Chapter 10에서 모델의 성과를 평가하기 위한 방법으로 재표본기법(Resampling)에 대해 소개합니다.
이전까지 많은 챕터에서 강조하고 있지만 Testing set은 여러 모델 중에서 선택된 최종 모델의 성능을 평가하기 때문에, 이전에 모델을 학습시킬 때는 어떠한 방식으로도 사용되어서는 안됩니다. 또한 단일 모델을 사용하더라도 하이퍼파라미터(Hyper Parameter)를 조정하거나, 여러 모델이 있는 경우 성능을 비교하기 위해서 Testing set을 사용하더라도 문제가 생깁니다. 따라서 이를 해결하기 위해 Resampling을 적용해 새로운 데이터와 유사한 성과를 추정하여야 합니다.
10 Resampling for Evaluating Performance | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
1. Resubstitution Approach
Resubstitution Approach는 학습을 위해 사용한 데이터로 모델의 성능을 측정하는 방법입니다. 또한 모델을 학습한 데이터로 성과를 측정한 지표를 Apparent Metric (Resubstitution Metric)이라고 합니다. 우선 아래코드와 같이 선형회귀 모형과 랜덤포레스트 모형을 준비합니다. 참고로 랜덤포레스트 모델은 전처리를 크게 필요로 하지 않기에 원데이터(raw data)를 그대로 사용했습니다.
library(tidymodels)
library(tidyverse)
ames <- ames %>% mutate(Sale_Price = log10(Sale_Price))
ames_split <- ames %>% rsample::initial_split(prop=3/4, strata = Sale_Price)
ames_train <- ames_split %>% training()
ames_test <- ames_split %>% testing()
### OLS model
ames_recipe <-
recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type + Latitude + Longitude, data = ames_train) %>%
step_log(Gr_Liv_Area, base=10) %>%
step_other(Neighborhood, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_interact(~ Gr_Liv_Area:starts_with("Bldg_Type_")) %>%
step_ns(Latitude, Longitude, deg_free=20)
lm_model <- linear_reg() %>%
set_engine(engine = "lm") %>%
set_mode(mode = "regression")
lm_workflow <- workflow() %>%
add_model(lm_model) %>%
add_recipe(ames_recipe)
lm_fit <- lm_workflow %>% fit(data = ames_train)
### Random Forest model
rf_model <- rand_forest(trees = 500) %>%
set_engine(engine = "ranger") %>%
set_mode(mode = "regression")
rf_workflow <- workflow() %>%
add_model(rf_model) %>%
add_formula(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built+ Bldg_Type + Latitude + Longitude)
rf_fit <- rf_workflow %>% fit(data = ames_train)
선형회귀 모델과 랜덤포레스트 모델이 있으므로 훈련 데이터를 이용한 Apparent Metric와 테스트 데이터를 이용한 Performance Matrix를 생성해 봅시다.
estimate_performance <- function(model, data){
# 입력 값 참조
cl <- match.call()
obj_name <- as.character(cl$model)
data_name <- as.character(cl$data) %>% str_replace_all("ames_", "")
# 회귀 전용 평가지표 정의
reg_metrics <- metric_set(yardstick::rmse, rsq, yardstick::mae)
# 퍼포먼스 출력
model %>%
predict(data) %>%
bind_cols(data %>% select(Sale_Price)) %>%
reg_metrics(truth=Sale_Price, estimate = .pred) %>%
mutate(object = obj_name, data = data_name)}
estimate_performance(lm_fit, ames_train)
estimate_performance(lm_fit, ames_test)
estimate_performance(rf_fit, ames_train)
estimate_performance(rf_fit, ames_test)

- 대체적으로 선형회귀모형보다 랜덤포레스트의 성능이 더 좋습니다.
- 두 모형에서 ames_train을 사용한 것 보다 ames_test를 사용했을때 성능이 떨어집니다.
- 유연한 랜덤포레스트는 train/test 성과지표의 차이가 크고, 유연성이 떨어지는 회귀모형은 성능이 비슷하게 측정됩니다.
위의 결과를 토대로 랜덤포레스트 모델을 선택하겠지만 training set과 testing set에서의 성과지표의 차이가 크게 나타나는 것을 볼 수 있습니다. 랜덤포레스트와 같은 예측모형은 주어진 데이터의 복잡한 패턴을 학습하므로 Training set으로 성과 측정을 한다면 한번도 학습하지 못한 데이터인 Testing set 보다 성과가 좋을 수 밖에 없습니다.
따라서 Testing set을 당장 사용하지 못한다고 하더라도 Training set으로 모델의 성과를 측정하는 것은 좋지 못한 생각입니다.
2. Resampling Methods
본문에서는 재표본기법(리샘플링)을 Training 데이터에서 일부를 모델링에, 남은 일부를 모델을 평가할 때 사용하는 프로세스라고 설명합니다. 설명이 조금 모호하다고 느낄 수 있는데 아래 그림을 보며 설명하겠습니다.
(* 참고로 재표본기법(리샘플링)에는 크게 교차검증(CV, Cross-Validation)과 부스트랩(Bootstrap)으로 나눌 수 있습니다. 교차검증은 https://moogie.tistory.com/57, 붓스트랩은 https://moogie.tistory.com/58을 참고해주세요)
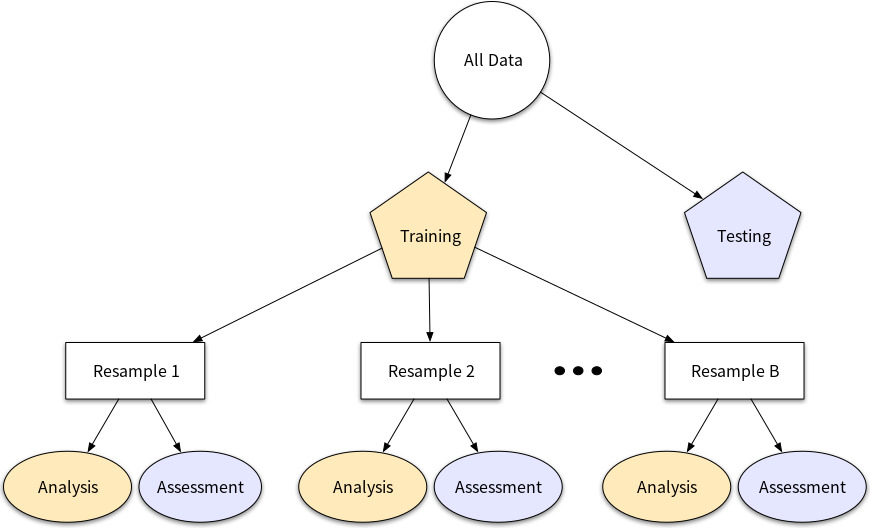
가용 가능한 데이터(All data)는 여태까지 그랬던 것처럼 Training set과 Testing set으로 나눌 수 있습니다.
이때, Training set에 Resampling method를 적용해 B개의 리샘플링 표본을 생성한 후 각 리샘플링 표본의 일부를 모델 학습에 사용하는 Analysis data(=Training data)와 중간에 모델을 평가하는 Assessment data (=Validation data)로 구분할 수 있겠습니다.
즉 모델을 훈련시킬때 Analysis data를 사용하고, 중간 평가(하이퍼파라미터 조정, 파라미터 조정, 모델 간/내 비교)를 Assessment data, 최종 선택된 모델의 성능을 평가할때는 Testing data를 사용하게 됩니다.
앞으로의 챕터에서는 위 그림처럼 데이터를 분할하여 학습 및 평가를 진행하므로 개념은 꼭 알아두고 간단하게 아래와 같이 3-Step으로 요약할 수 있습니다.
- 사용 가능한 데이터를 Training set과 Testing set으로 분할한다.
- Training set에 Resampling을 반복적으로 적용하여 B개의 표본을 생성한다.
- B개의 각 표본에서 일부를 모델을 훈련시키는 데이터인 Analysis set, 나머지를 모델 평가에 사용하는 Assessment set으로 분할한다.
3. Cross-Validation (CV, 교차검증)
교차검증은 재표본기법 중의 하나로 VSA(rsample::initial_split or initial_validation_split), LOOCV(rsample::loo_cv), K-fold CV와 같이 여러가지 기법이 존재합니다. 다만 자주 사용되는 방법이 K-fold CV이므로 본문에서는 이를 중심으로 소개합니다. K-fold CV는 데이터를 임의로 비슷한 크기를 가지는 K개의 그룹으로 분할하는 기법으로 K-1개의 그룹은 데이터를 학습하는데 사용되며 학습하는데 사용하지 않은 남은 1개의 그룹은 모델의 성능을 평가하는데 사용됩니다. 또한 일반적으로 K=5 또는 K=10을 사용하며 rsample::vfold_cv 함수를 사용해서 구현할 수 있습니다.
### V-Fold cross-validation
ames_vfold <- ames_train %>% rsample::vfold_cv(v=10)
ames_vfold
- ames_train에 vfold_cv를 적용한 결과 splits와 id의 열이름을 가지는 티블 객체를 반환합니다.
- splits는 rsplit 객체를 K(=V) * Repeats 개수만큼 가지고 있는 리스트입니다. (여기서는 repeats=1)
- 각 rsplit 객체에 analysis, assessment 함수를 적용해 analysis set(=training set)과 assessment set(=validation set)을 얻을 수 있습니다.
K-fold CV는 훌룡한 교차검정의 방법이지만 데이터의 크기나 기타 특성에 따라 리샘플링 추정치가 과도하게 노이즈한 경우가 있습니다. 이런 경우 R repeats K-fold CV를 생각해 볼 수 있는데 이는 K개의 Fold를 가지는 객체를 R번 반복하여 생성하는 방법입니다. 단순히 K-fold CV를 적용한 경우 K개의 통계량이 생성되지만 R repeats K-fold CV를 적용한 경우에는 R*K개의 통계량이 생성됩니다. 폴드를 나누는 과정을 R번 진행하면 중심극한정리에 따라 생성된 통계량의 평균에 대한 분포가 좀 더 정규분포에 가까워 진다는 장점이 존재하며 표준오차 역시 감소한다는 좋은 특성을 가지고 있습니다. 참고로 R에서는 rsample::vfold_cv에서 repeats를 지정함으로써 R repeats K-Fold CV를 구현할 수 있습니다.
ames_train %>% vfold_cv(v=10, repeats = 5)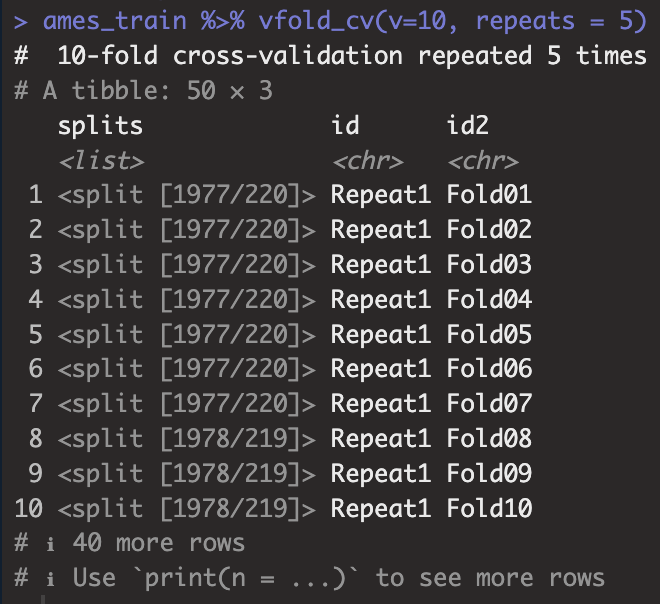
또한, 몬테카를로 CV는 폴드를 나누어 iterative하게 학습/검정 데이터를 구분하는 것이 아닌 매 반복마다 학습 데이터와 검정데이터를 무작위로 선택하는 방법으로 R에서는 rsample::mc_cv로 구현할 수 있습니다.
4. Boostrapping
붓스트랩은 통계량의 표본 분포를 근사적으로 구하기 위해서 고안되었습니다. 붓스트랩은 복원추출을 통해 데이터의 크기만큼 표본을 추출하는 방법으로 만약 Training set에 대한 붓스트랩 샘플을 얻기 위해서는 Training data에 대해 Training data의 크기만큼 복원추출하여 1개의 붓스트랩 샘플을 얻을 수 있으며 이를 B번 반복한다면 B개의 붓스트랩 샘플을 얻을 수 있겠습니다. 붓스트랩은 복원추출을 하는 만큼 동일한 데이터가 여러번 선택될 수 있습니다. 반대로 일부 데이터는 표본으로 추출되지 않을 수 있으며 이를 OOB(Out-Of-Bag) data 라고 하며 이를 assessment set으로 사용합니다. R에서는 rsample::bootstraps를 사용해서 구현할 수 있으며 교차검증보다 낮은 분산을 보이지만 높은 편향을 가질 수 있습니다.
bootstraps(ames_train, times=10)
5. Estimating Performance
재표본 기법들은 모델을 평가하는데 사용할 수 있습니다. 리샘플링은 학습과 평가에 효과적인데 그 이유는 모델을 학습시키거나 모델을 평가할때 다른 데이터 그룹이 사용되기 때문입니다.
- analysis set은 데이터 전처리 및 모델 적합에 사용합니다.
- analysis set을 사용해 전처리된 통계량(eg. 평균, 분산)은 assessment set을 전처리할 때 그대로 사용됩니다.
- assessment set은 새로운 데이터에 대한 모델의 성과를 추정하는데 사용됩니다.
일반적으로 K-fold CV를 적용하면 K개의 폴드에 해당되는 K개의 추정량(metric)이 생성되므로 재표본 추정량은 해당 추정량의 평균으로 정의합니다. R에서는 아래와 같이 fit_resamples 함수를 통해 리샘플링 표본에 대해 편리하게 모델 학습과 지표 추정 생성을 수행할 수 있습니다. 또한 control_resamples를 통해 리샘플링 표본에 대해 적합 및 평가시 유용하게 사용할 수 있는 함수를 제공합니다.
- model_spec |> fit_resamples(preprocessor=formula, resamples, ...)
- model_spec |> fit_resamples(preprocessor=recipe_object, resamples, ...)
- workflow |> fit_resamples(resamples, ...)
# Parsnip Model + Formula
rand_forest(mode = "regression") |>
fit_resamples(Sale_Price ~ ., resamples = ames_vfold)
# Parsnip Model + Recipe
rand_forest(mode = "regression") |>
fit_resamples(preprocessor = ames_recipe, resamples = ames_vfold)
# Workflow
rf_res <- rf_workflow |>
fit_resamples(resamples = ames_vfold)
# Workflow + (Optional) Control
keep_pred <- control_resamples(save_pred = T, save_workflow = T)
rf_res <- rf_workflow |>
fit_resamples(resamples = ames_vfold, control = keep_pred)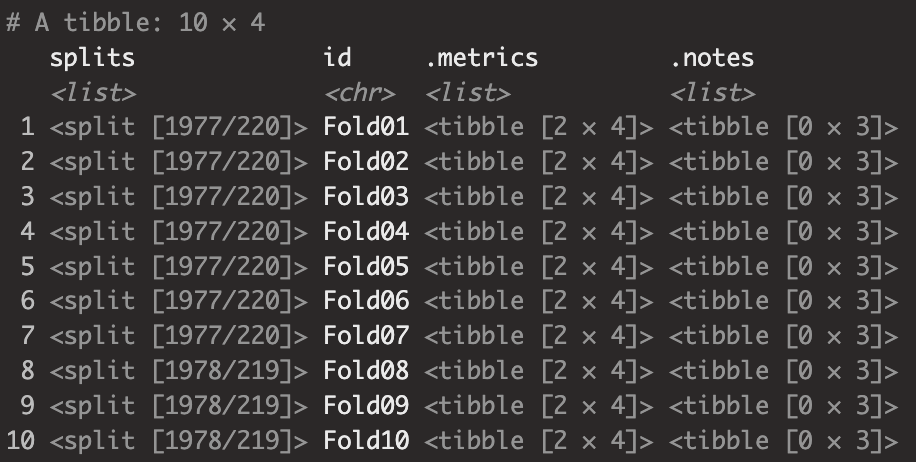
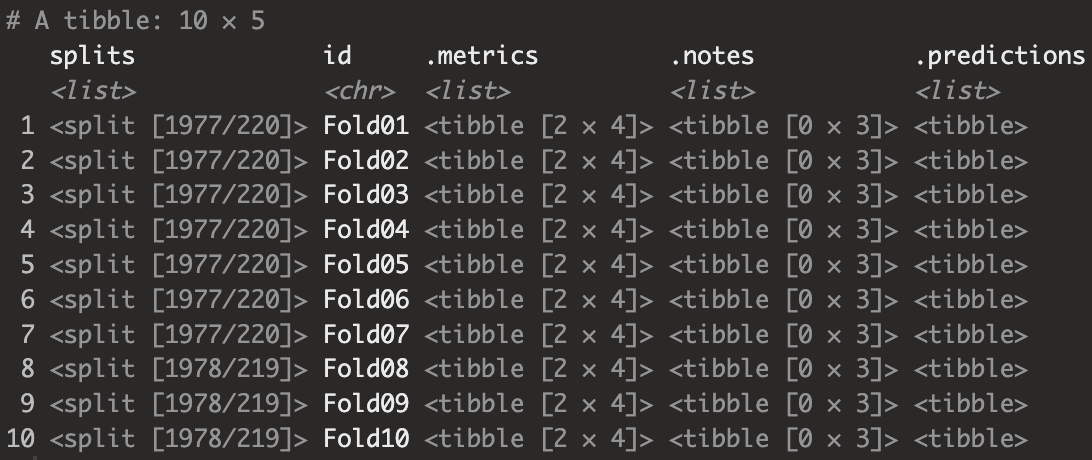
전처리기(formula, recipe)와 모델(parsnip object)이 추가된 workflow 객체에 fit_resamples를 적용한 결과 리스트열(list column)을 가진 티블 객체를 반환하는 것을 확인할 수 있습니다. 또한 .metric 열에는 지정한 모델 성과(미지정시 회귀모델은 RMSE, $R^2$ 분류모델은 AUC, accuracy)를 포함하고 있습니다.
리스트열로 구성되어 있어 보기 어려우므로 unnest 함수 혹은 collect_metrics(summarise=F)를 사용해서 아래와 같이 전체 성과 지표를 얻을 수 있습니다. 이와 유사하게 예측값의 경우 collect_predictions(summarise=F)를 사용해 얻을 수 있습니다. (Boostrap이나 R repeats K-fold CV 같은 경우 하나의 관측치에 대해 여러 예측값이 나올 수 있어서 이런 경우에는 summarise=T를 지정)
rf_res %>% unnest(.metrics)
collect_metrics(rf_res, summarize = F)
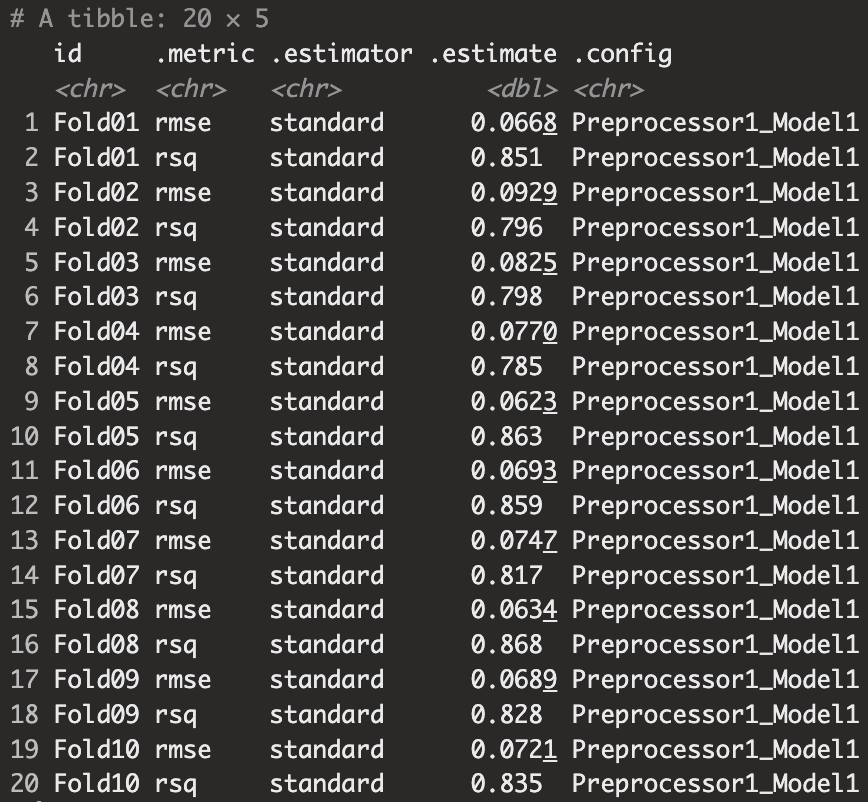
앞서 재표본 추정량은 각 재표본 샘플로 구한 추정량의 평균이라고 했는데 collect_metrics(summarize=T) 함수를 통해 구할 수 있습니다.
collect_metrics(rf_res, summarize = T)
예측값을 사용해서 아래와 같은 시각화를 얻을 수 있습니다.
Tree model로 예측된 결과가 실제 결과와 매우 유사한 것을 알 수 있으며 Loess 회귀선도 잘 따라가는 것을 확인할 수 있습니다.
assess_res <- collect_predictions(rf_res)
assess_res |>
ggplot(mapping=aes(y=Sale_Price, x=.pred)) +
geom_point(alpha=0.5, color = "grey40") +
geom_smooth(method = "loess", color = "blue")+
geom_abline(color="red") +
coord_obs_pred() +
labs(y = "Sales_Price", x = "predictions", title = "Tree Model")
6. Parallel Processing
fit_resamples를 포함한 tune 패키지에 있는 함수들은 병렬처리 기능을 사용할 수 있습니다. 아래는 간단한 함수 요약입니다.
- parallel::detectCores(logical=F) : 물리적 코어개수
- parallel::detectCores(logical=T) : 논리적 코어개수
- doMC::registerDoMC(cores) : 유닉스와 맥OS에서 분할연산 지원하기 위한 함수
- doParallel::registerDoParallel(makePSOCKcluster(코어수)) : 네트워크 소캣을 이용한 분할 계산
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 12. 하이퍼파라미터 튜닝 (0) | 2023.10.11 |
|---|---|
| [Tidy Modeling with R] 11. Model Comparison (모델 비교) (0) | 2023.10.09 |
| [Tidy Modeling with R] 9. Performance Metrics (모델 성과 지표) (0) | 2023.09.27 |
| [Tidy Modeling with R] 8. Feature Engineering with Recipes (0) | 2023.09.21 |
| [Tidy Modeling with R] 7. Model Workflow (0) | 2023.09.13 |