저번에는 인공신경망과 간단한 코드를 사용해 논리연산자를 구현해보았는데요.
이번에는 본격적으로 회귀에 대해서 포스팅 해보려고 합니다.
"과거로 회귀하다"와 같은 말처럼 회귀(Regression)은 제자리로 돌아오거나 돌아간다는 의미를 가지고 있는데요.
도대체 무엇으로 어떻게 돌아간다는 의미일까요?? 🧐
이는 프랜시스 골턴이라는 유전학자가 아버지의 키가 크면 자식도 평균보다 크지만 아버지 만큼 크지 못하다는 사실을 발견하고
"평균으로 회귀(Regression)"라는 개념을 설명하면서 알려지게 되었습니다.
현재는 하나 이상의 독립변수($X$)와 독립변수에 영향을 받는 종속변수($Y$)의 관계를 분석하는 것을 회귀분석이라고 합니다.
앞선 예시에서는 아버지의 키로 자식의 키를 분석했기에 아버지의 키를 독립변수($X$), 아들의 키를 종속변수($Y$)로 볼 수 있습니다.
독립변수는 예측변수, 설명변수, 피쳐(Feature)라고도 불리며 머신러닝 및 딥러닝에서는 입력값으로 들어가게 됩니다.
이와 유사하게 종속변수는 독립변수에 영향을 받는 변수로 머신러닝과 딥러닝에서는 출력값으로 사용합니다.
회귀분석에는 다양한 종류가 있는데 2가지만 소개하려고 합니다!
- $Y = aX + b$ : 단순회귀분석(Simple Linear Regression)
- $Y = a_1X_1 + a_2X_2 + \cdots + a_nX_n + b$ : 다중회귀분석(Multiple Regression Analysis)
회귀분석을 통해 독립변수와 종속변수의 관계를 유추하거나 예측등에 사용할 수 있습니다.
통계학과에서 "회귀분석"이라는 과목 자체를 배우기도 하며 머신러닝중 회귀를 앞부분에 배울 만큼 중요합니다
참고로 아래 코드는 [시작하세요! 텐서플로 2.0 프로그래밍]의 예제를 중심으로 코드 재구성 하였습니다.
여기서는 인구증가율과 고령인구비율이 얼마나 차이가 있는지 알아보려고 합니다.
이때 인구증가율을 독립변수 X로 사용하였고 인구증가율이 변할때 고령인구비율의 변화를 살펴볼 것이므로 고령인구비율을 Y로 두겠습니다.
import matplotlib.pyplot as plt
import numpy as np
population_inc = np.array([0.3, -0.78, 1.26, 0.03, 1.11, 15.17, 0.24, -0.24, -0.47, -0.77, -0.37, -0.85, -0.41, -0.27, 0.02, -0.76, 2.66])
population_old = np.array([12.27, 14.44, 11.87, 18.75, 17.52, 9.29, 16.37, 19.78, 19.51, 12.65, 14.74, 10.72, 21.94, 12.83, 15.51, 17.14, 14.42])
plt.scatter(population_inc, population_old)
plt.xlabel("Population Growth Rate (%)")
plt.ylabel("Elderly Population Rate (%)")
plt.show()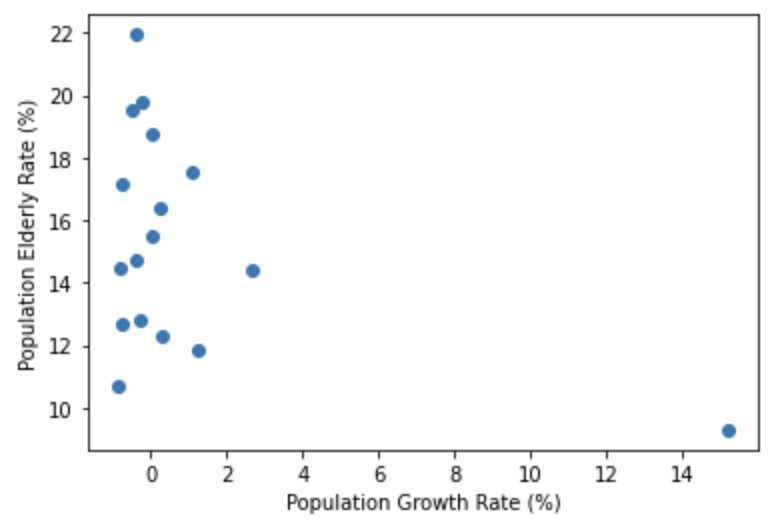
자료를 시각화 하였을때 우측하단에 보이는 점은 다른 데이터와 많이 동떨어져 보이네요.
따라서 이상치(Outlier)로 판단하여 제거하고 전후 데이터의 분포를 살펴보았습니다.
index = population_inc < 10
population_inc_clean = population_inc[index]
population_old_clean = population_old[index]
# 전처리 전후 데이터 플롯 시각화
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.scatter(population_inc, population_old, c="b")
plt.xlabel("Population Growth Rate (%)")
plt.ylabel("Elderly Population Rate (%)")
plt.title("Scatter Plot before Cleansing")
plt.xlim(-2,16)
plt.subplot(1,2,2)
plt.scatter(population_inc_clean, population_old_clean, c="r")
plt.xlabel("Population Growth Rate (%)")
plt.ylabel("Elderly Population Rate (%)")
plt.title("Scatter Plot after Cleansing")
plt.xlim(-2,16)
plt.show()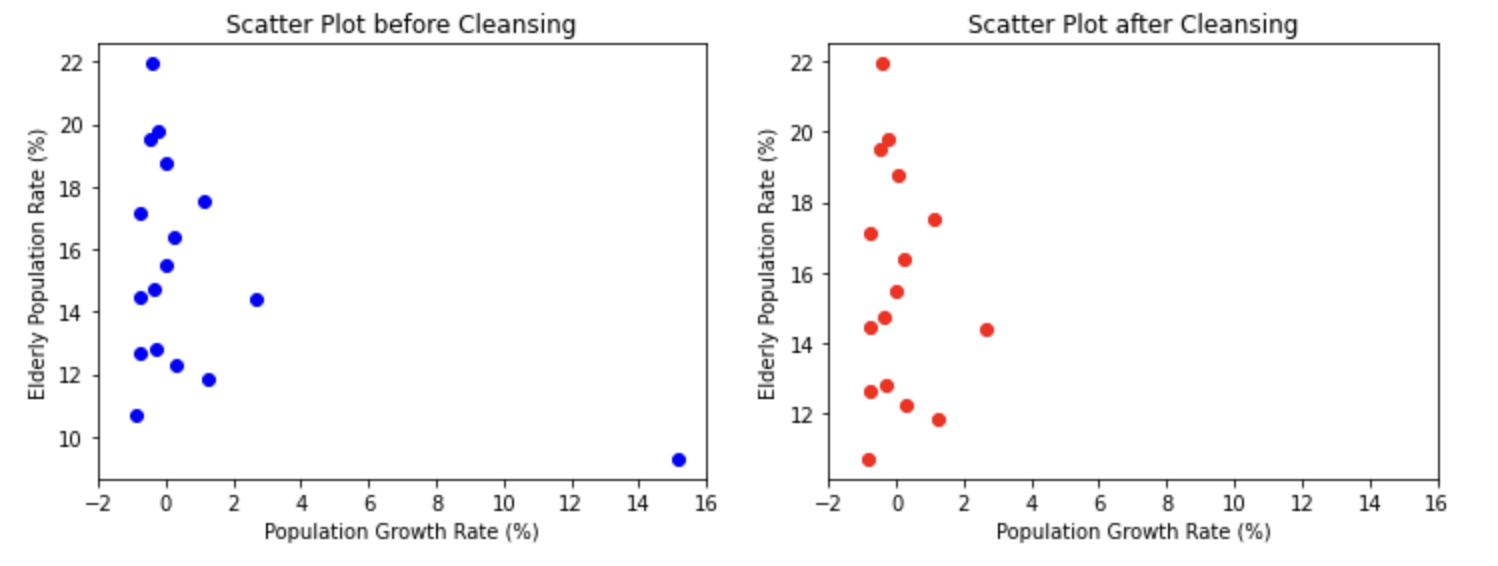
파란색으로 보이는 그래프가 전처리 전이고 빨간점이 있는 그래프가 전처리 후입니다.
전처리한 데이터가 좀더 깔끔하고 경향성이 확실하게 보이네요!
1. 최소제곱법을 사용한 단순회귀분석(Simple Linear Regression Analysis)
$Y=a*X + b$로 나타낸 직선이 모델링 한 것이고 이 모델에서 기울기에 해당하는 a와 절편에 해당하는 b를 구하는것이 목표입니다.
다양한 방법으로 구할 수 있으나 a와 b를 최소제곱법(Least Squared Method)에서는 다음과 같이 구할 수 있습니다.
$$a = \frac{\sum_{i=1}^{n}(y_i-\overline{y})*(x_i-\overline{x})}{\sum_{i=1}^{n}(x_i-\overline{x})^{2}}$$
$$b = \overline{y} - a\overline{x}$$
x = population_inc_clean
y = population_old_clean
xbar = x.mean()
ybar = y.mean()
# 최소제곱법을 이용해 기울기와 절편 계산
slope = (sum((y-ybar)*(x-xbar)))/(sum((x-xbar)**2))
intercept = ybar - xbar*slope
print("기울기 :", round(slope,4))
print("절편 :", round(intercept,4))계산해보면 해당데이터는 기울기가 -0.35 절편이 15.66 정도 나오는것을 알 수 있습니다.
해당 값을 모델에 대입해보면 다음과 같은 식이 나오네요.
$$ 고령인구비율 = -0.35 * 인구증가율 + 15.66 $$
따라서 단순하게 인구증가율이 높아질수록 고령인구비율이 작아진다고 볼 수 있는데요. 이를 시각화해보도록 하겠습니다.
그래프로 확인하면 좀 더 효과적으로 데이터 분포를 확인할 수 있다는 장점이 있습니다~
start = x.min()
end = x.max()
line = np.arange(start, end, 0.1)
pred = slope*line + intercept
plt.plot(line, pred, "r-")
plt.scatter(x,y, c="k")
plt.xlabel("Population Growth Rate (%)")
plt.ylabel("Elderly Population Rate (%)")
plt.show()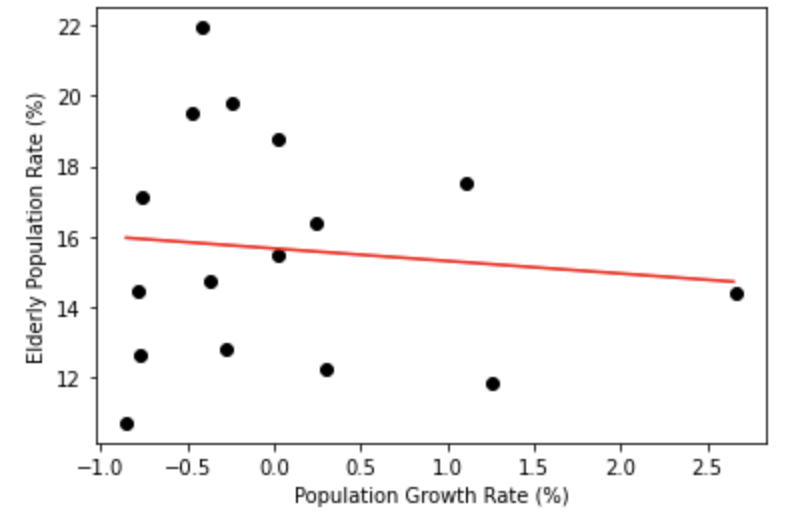
2. 텐서플로를 이용한 회귀분석
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
X = [0.3, -0.78, 1.26, 0.03, 1.11, 0.24, -0.24, -0.47, -0.77, -0.37, -0.85, -0.41, -0.27, 0.02, -0.76, 2.66]
Y = [12.27, 14.44, 11.87, 18.75, 17.52, 16.37, 19.78, 19.51, 12.65, 14.74, 10.72, 21.94, 12.83, 15.51, 17.14, 14.42]
# 기울기와 절편 초기화
slope = tf.Variable(tf.random.normal([1]))
intercept = tf.Variable(tf.random.normal([1]))
# MSE를 loss 함수로 정의
def compute_loss():
y_pred = slope * X + intercept
loss = tf.reduce_mean((Y - y_pred) ** 2)
return loss
optimizer = tf.keras.optimizers.Adam(learning_rate=0.1)
for i in range(1000):
optimizer.minimize(compute_loss, var_list=[slope,intercept])
line = np.arange(min(X), max(X), 0.01)
pred = slope * line + intercept
# 데이터와 회귀선 시각화
plt.plot(line,pred,'r--')
plt.plot(X,Y,'bo')
plt.xlabel('Population Growth Rate (%)')
plt.ylabel('Elderly Population Rate (%)')
plt.show()- 코드설명1) 기울기와 절편을 초기화하고 반복문에서 텐서플로 프레임워크에서 학습하기 위해 tensorflow.Variable 함수를 사용
- 코드설명2) MSE(Mean Squared Error)를 손실함수로 사용하였습니다. MSE는 실제값과 예측값의 차이인 오차(error)를 제곱하여 더한 값의 평균으로 다음과 같습니다. MSE가 작을수록 예측값이 실제값과 비슷하겠구나 생각하면 좋습니다. $$ MSE = \sum_{i=1}^{n}{\frac{(y-\widehat{y})^2}{n}} $$
- 코드설명3) 최적화기(Optimizer)를 설정하고 반복하는 동안 loss를 줄일 수 있는 방향으로 slope와 intercept를 변화시킵니다.

3. 딥러닝 네트워크를 이용한 회귀분석
텐서플로와 넘파이를 불러온 다음에 활성화함수를 ReLU를 적용한 3개의 레이어를 이용해 모델을 구축하였습니다.
최적화기는 SGD, 손실함수는 앞서 설명한 MSE를 사용하였습니다.
import tensorflow as tf
import numpy as np
x = np.array([0.3, -0.78, 1.26, 0.03, 1.11, 0.24, -0.24, -0.47, -0.77, -0.37, -0.85, -0.41, -0.27, 0.02, -0.76, 2.66])
y = np.array([12.27, 14.44, 11.87, 18.75, 17.52, 16.37, 19.78, 19.51, 12.65, 14.74, 10.72, 21.94, 12.83, 15.51, 17.14, 14.42])
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=16, activation="relu", input_shape=(1,)),
tf.keras.layers.Dense(units=8, activation="relu"),
tf.keras.layers.Dense(units=1)])
model.compile(optimizer = tf.keras.optimizers.SGD(learning_rate = 0.05),
loss = 'mse')
model.summary()
모델구축후 실제데이터인 x와 y를 이용해 적합합니다. 이때 반복횟수는 50번으로 설정하였습니다.
model.fit(x,y,epochs=50)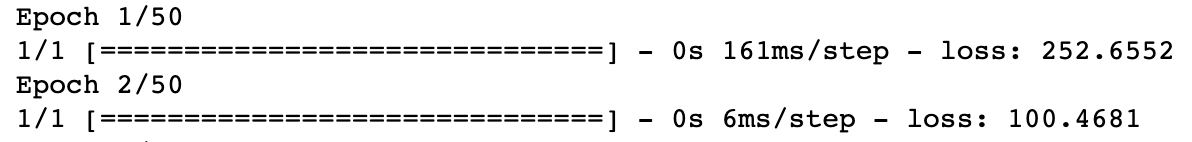

결과를 보면 초기에는 손실(loss)가 252, 100으로 높았으나 점점 모델이 데이터를 학습하면서 10 이하로 떨어진 것을 볼 수 있습니다.
또한 적합된 모델의 Predict 메서드를 이용하여 인구증가율이 0.35일때 예측해보면 15.53이 나옵니다.
이는 인가증가율이 0.35(%)일때 노인인구비율이 대략 15.53(%)임을 예측한다고 해석할 수 있습니다.

'AI > Deep Learning' 카테고리의 다른 글
| [Tensorflow] 3. 분류 (Classification) (0) | 2023.01.07 |
|---|---|
| [Tensorflow] 2-1 Regression with Boston housing datasets (0) | 2023.01.07 |
| [Tensorflow] 1. 논리연산을 위한 신경망 네트워크 생성 (0) | 2023.01.04 |
| [Tensorflow] 0. 신경망 네트워크의 구성 (0) | 2023.01.04 |
| [Tensorflow] M1 MacOS 텐서플로 설치 (0) | 2022.12.16 |