안녕하세요. 저번 포스팅에서는 tidymodels와 parsnip 패키지를 이용해 분류를 진행했는데요. 이번 포스팅에서는 재표본추출 중 교차검증에 대해 알아보려고 합니다. 재표본추출에는 교차검증(Cross-Validation)과 붓스트랩(Bootstrap)으로 구성되는데요 그중에서 교차검증은 하나의 데이터를 훈련데이터와 검정데이터로 나누어 모델을 학습하고 평가하는 방법입니다.
1. VSA(Validation Set Approach)
- 데이터를 임의의 두 부분으로 나누어 Train/Test data로 지정하는 방법
- 일반적으로 Train data으로 모델을 훈련시키고, Test data로 모델을 평가하는데 사용된다
- ML/DL에서 Train/Validation/Test로 구분하기도 한다.
- `rsample::initial_spilt(df)` 또는 `rsample::initial_validation_split(df)`
- 다만, 어떤 데이터가 훈련 / 검정 셋에 속하는지에 따라 변동이 크다.
# 검증셋기법(VSA) 간단 구현
VSA <- function(data, train_prop=0.7){
n = nrow(data)
idx <- sample(1:n, size = n*train_prop, replace = F)
train <- data[idx,]
test <- data[-idx,]
return(list("train"=train, "test"=test))}
data <- VSA(data=data.frame(iris))
dim(data$train)
dim(data$test)# Tidy-Modeling을 이용한 모델 적합 및 rmse 계산
library(tidyverse)
library(tidymodels)
library(modelr)
library(ISLR)
### VSA method
data_split <- initial_split(Auto, prop = 0.8)
train <- data_split %>% training()
test <- data_split %>% testing()
lm.fit <- lm(mpg ~ horsepower, data=train)
lm.fit2 <- lm(mpg ~ poly(horsepower, degree = 2, raw = T), data = train)
lm.fit3 <- lm(mpg ~ poly(horsepower, degree = 3, raw = T), data = train)
test %>% select(mpg, horsepower) %>% modelr::gather_predictions(lm.fit, lm.fit2, lm.fit3) %>%
remove_rownames() %>%
ggplot(mapping=aes(x=horsepower, y=pred, color = model)) + geom_line() + geom_point() +
ggplot2::theme_bw()
tibble(truth = test$mpg, estimate = predict(lm.fit, newdata = test)) %>%
yardstick::rmse(truth, estimate)
tibble(truth = test$mpg, estimate = predict(lm.fit2, newdata = test)) %>%
yardstick::rmse(truth, estimate)
tibble(truth = test$mpg, estimate = predict(lm.fit3, newdata = test)) %>%
yardstick::rmse(truth, estimate)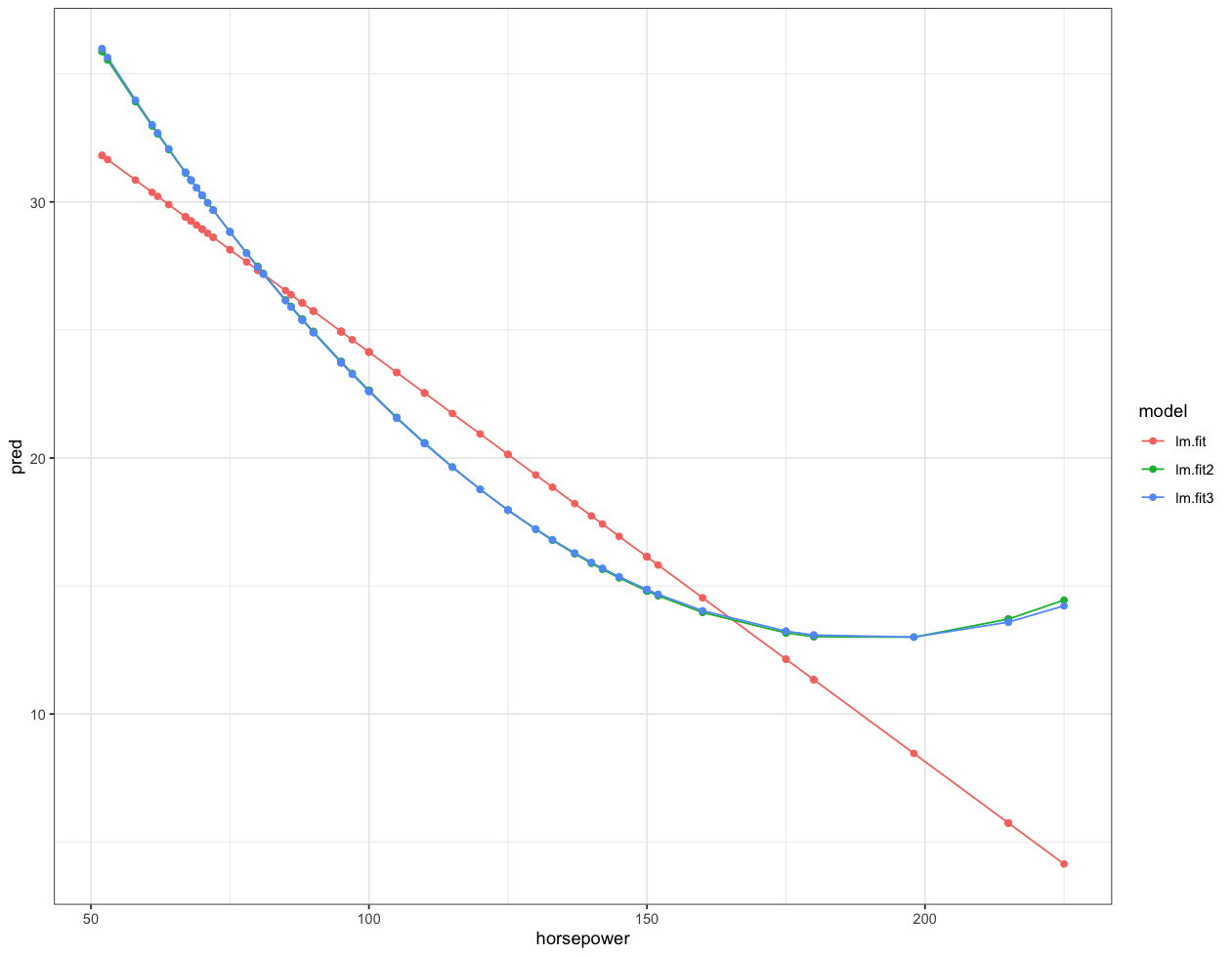
2. LOOCV(Leave-one-out Cross-Validation)
- VSA와 마찬가지로 데이터를 Train/Test 두 부분으로 분리하나 데이터의 크기가 n이라면 (n-1)개의 데이터를 Train data, 하나의 관측치를 Test data로 지정
- Train data로 학습한 모델로 Test 데이터를 평가하는 과정을 n번 반복해 손실(loss)을 평균하는 방법
- VSA대비 편향이 작으며 검정오차율을 과대추정하지 않는 경향이 존재하며 K-Fold CV보다 편향이 낮음
- rsample::roo_cv(df)
# LOOCV 간단 구현
LOOCV <- function(data){
n <- as.integer(nrow(data))
res <- list()
for(i in 1:n){
train <- data[-i,]
test <- data[i,]
res[[i]] <- list("train"=train,"test"=test)
}
return(res)}
data <- LOOCV(iris)
length(data)### LOOCV method
data_split <- loo_cv(Auto)
get_linearmodel <- function(df_split, degree=1, raw=T){
train <- df_split %>% analysis()
test <- df_split %>% assessment()
model <- lm(mpg~poly(horsepower, degree=degree, raw=raw), data=train)
pred <- predict(model, test)
return(pred)}
pred <- data_split %>%
mutate(fit1 = map_dbl(.x=splits, ~get_linearmodel(df_split = .x, degree = 1, raw=T)),
fit2 = map_dbl(.x=splits, ~get_linearmodel(df_split = .x ,degree = 2, raw=T)),
fit3 = map_dbl(.x=splits, ~get_linearmodel(df_split = .x, degree = 3, raw=T))) %>%
mutate(truth = map(.x=splits, .f=function(df) df %>% assessment() %>% select(mpg, horsepower)))
pred %>% unnest(truth) %>% pivot_longer(cols = contains("fit"), names_to = "model") %>%
ggplot(aes(x=horsepower)) + geom_point(aes(y=mpg)) + geom_point(aes(y=value, color=model))
pred %>% unnest(truth) %>%
pivot_longer(cols = contains("fit"), names_to = "model", values_to = "pred") %>%
group_by(model) %>% summarise(rmse = sqrt(mean((mpg-pred)^2)))

3. K-Fold Validation
- 데이터를 K개의 그룹으로 구분하여 (K-1)개를 그룹을 Train data, 하나의 그룹을 Test data로 지정하는 방법
- Train data로 학습한 모델로 Test 데이터를 평가하는 과정을 K번 반복해 손실(loss)을 평균하는 방법
- LOOCV보다 계산량이 적으며 검정오차율을 더 정확하게 추정한다는(=분산이 낮음) 장점이 있음
- rsample::vfold_cv(df)
# K-Fold CV 간단 구현
KFoldCV <- function(data, K=5){
n <- nrow(data)
fold_size <- floor(n/K)
shuffled_data <- data[sample(1:n, size=n, replace = F),]
folds <- list()
for(i in 1:(K-1)){
folds[[i]] <- shuffled_data[(1+fold_size*(i-1)):(fold_size*i),]}
folds[[K]] <- shuffled_data[(fold_size*(K-1)+1):n, ]
return(folds)}
data <- KFoldCV(data=iris, K=5)
length(data)
data %>% lapply(FUN=function(group_data){nrow(group_data)})### KFold-CV
# Model and Recipe
lm_model <- linear_reg() %>% set_engine("lm") %>% set_mode("regression")
basic_recipe <- recipe(mpg ~ horsepower, data = Auto)
degree2_recipe <- basic_recipe %>% step_poly(horsepower)
degree3_recipe <- basic_recipe %>% step_poly(horsepower, degree = 3)
# Workflow set
workflowset <- workflow_set(preproc = list("normal" = basic_recipe, "degree2" = degree2_recipe,
"degree3" = degree3_recipe),
models = list("linear" = lm_model))
# Data split and Model Fit
data_split <- vfold_cv(data = Auto, v = 10)
result <- workflow_map(workflowset, "fit_resamples", resamples = data_split)
result %>% collect_metrics(summarize = F) %>% filter(.metric == "rmse") %>%
ggplot(mapping=aes(x=id, y=.estimate, group = wflow_id, color = wflow_id)) + geom_line() +
ylab("RMSE") + xlab(NULL) + scale_color_discrete(labels = c("normal_linear" = "Degree1", "degree2_linear" = "Degree2", "degree3_linear" = "Degree3"))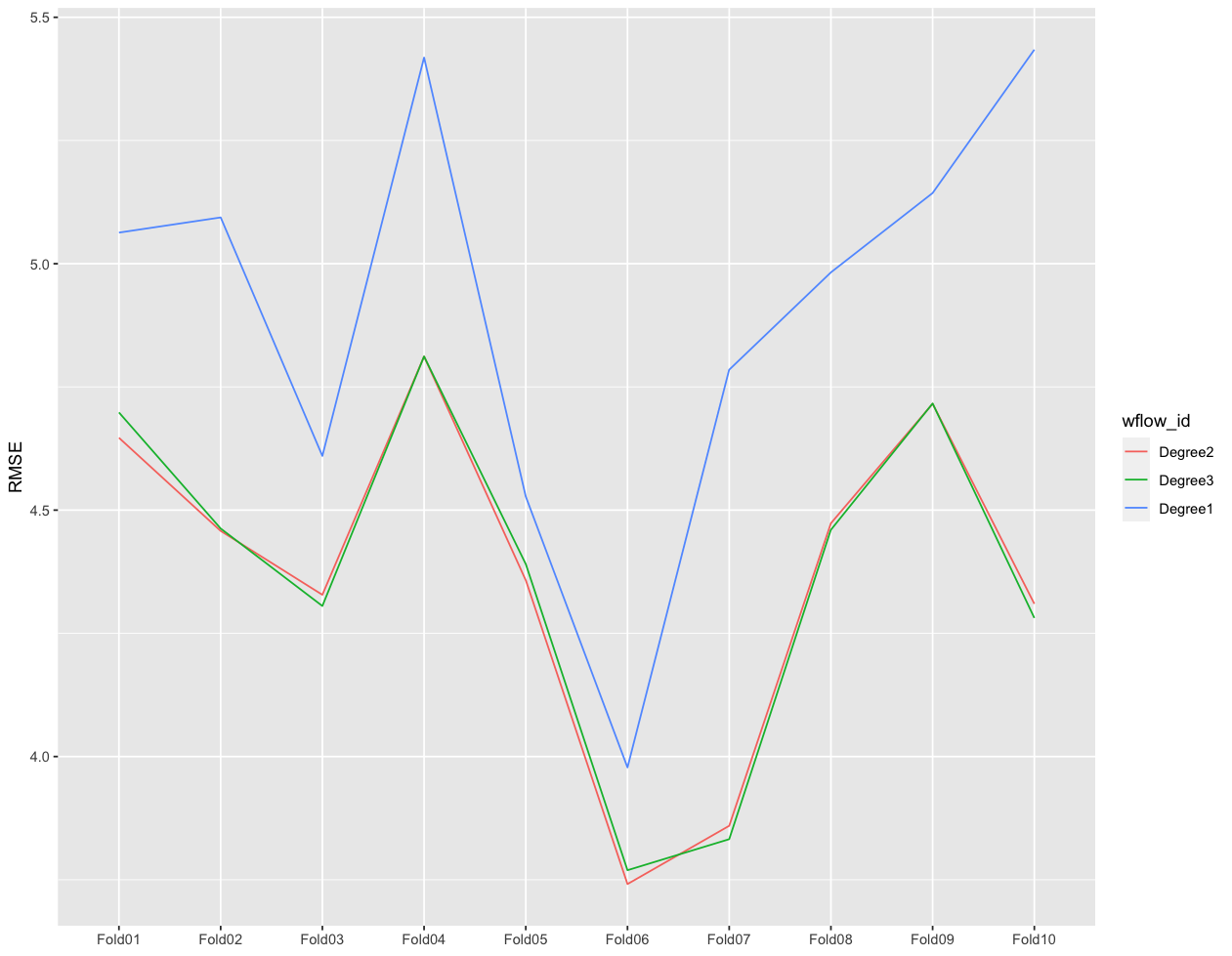
- Folds별로 상관성이 있는 것을 확인할 수 있습니다.
- Degree=2 또는 Degree=3일때 모델의 성능이 좋은 것을 확인할 수 있습니다.
- 코드설명은 https://moogie.tistory.com/95를 참고해주세요.
4. 요약(Summary)

'AI > Machine Learning' 카테고리의 다른 글
| [Regression & Classifcation] Decision Tree (0) | 2024.04.03 |
|---|---|
| [ISLR] 5. 붓스트랩(Bootstrap) (0) | 2023.04.05 |
| [ISLR] 4. 분류(Classifiction) With R Using Tidymodels (0) | 2023.03.31 |
| [ISLR] 4. 분류모델의 성과지표(Performance Metric) (0) | 2023.03.31 |
| [ISLR] 4. 분류(Classification) - 이차선형판별분석(QDA) (0) | 2023.03.31 |