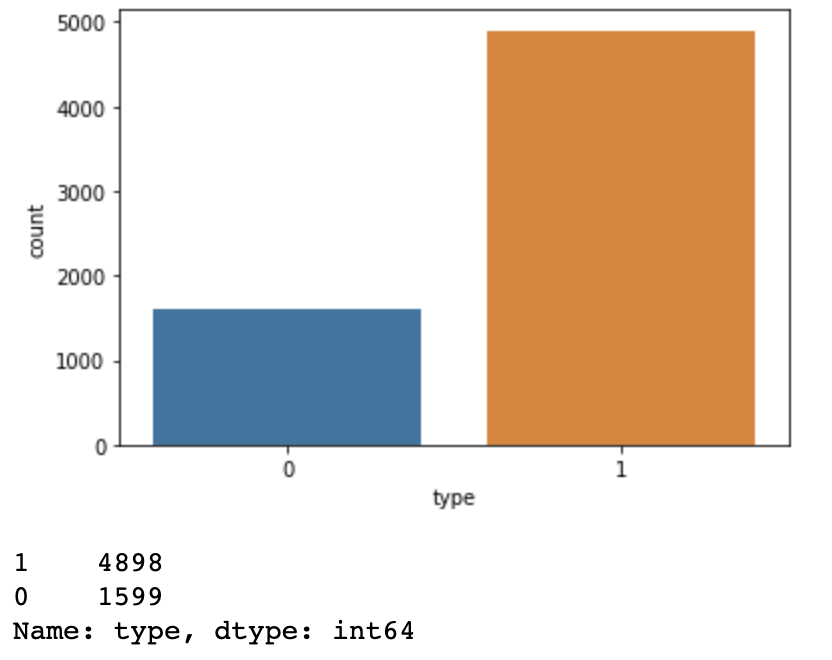
- 0(레드와인)과 1(화이트와인)이 1:3 정도의 비율을 보이고 있습니다.
- 종속변수가 클래스 불균형인것을 조심하여야 합니다. 이는 모델을 학습할때 한쪽의 데이터만 학습이 되는것으로 모델의 성능을 저하시키며 두 유형 모두 적절하게 학습이 되어야합니다. 주로 의료데이터에서 클래스-불균형이 많으며 와인 데이터는 1:3 정도로 문제가 되지 않기 때문에 과소표집 혹은 과대표집을 진행하지 않았습니다.
앞서 언급한 데이터 분포를 보면 변수들간 규모의 차이가 존재해서 Normalization을 진행하였습니다.
preprocessing.MinMaxScaler()를 사용하여 데이터 정규화를 진행하였으며 StandardScaler()를 사용하여 표준화를 하셔도 좋습니다.
두 Scaler 모두 적합(fit)하고 변형(transform)하는 과정이 필요합니다.
from sklearn import preprocessing
sc = preprocessing.MinMaxScaler().fit(wine)
wine_normal = sc.transform(wine)
- Normalization을 진행한 후 모든 데이터가 [0, 1]에 위치하는 것을 확인할 수 있습니다.
모델을 학습시키려면 데이터를 학습데이터와 훈련데이터로 구분해야 정확하게 판단할 수 있습니다.
원래는 Train, Validation, Test 데이터로 구분하여야 하나 딥러닝 네트워크 구축 후, 학습 시 Train 데이터의 일부를 Validation 데이터로 사용하므로 Train 데이터와 Test 데이터 두 부분으로 나눠도 무관합니다.
이때 sklearn.model_selection 에서 train_test_split 메서드를 이용하였습니다.
from sklearn.model_selection import train_test_split
X = wine_normal[:, :-1]
Y = wine_normal[:, -1]
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2)
train_y과 test_y는 정답을 담은 변수로 0 또는 1로 이루어져 있는데요, 딥러닝에서 쉽게 학습할 수 있도록 데이터를 변형해야 합니다.
즉 2가지 범주가 있으므로 정답이 0일때는 [1, 0]으로, 정답이 1일때는 [0,1]로 바꿔야합니다.
이때 tensorflow.keras.utils의 to_categorical 함수를 이용하였습니다.
train_y = tf.keras.utils.to_categorical(train_y, num_classes=2)
test_y = tf.keras.utils.to_categorical(test_y, num_classes=2)
모델을 구축하는 코드입니다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation="relu", input_shape=(12,)),
tf.keras.layers.Dense(units=32, activation="relu"),
tf.keras.layers.Dense(units=16, activation="relu"),
tf.keras.layers.Dense(units=2, activation="softmax")])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.05),
loss = tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.summary()- 4개의 레이어를 사용하였으며 활성화함수로는 ReLU를 사용하였습니다. input_shape는 입력데이터의 수로 train_x의 열의 수와 동일하게 작성해야 합니다.
- 마지막 레이어에서는 유닛의 수가 2개인데 이는 정답이 0일때는 [1,0], 정답이 1일때는 [0,1]의 두 가지의 값으로 나와야 하기 때문입니다.
- 활성화함수로 softmax를 사용했는데 [a, b]라는 출력값이 나왔을 때, [$e^a/(e^a + e^b)$, $e^b/(e^a+e^b)$]로 나타냅니다. 큰 값을 강조하고 작은 값을 약화하는 효과가 있습니다.
- 손실함수로는 categorical_crossentropy를 사용했는데요, 분류 태스크에서 많이 사용하는 손실함수 입니다.
모델을 구축한 후 데이터를 이용하여 모델을 학습시켰습니다. 이때 검증데이터로 20%를 사용하였습니다. 반복수는 50 번입니다.
history = model.fit(train_x, train_y, epochs=50, batch_size=128, validation_split=0.2,
callbacks=[tf.keras.callbacks.EarlyStopping(patience=5, monitor="val_loss")])
- 반복수는 50번이나 19번에 학습이 끝났는데 이는 과적합을 방지하는 EarlyStopping을 사용하였기 때문입니다.
- 훈련 정확도는 99.16%, 검증 정확도는 99.04%인 모습을 보입니다.
학습 횟수에 따른 손실 및 정확도를 시각화하였습니다.
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.plot(history.history['loss'], "b-", label="loss")
plt.plot(history.history["val_loss"], "r--", label="val_loss")
plt.xlabel("Epoch")
plt.legend()
plt.subplot(1,2,2)
plt.plot(history.history["accuracy"], "b-", label="acc")
plt.plot(history.history["val_accuracy"], "r--", label="val_acc")
plt.xlabel("Epoch")
plt.legend()
plt.show()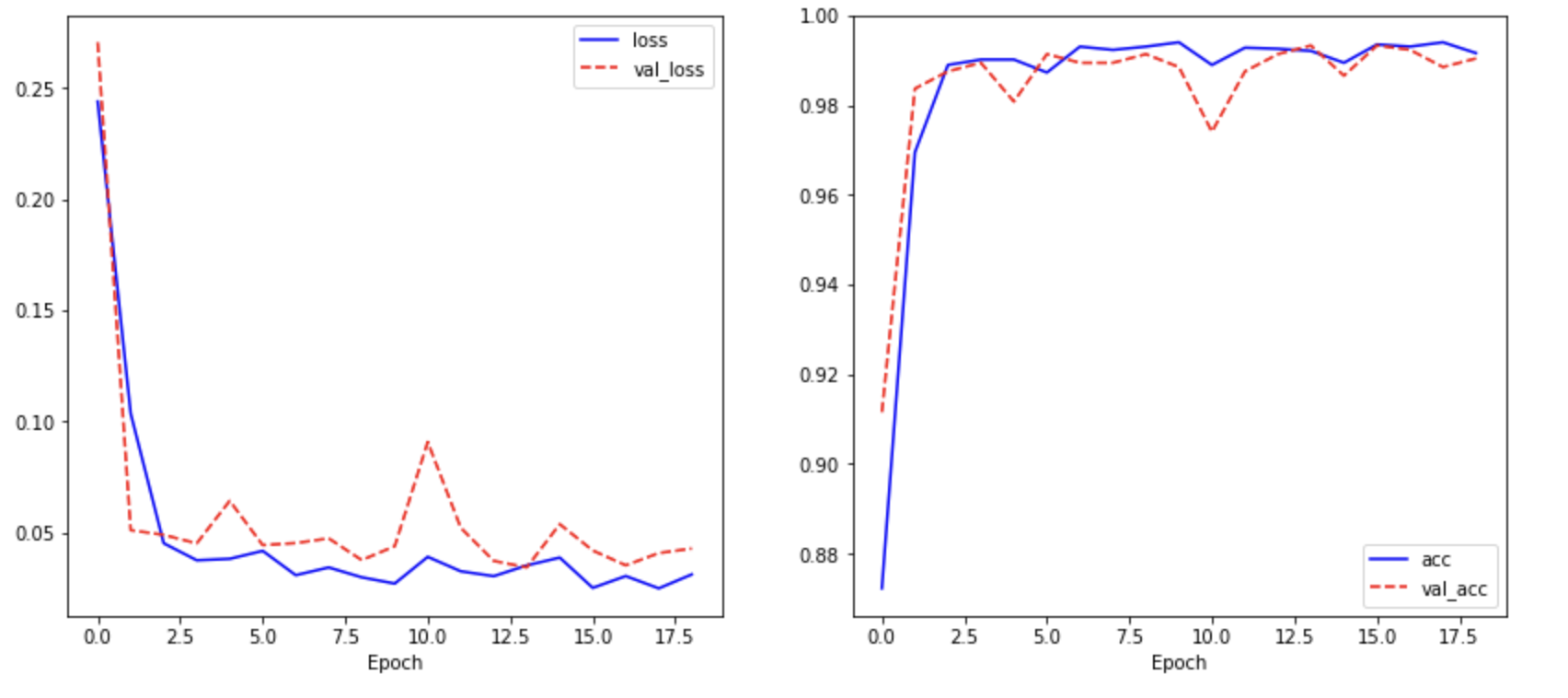
학습된 모델에 새로운 데이터인 test 데이터를 사용해 평가하였습니다.
model.evaluate(test_x, test_y)
- 손실은 0.0285, 정확도는 99.31%를 보였습니다.
마지막으로 잘 분류가 되었나 확인하기 위해 혼동행렬(Confusion Metrix)를 구해봤습니다.
혼동행렬은 모델의 성능을 평가할 때 사용합니다.
from sklearn import metrics
pred = model.predict(test_x, verbose=0)
pred = pred.argmax(axis=-1)
real = test_y.argmax(axis=-1)
confusion_matrix = metrics.confusion_matrix(real, pred)
print(confusion_matrix)
- 284 : 레드와인(0)을 레드와인이라고 예측한 경우
- 3 : 레드와인(0)을 화이트화인이라고 예측한 경우
- 6 : 화이트와인(1)을 레드와인이라고 예측한 경우
- 1007 : 화이트와인(1)을 화이트와인이라고 예측한경우
- 정확도(Accuracy) : (284+1007) / (284+3+6+1007) = 0.9931
'AI > Deep Learning' 카테고리의 다른 글
| [밑시딥1] 챕터 5~8 요약 (0) | 2023.03.26 |
|---|---|
| [밑시딥1] 챕터 1~4 요약 (0) | 2023.03.26 |
| [Tensorflow] 2-1 Regression with Boston housing datasets (0) | 2023.01.07 |
| [Tensorflow] 2. 회귀(Regression) (0) | 2023.01.05 |
| [Tensorflow] 1. 논리연산을 위한 신경망 네트워크 생성 (0) | 2023.01.04 |