저번 포스팅까지 분류 기법인 로지스틱회귀, LDA, QDA을 알아보았고 분류기를 평가하는 방법에 대해 알아보았습니다.
이번 포스팅에서는 R을 이용한 분석 수행과 결과 해석에 대해 알아보려고 합니다.
분석하려고 하는 데이터셋은 Smarket의 데이터이며 2001년부터 2005년까지 S&P Index의 수익률을 나타냅니다.
변수는 Lag1 ~ Lag5, Volume(거래량), Direction(Up or Down)으로 구성되어 있으며
Direction을 반응변수로 하여 로지스틱회귀분석, LDA, QDA를 진행하려고 합니다.
- [R 필요 패키지] <tidymodels>, <tidyverse>, <MASS>, <ISLR>
- 로지스틱 회귀분석 : glm(formula, data, family = "binomial") or logistic_reg(engine="glm")
- LDA : MASS::lda(formula, data) or discrim_linear(engine="MASS")
- QDA : MASS::qda(formula, data) or discrim_quad(engine="MASS")
우선 간단하게 데이터가 어떻게 생겼는지 확인해 봅시다.
library(ISLR)
library(tidyverse)
Smarket = as_tibble(Smarket)
print(Smarket)
- Direction은 도메인과 같이 Up과 Down으로 구성되어 있습니다.
- 나머지 변수들은 유형이 <dbl>로 더블형 타입을 가지는 것을 알 수 있습니다.
# Direction의 유일값 체크
Smarket %>%
group_by(Direction) %>%
summarise(n=n())
- Direction은 "Down"과 "Up"의 두 가지 경우만을 가지며 범주별 관측치 수가 비슷하므로 클래스 불균형을 걱정할 필요는 없으며 이에 따라, OverSampling & UnderSampling을 진행하지 않아도 좋습니다.
# 설명변수의 분포
Smarket %>%
gather(2:7, key="variable", value="value") %>%
group_by(variable) %>%
ggplot(mapping=aes(x=variable, y=value)) +
geom_boxplot()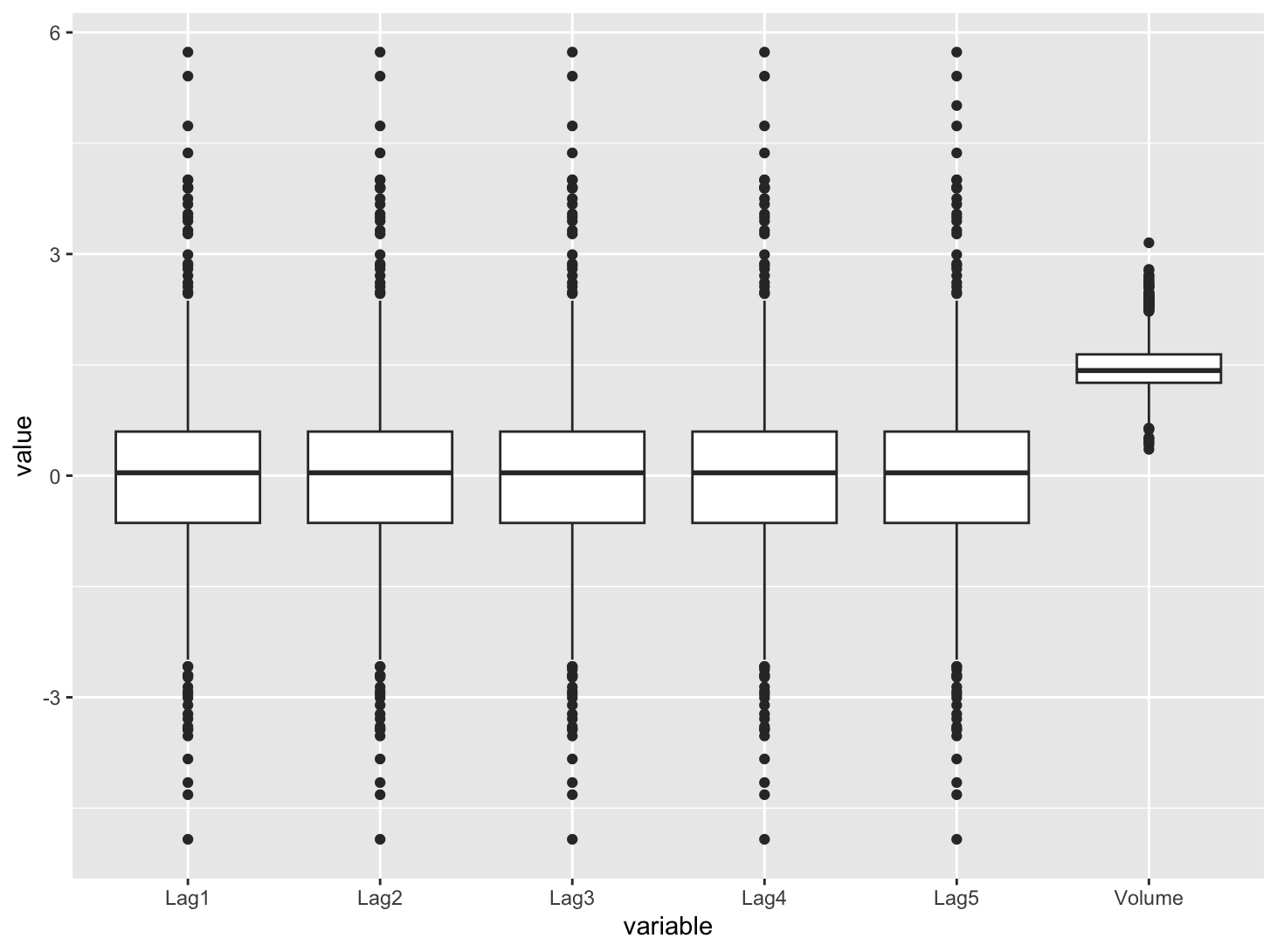
본격적인 모델 적합에 앞서 데이터 셋을 tidymodels의 initial_split( ) 함수를 사용하여 Train/Test로 분리하겠습니다.
# Train/Test set split
Smarket_split <- initial_split(data=Smarket, prop=0.7)
train <- Smarket_split %>% training()
test <- Smarket_split %>% testing()
dim(Smarket)
dim(train)
dim(test)
1. Logistic Regression
# Logistic Regression
library(tidymodels)
Logistic_model <- logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")
Logistic_fit <- Logistic_model %>%
fit(Direction~.-Year-Today, data=Smarket)
print(Logistic_fit)
print(tidy(Logistic_fit))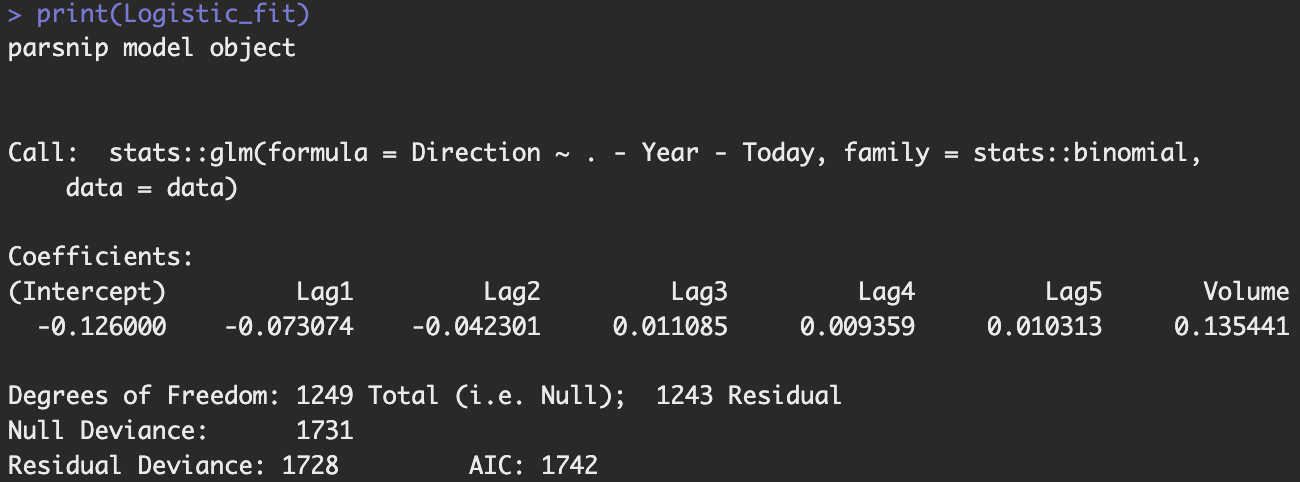

- tidymodels의 logistic_reg()와 glm()을 사용한 결과는 유사합니다.
- 다만, 모든 설명변수의 P-value가 유의수준 0.05보다 크므로 설명변수가 반응변수와 상관성이 있다는 사실을 입증할 수 없습니다.
class_pred <- predict(Logistic_fit, test, type="class")
prob_pred <- predict(Logistic_fit, test, type="prob")
class_pred
prob_pred- train 데이터로 학습한 Logistic_fit 모델을 test 데이터에 적용한 결과입니다.
- predict 함수를 사용하며 type="class"인 경우 해당 데이터의 예측 클래스를, type="prob"인 경우 확률을 출력합니다.


이제 적합한 모델로 예측을 진행하였으므로 혼동행렬(Confusion Matrix)를 만들기 위해 데이터를 합치는 작업을 진행하겠습니다.
res <- test %>%
select(Direction) %>%
bind_cols(class_pred)
print(res)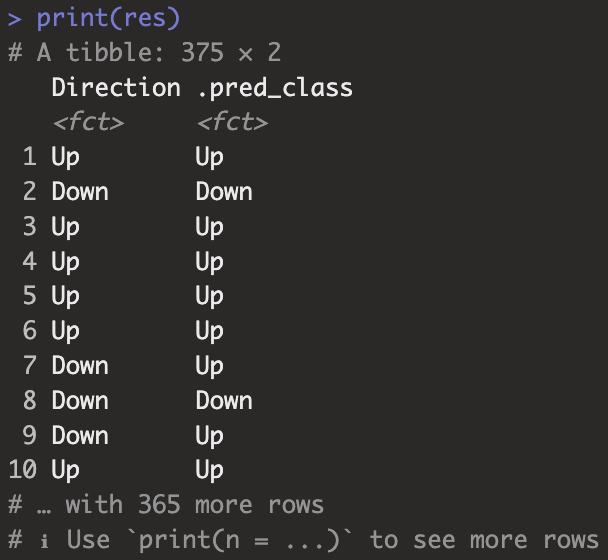
데이터 구성이 실제 클래스와 예측 클래스로 구성되어 있으므로 혼동행렬을 아래와 같이 구할 수 있습니다.
table(res)
conf_mat(res, truth="Direction", estimate = ".pred_class")

- table 함수를 사용하나, conf_mat( )함수를 이용하나 결과는 동일합니다.
또한, 이전 포스팅과 같이 아래 함수를 통해 민감도, 특이도, 정분류율, 재현율, 정확도, F1-score를 계산할 수 있습니다.
sens(res, truth="Direction", estimate = ".pred_class")
spec(res, truth="Direction", estimate = ".pred_class")
accuracy(res, truth="Direction", estimate = ".pred_class")
recall(res, truth="Direction", estimate = ".pred_class")
precision(res, truth="Direction", estimate = ".pred_class")
f_meas(res, truth="Direction", estimate = ".pred_class")
결과를 한번에 묶어서 출력하고 싶으면 Function Factory(함수공장) 함수인 metric_set을 이용해 출력합니다.
res_metrics <- metric_set(accuracy, sens, spec, recall, precision, f_meas)
res_metrics(res, truth="Direction", estimate=".pred_class")
ROC-Curve는 확률출력값과 실제값을 결합한 후, roc_curve( ) 함수를 통해 생성합니다.
res <- test %>%
select(Direction) %>%
bind_cols(prob_pred)
threshold <- res %>% roc_curve(truth = "Direction", ".pred_Down")
threshold %>% autoplot()
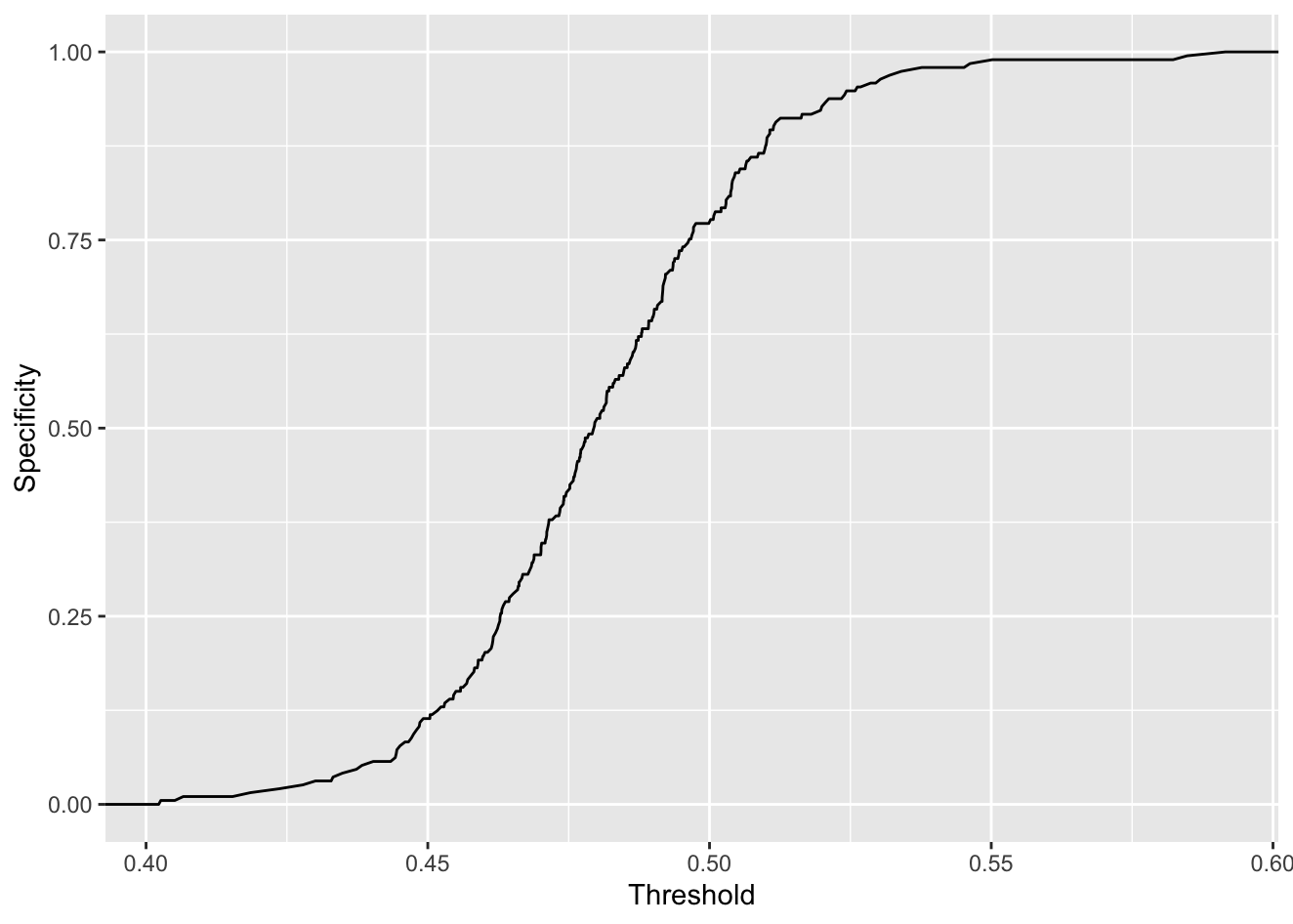
또한 Threshold(임계값)이 높아질수록 민감도는 낮아지고, 특이도는 높아지는 것을 시각화 할 수 있습니다.
threshold %>%
ggplot(mapping=aes(x=.threshold, y=sensitivity)) + geom_line() +
xlab("Threshold") + ylab("Sensitivity")
threshold %>%
ggplot(mapping=aes(x=.threshold, y=specificity)) + geom_line() +
xlab("Threshold") + ylab("Specificity")
마지막으로 AUC(AUROC)를 계산해보겠습니다.
roc_auc(res, truth="Direction", ".pred_Down")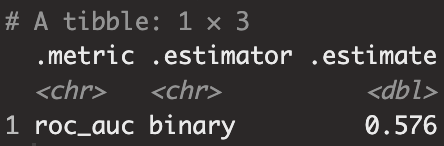
- AUC는 0.576이지만 일반적으로 주식 예측이 어렵다는 점에서 의미가 있는 값입니다.
2. LDA(선형판별분석)
도서에서는 MASS 라이브러리의 lda 함수를 이용하지만, 해당 분석에서는 tidymodels, discrim 패키지를 이용해 분석을 진행하였습니다. 참고로 lda 함수는 lda(formula, data)와 같이 사용가능합니다.
library(tidymodels)
library(discrim)
lda_model <- discrim_linear() %>%
set_engine("MASS") %>%
set_mode("classification")
lda_fit <- lda_model %>% fit(Direction~.-Year-Today, data=train)
print(lda_fit)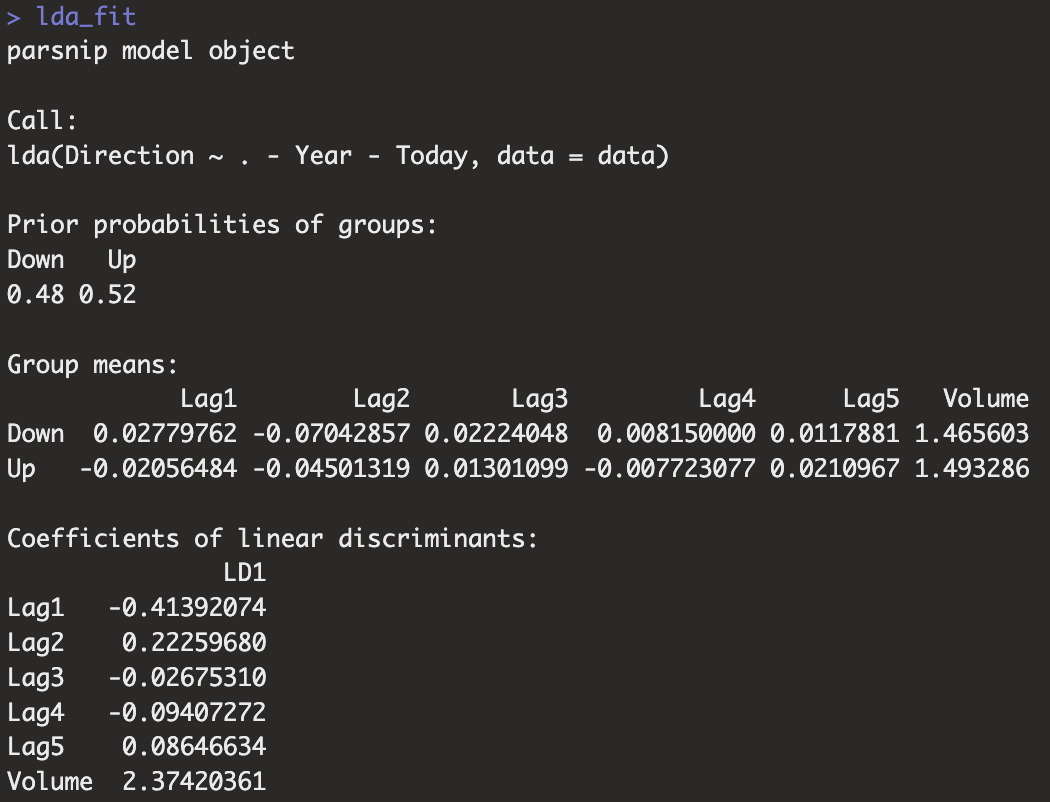
- 결과를 확인하면 $\hat{\pi_{Down}}$=0.48, $\hat{\pi_{Up}}$=0.52인 것을 확인할 수 있습니다.
- $-0.41Lag1 + 0.22Lag2 - 0.03Lag3 -0.09Lag4 + 0.08Lag5 + 2.37Volume$가 결정규칙으로 사용됩니다.
로지스틱 회귀와 비슷하게 혼동행렬 및 평가지표를 계산하면 아래와 같습니다.
class_pred <- predict(lda_fit, test, type="class")
prob_pred <- predict(lda_fit, test, type="prob")
lda.res <- test %>%
dplyr::select(Direction) %>%
bind_cols(class_pred, prob_pred)
conf_mat(lda.res, truth="Direction", estimate=".pred_class")
res_metrics <- metric_set(accuracy, sens, spec, recall, precision, f_meas)
res_metrics(lda.res, truth="Direction", estimate=".pred_class")

또한, ROC-Curve를 그리고 AUC(=AUROC)를 계산하면 0.495가 나오는데 이는 분류기의 성능이 좋지 않음을 의미합니다.
roc_curve(lda.res, truth = "Direction", ".pred_Down") %>% autoplot()
roc_auc(lda.res, truth="Direction", ".pred_Down")
3. 이차선형판별분석(QDA)
LDA와 유사한 부분이 많아 코드로만 제공합니다.
qda_model <- discrim_quad() %>%
set_engine("MASS") %>%
set_mode("classification")
qda_fit <- qda_model %>%
fit(Direction~.-Year-Today, data=train)
class_pred <- predict(qda_fit, test, type="class")
prob_pred <- predict(qda_fit, test, type="prob")
qda.res <- test %>%
dplyr::select(Direction) %>%
bind_cols(class_pred, prob_pred)
conf_mat(qda.res, truth="Direction", estimate=".pred_class")
res_metrics <- metric_set(accuracy, sens, spec, recall, precision, f_meas)
res_metrics(qda.res, truth="Direction", estimate=".pred_class")
roc_curve(qda.res, truth = "Direction", ".pred_Down") %>% autoplot()
roc_auc(qda.res, truth="Direction", ".pred_Down")
참고로 해당 데이터는 다변량 정규분포를 따르지 않기에 로지스틱이 성능이 제일 좋습니다!
'AI > Machine Learning' 카테고리의 다른 글
| [ISLR] 5. 붓스트랩(Bootstrap) (0) | 2023.04.05 |
|---|---|
| [ISLR] 5. 교차검증(Cross-Validation) (0) | 2023.04.04 |
| [ISLR] 4. 분류모델의 성과지표(Performance Metric) (0) | 2023.03.31 |
| [ISLR] 4. 분류(Classification) - 이차선형판별분석(QDA) (0) | 2023.03.31 |
| [ISLR] 4.분류(Classification) - 선형판별분석(LDA) (0) | 2023.03.30 |