피처 엔지니어링(Feature Engineering)은 머신러닝이나 딥러닝에서 모델의 성능을 향상시키기 위해서 변수를 변환하는 과정을 포함합니다. 대표적으로 하나 또는 두개 이상의 변수들을 활용하여 새로운 파생변수를 생성하거나, 표준화나 정규화를 사용해 스케일을 조정하거나, 범주형 (명목형, 순서형) 변수들을 더미화&수치화해서 사용한다거나, PCA를 사용해서 기존 변수들을 새롭게 표현하다거나, 상관계수를 이용해서 변수를 제거한다거나, 결측치를 대치(Imputation)하는 등 여러가지 방법들을 포함하고 있습니다.
예를 들면 두 개의 설명변수 $X1$, $X2$ 가 있고 반응변수 $Y$에 대해 OLS 선형회귀를 적합한다고 생각해봅시다.
이때, $Y$는 면적을 나타내며 $X1$, $X2$는 직사각형의 너비와 높이를 나타낸다고 한다면 $Y = X1 * X2$의 관계를 만족할 것입니다.
그리고 약간의 측정오차를 고려한다면 실제 데이터 생성 프로세스(DGP)는 $Y = X1 * X2 + e$ 와 같이 표현할 수 있겠습니다.
하지만 이러한 도메인 정보를 알지 못하고 데이터 사이언티스트가 두 개의 설명변수의 주효과만 포함해서 회귀식을 $Y \sim X1 + X2$와 같이 표현한다면 정확한 모델을 생성할 수 없을 것입니다. 그렇지만 두 개의 설명변수를 곱해서 새로운 파생변수 $Z = X1 * X2$를 회귀식에 사용한다면 훨씬 훌룡한 모델을 가질 수 있겠죠!
이처럼 피쳐 엔지니어링은 모델을 효과적으로 사용하기 위해서 설명변수를 Reformatting 하는 과정을 수반하고 있습니다.
Chapter 8에서는 Recipes 패키지를 이용하여 Feature Engineering 및 Preprocessing를 하는 방법에 대해서 소개합니다.
8 Feature Engineering with recipes | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
1. Simple recipe function for the Ames housing data
Ames Housing Data에는 여러가지 변수를 포함하고 있지만 편의성을 위해 아래와 같은 4가지의 변수를 설명변수로 사용합니다.
- Neighborhood : 정성적(질적) 데이터로 29개의 범주를 가지고 있습니다.
- Gr_Liv_Area : 정량적(양적) 데이터로 생활 면적에 대한 데이터입니다.
- Year_Bulit : 정량적(양적) 데이터로 건물이 지어진 연도를 나타냅니다.
- Bldg_Type : 정성적(질적) 데이터로 건물의 종류를 나타냅니다.
회귀분석을 다음과 같은 코드로 돌린다고 생각해봅시다.
with(ames, lm(Sale_Price ~ Neighborhood + log10(Gr_Liv_Area) + Year_Built + Bldg_Type))위 코드를 실행하면 데이터 프레임에 있는 데이터가 설계행렬(numeric design matrix)로 변환되고 최소제곱법을 사용하여 회귀계수를 추정합니다. Chapter 3에서 설명한 것처럼 R model formula를 통해 아래와 같은 단계를 포함합니다.
- Sale_Price를 반응변수로 Neighborhood, Gr_Liv_Area, Year_Built, Bldg_Type을 설명변수로 정의합니다.
- Gr_Liv_Area에 로그 변환을 적용합니다.
- 정량적 데이터인 Neighborhood와 Bldg_Type을 더미변수로 변환합니다.
앞으로 사용할 recipe 객체는 위와 같은 데이터 처리를 위해 필요합니다. 모델링 함수안에 포함된 formula와 다르게 step_*( ) 함수를 통해 정의할 수 있으며 지연 연산(Lazy evaluation)을 통해 필요한 시점까지 함수들을 실행하지 않습니다.
앞서 1,2,3에 포함된 전처리 단계를 recipe 패키지를 사용해서 아래와 같이 변환할 수 있습니다.
simple_ames <- recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type, data = ames) %>%
step_log(Gr_Liv_Area, base=10) %>%
step_dummy(all_nominal_predictors())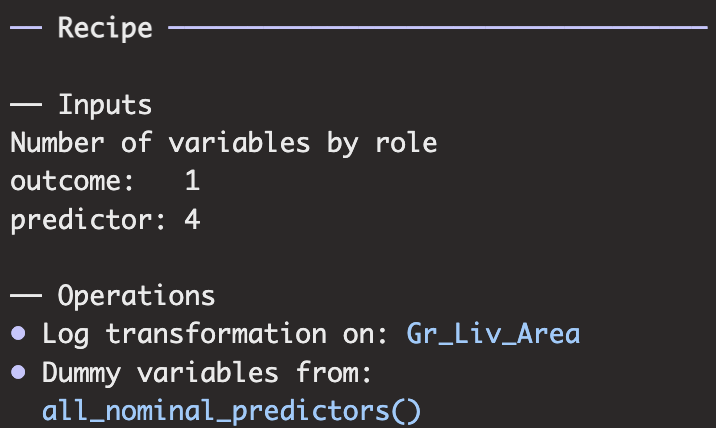
- step_log 함수를 통해 Gr_Liv_Area가 로그변환 되어야 하는것을 선언합니다.
- step_dummy 함수를 통해 모든 정량적 변수가 더미화가 되어야하는 것을 선언합니다.
- all_nomial_predictors 함수를 사용해 모든 정량적 변수를 가르키고 있습니다. (all_numeric_predictor는 수치형 변수)
2. Using Recipes
Chapter 7에서 살펴본 것 처럼, 전처리와 피쳐 엔지니어링 단계는 모델링 과정의 일부로 입니다.
따라서, workflows 패키지에는 recipe 객체를 전처리기로 포함할 수 있는 add_recipe( ) 함수를 지원합니다. (모델은 add_model로 추가했었죠!)
저번 챕터에서 생성한 lm.workflow 코드는 아래와 같이 model과 formula를 추가한 상태입니다.
ames.split <- ames %>% rsample::initial_split()
ames.train <- ames.split %>% training()
ames.test <- ames.split %>% testing()
simple_ames <-
recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames.train) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_dummy(all_nominal_predictors())
lm.model <- linear_reg() %>%
set_engine(engine = "lm") %>%
set_mode(mode = "regression")
lm.workflow <- workflow() %>%
add_model(lm.model) %>%
add_formula(Sale_Price ~ Longitude + Latitude)
여기서 recipe 객체를 추가하기 위해서 add_recipe 함수를 사용하면 오류가 발생하는데요!
이유는 워크플로는 전처리기를 하나만 가질 수 있는데 lm.workflow에는 이미 formula라는 전처리기를 가지고 있어서 그렇습니다.
따라서 아래와 같이 formula를 제거한 후에 recipe 객체를 추가해야지 정상적으로 작동합니다!
lm.workflow <- lm.workflow %>%
remove_formula() %>%
add_recipe(simple_ames)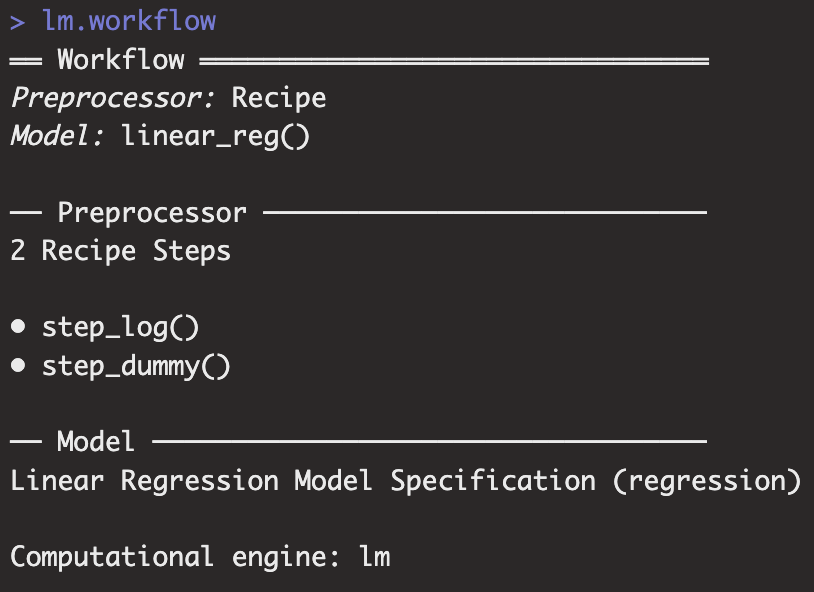
Chapter 7에서 처럼 모델과 전처리기를 추가한 워크플로 객체에 fit 함수를 통해 모델을 학습시킬 수 있으며 학습된 모델에 predict 함수를 통해 값을 예측할 수 있습니다.
또한 training set에 적용한 같은 전처리기(Preprocessor)를 testing set에 동일하게 적용하므로 따로 변환할 필요가 없다는 점 참고하세요!
lm.fit <- lm.workflow %>% fit(ames.train)
predict(lm.fit, ames.test, type="numeric")
마지막으로 학습된 모델인 lm.fit에 포함된 전처리기나 모델, 레시피 등을 알고 싶으면 아래와 같은 코드를 참고해보세요
lm.fit %>% extract_recipe(estimated = T)
lm.fit %>% extract_preprocessor()
lm.fit %>% extract_fit_engine() %>% tidy()
lm.fit %>% extract_fit_parsnip() %>% tidy()
3. Recipe Step function
- Encoding Qualitative data
- step_unknown : 결측치를 특정 범주(default : "unknown")로 변환
- step_novel : Training set에 존재하지 않은 범주 값을 “new” 범주로 변환
- step_other : 빈도가 threshold(자연수 : 빈도, 소수 : 비율) 이하인 범주를 “other”로 통합
- step_dummy : 정성적 데이터를 더미화 (one_hot=T로 하면 원-핫 인코딩 실행)
(+ 범주형 변수를 step_dummy를 통해 이용한 경우 각 "변수명_범주값"의 열을 가지도록 변환됨) - step_integer : convert values to predefined integers
- Interaction Terms
- step_interact(~interaction terms) : 상호작용항 추가
ames.train %>% ggplot(mapping=aes(x=Gr_Liv_Area, y=Sale_Price)) +
geom_point(alpha=0.5) +
geom_smooth(method="loess", formula=y~x, se=F) +
geom_smooth(method="lm", formula = y~x, se=F, color="red") +
facet_wrap(~Bldg_Type)
ames.train %>% ggplot(mapping=aes(x=Gr_Liv_Area, y=Sale_Price, color = Bldg_Type)) +
geom_point(alpha=0.5, color="grey40") +
geom_smooth(method = "loess", se=F, span=0.3)
ames.train %>% ggplot(mapping=aes(x=Gr_Liv_Area, y=Sale_Price, color = Bldg_Type)) +
geom_point(alpha=0.5, color="grey40") +
geom_smooth(method = "lm", se=F, fullrange=T)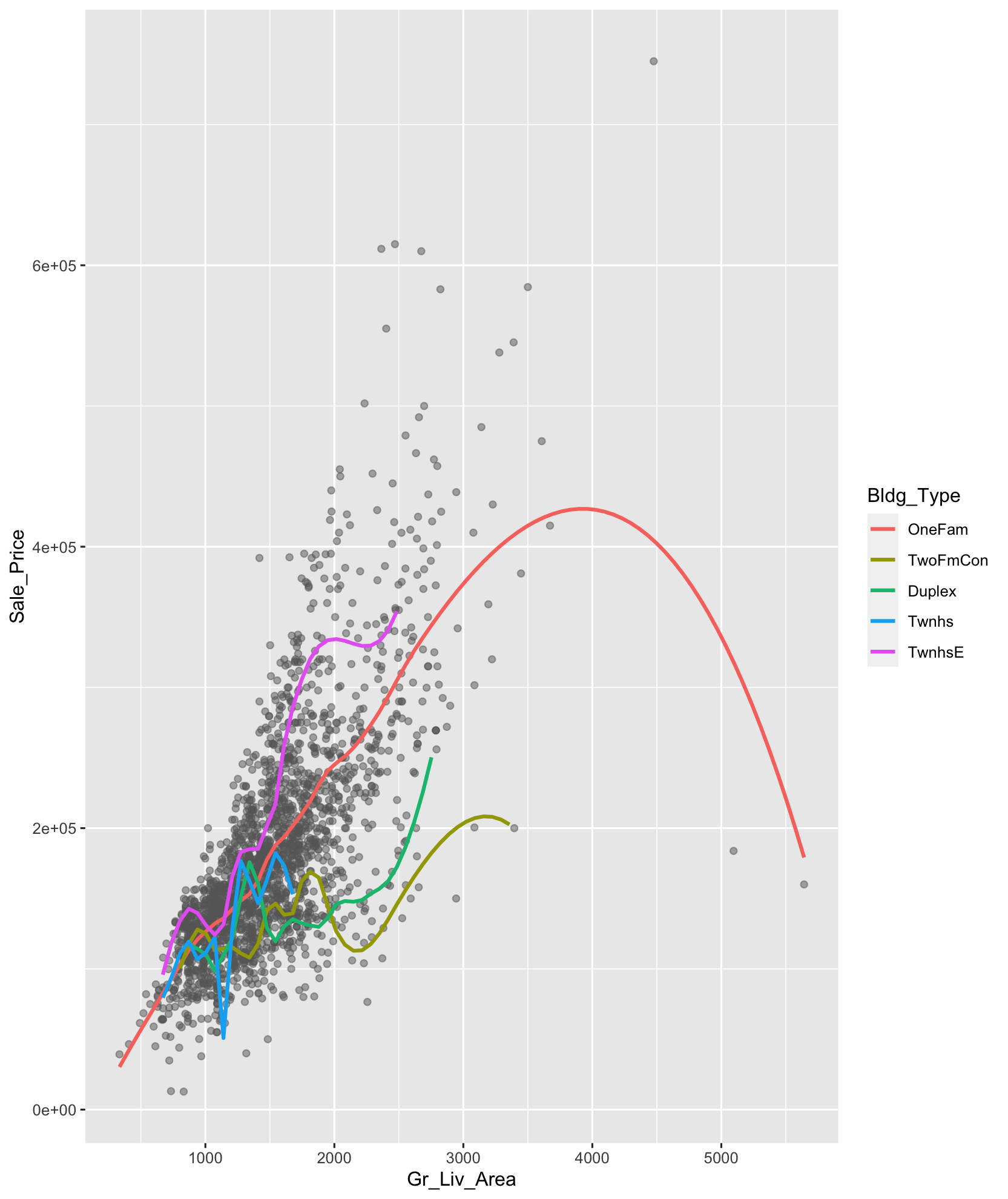
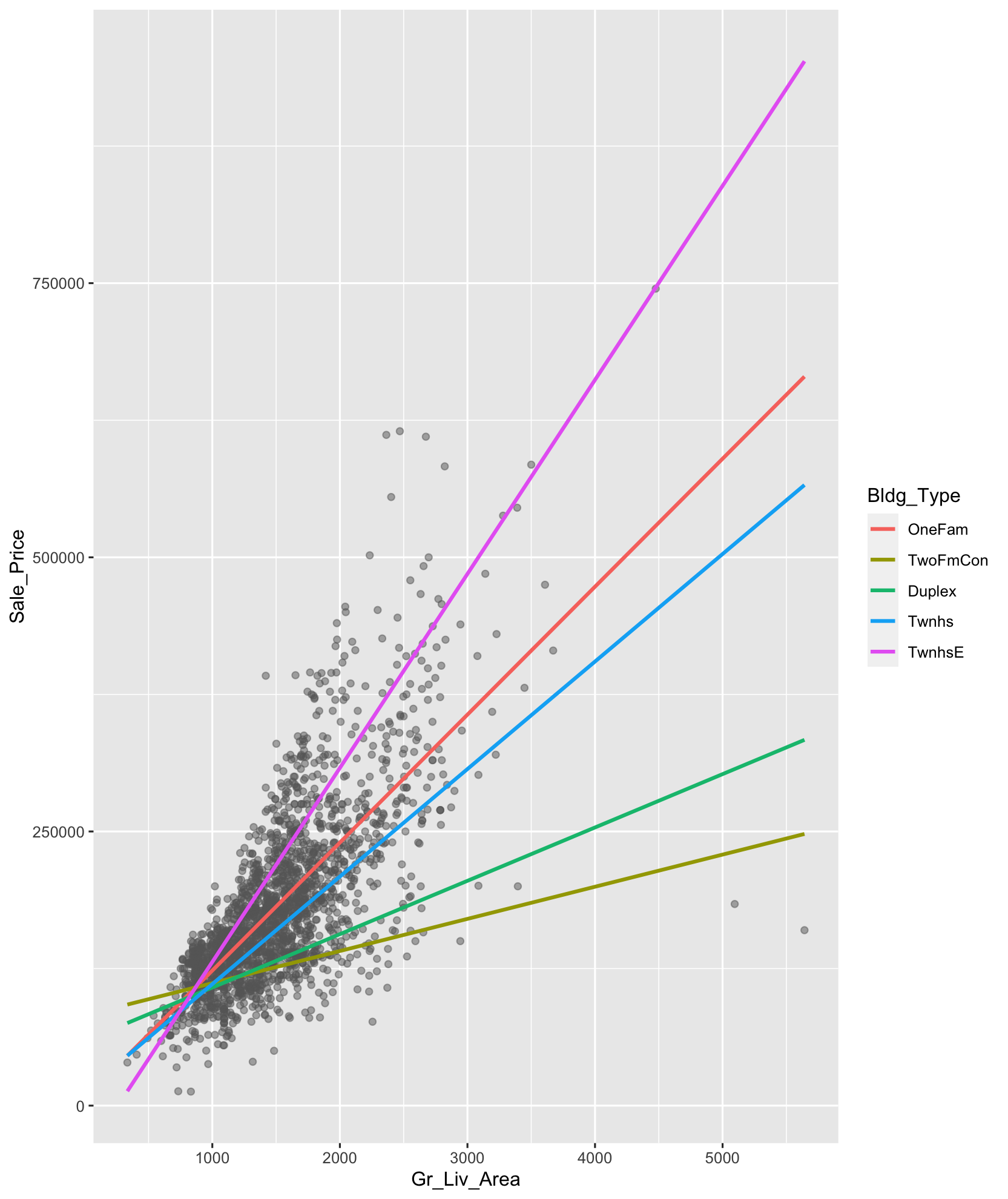
- Sale_Price에 대한 Gr_Liv_Area의 회귀계수는 Bldg_Type에 따라 차이가 있는 것으로 보입니다.
- 따라서 step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))을 사용하여 상호작용항을 추가합니다
- Spline Function : when predictor has nonlinear-relationship with outcome
- step_ns
- step_poly
- step_spline_*
plot_smoother <- function(deg_free){
ggplot(ames.train, aes(x=Latitude, y=Sale_Price)) +
geom_point(alpha=0.2) +
geom_smooth(method=lm, formula = y ~ ns(x, df=deg_free),
color = "lightblue", se=F) +
labs(title = paste(deg_free, "Spline Terms"), y="Sale Price")}
(plot_smoother(2) + plot_smoother(5))/(plot_smoother(20) + plot_smoother(100))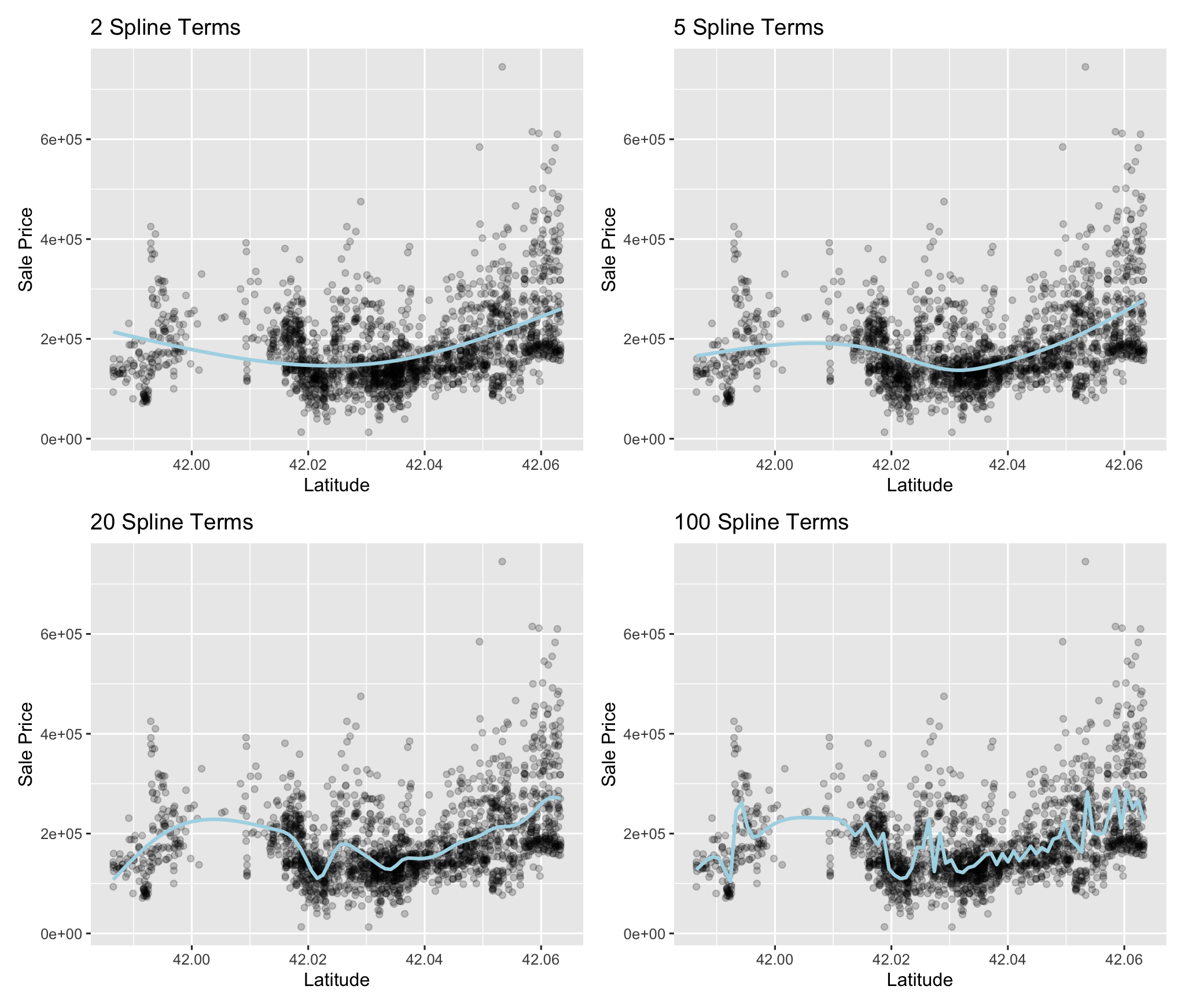
- Latitude와 Sale_Price는 비선형적인 관계를 가지는 것으로 보입니다. 이때, 자유도 5나 20을 가지는 모델이 적절해 보입니다.
- 따라서 step_ns(Latitude, deg_free = 5)를 통해 레피시에 추가할 수 있습니다.
- Feature Extraction : representing multiple features at once
- step_pca : Principal Component Analysis
- step_pls : PLS
- step_ica : Independent Component Analysis
- step_nnmf : Non-Negative matrix factorization
- step_umap : UMAP(비선형 차원 축소 기법)
- step_kmeans : K-Means Clustering Variable Reduction
- Feature scaling & Imputation
- step_range : normalization(정규화)
- step_normalize : standardization(표준화)
- 주성분분석(PCA), 군집분석(Clustering), KNN, SVM, Ridge&Lasso 전 스케일링 추천
- step_impute_roll : Impute numeric data using a rolling window statistics
- step_impute_mean : Impute numeric data using the mean
- step_impute_median : Impute numeric data using the median
- step_impute_linear : Impute numeric data via sub linear model
- step_impute_bag : impute via bagged trees
- step_impute_knn : impute via KNN model
- step_ts_impute : Missing data imputation for Time-Series
- Sub-Sampling : Under-Sampling & Over-Sampling 수행하며 인자 skip=T를 통해 predict 함수 사용시 적용하지 않음
- themis::step_downsample : Under-Sampling
- themis::step_tomek : Under-Sampling
- themis::step_upsample : Over-Sampling
- themis::step_smote : Over-Sampling
- themis::step_bsmote : Over-Sampling
- themis::step_rose : Over-Sampling
- (* 각 기법에 대한 설명은 https://casa-de-feel.tistory.com/15 를 참고하면 좋을 것 같습니다!)
- Filtering & Distribution Transformation
- step_zv : Zero-Variance Filter
- step_nzv : Near zero-variance FIlter
- step_naomit : remove missing values
- step_corr : High Correlation Filter
- step_YeoJohnson : Yeo-Johnson Transformation (데이터의 분포를 정규분포와 유사하도록 변형)
- step_BoxCox : Box-Cox Transformation (데이터의 분포를 정규분포와 유사하도록 변형)
(* Yeo-Johnson은 Box-Cox 방법과 다르게 데이터의 값이 음수이더라도 사용가능하다는 장점이 있습니다.) - step_time / step_date : 시간형 변수(date/datetime/time)형의 요소를 지정한 요소별로 분할
- step_hai_scale_zero_one : [0, 1]사이로 rescaling(정규화, Normalization)
- step_hai_fourier(_distance) : 푸리에 변환
data <- tibble(num = c(0,1,2,3,4,5,6,7,8,9,10))
recipe(~num, data=data) |>
healthyR.ai::step_hai_scale_zero_one(num) |>
prep() |> bake(data)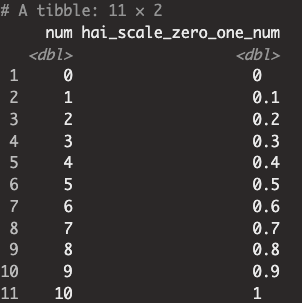
- Mathematical Operation & dplyr-like style
- step_log : 로그변환
- step_sqrt : 제곱근 적용
- step_relu : relu 함수 적용
- step_logit : 로짓 함수 적용
- step_window : Moving window functions
- step_mutate : dplyr::mutate style
- step_arrange : dplyr::arrange style
- step_select : select variables
- step_rename : Rename variables
- step_slice : Filter rows
- step_lag : lagged predictor
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 10. Resampling (0) | 2023.10.01 |
|---|---|
| [Tidy Modeling with R] 9. Performance Metrics (모델 성과 지표) (0) | 2023.09.27 |
| [Tidy Modeling with R] 7. Model Workflow (0) | 2023.09.13 |
| [Tidy Modeling with R] 6. Model Fitting with parsnip (0) | 2023.09.11 |
| [Tidy Modeling with R] 5. 데이터 분할 (1) | 2023.09.10 |