이번 포스팅에서는 parsnip 패키지를 이용한 모델 구축에 대해 알아보겠습니다.
parsnip 패키지는 타이디(=일관성 있고)하고 통합된 모델 구축의 인터페이스를 제공합니다.

1. 모델 생성 및 학습 (Creating Model and Training)
일단 데이터가 모델링에 사용할 수 있게 인코딩이 된다면, 모델링 적합을 위해 사용할 수 있습니다.
첫 모델로 선형 회귀에 대해 생각해봅시다. 선형회귀에서는 종속변수가 정량적인 수치로 구성되어 있고, 독립변수의 효과는 아래와 같이 회귀식의 회귀계수(기울기)와 절편으로 표현할 수 있습니다.
$$y_i = \beta_0 +\beta_1*x_1 + \beta_2*x_2 + \dots + \beta_p*x_p$$
회귀계수를 추정하기 위해서 다양한 방법들이 있는데요. 대표적으로 OLS 회귀분석은 최소제곱법을 사용하여 모델의 회귀계수를 추정하며, 정규화 선형회귀(Regularized linear regression)는 벌점화 회귀분석이라고도 불리며 최소제곱법에 L1, L2 패널티항을 추가하여 회귀계수의 값을 0으로 만들거나 0에 가깝게 shrink(수축)하면서 회귀계수를 추정합니다.
본문에서는 3가지의 함수를 소개하는데 아래와 같습니다.
- lm(formula, data, ...) : syntax for OLS regression
- rstanarm::stan_glm(formula, data, family="guassian", ...) : syntax for Bayesian Regularized linear regression
- glmnet::glmnet(x=matrix, y=vector, family="guassian", ...) : syntax for non-Bayesian Regularized linear regression
실제로 모델 적합을 하다보면 glmnet을 자주 사용하게 되는데 다른 함수와 다르게 formula 형식으로 제공할 수 없고 독립변수 x를 matrix 형식으로 제공해야한다는 점이 조금 번거롭습니다.
parsnip은 이처럼 패키지마다 인터페이스나 구문이 다른 문제점을 해결하는데 초점을 두고 있으며 tidymodel에서 모델을 지정하는 방식이 아래와 같이 통합되었습니다.
1. 수학적 구조를 기초로 하는 모델의 타입을 지정할 것 (선형회귀, 랜덤포레스트 등등) --> linear_reg, rand_forest, etc..
2. 모델을 적합하기 위한 엔진을 지정할 것 (stan_glm, glmnet 등등) --> set_engine(engine)
3. (옵션) 모델의 결과의 유형을 지정할 것 (Regression, Classification) --> set_mode(mode)
- Classification의 경우에는 factor형으로 인코딩되어 있어야 합니다.
- 데이터를 참조하지 않고 생성됩니다.
위에서 소개한 3가지의 선형 회귀 함수를 tidymodels를 사용하면 다음과 같이 모델을 생성할 수 있으며 translate 함수를 사용해 어떻게 엔진(패키지)에 맞게 변환되었는지 확인할 수 있습니다. 아래 결과를 보면 missing_arg( )라고 나와있는데, 이는 아직 데이터가 제공되지 않은 플레이스 홀더를 의미합니다. (데이터를 아직 참조하지 않았으므로 값이 비워있는걸 나타내는 겁니다!)
linear_reg() %>% set_engine(engine = "lm")
linear_reg() %>% set_engine(engine = "glmnet")
linear_reg() %>% set_engine(engine = "stan")
linear_reg() %>% set_engine(engine = "lm") %>% translate()
모델이 생성된 후 fit(formula) 함수와 fit_xy(x, y) 함수를 사용하여 데이터를 학습시킬 수 있습니다.
ames.split <- ames %>% rsample::initial_split(strata = Sale_Price)
ames.train <- ames.split %>% training()
ames.test <- ames.split %>% testing()
mymodel <- linear_reg() %>%
set_engine(engine = "lm") %>%
set_mode(mode="regression")
mymodel.fit <- mymodel %>%
fit(Sale_Price ~ Longitude + Latitude,
data = ames.train)
mymodel.fit2 <- mymodel %>%
fit_xy(x = ames.train %>% select(Longitude, Latitude),
y = ames.train %>% select(Sale_Price))- 1~3번째 줄의 코드는 ames 데이터를 training set & testing set으로 분할하는 코드입니다.
- mymodel은 회귀모델 객체입니다
- mymodel.fit, mymodel.fit2는 각각 fit, fit_xy 함수를 사용하여 적합된 결과로 회귀계수의 값이 같습니다.
Parsnip은 서로 다른 패키지에 대해 통합된 인터페이스를 제공할 뿐만 아니라, 동일한 모델 인자(파라미터)명을 사용합니다.
일반적으로 같은 모델을 적용시키더라도 패키지마다 파라미터(인자)명이 다른 경우가 있는데 parsnip은 동일한 이름을 사용하므로 모델 구축 시에 편리하다는 장점이 있습니다. 예를 들어 책에서 소개한 ranger, randomForest, sparklyr 패키지의 랜덤포레스트 모델에서 같은 역할을 하는 파라미터명은 조금씩 다르지만, parsnip에서는 동일한 파라미터명을 제공하여 쉽게 모델을 구축할 수 있게 됩니다. 또한, 파라미터명으로 전문적인 용어를 사용하기 보다는 평범한 사람이 알아들을 수 있도록 파라미터명을 지정한 것이 특징입니다.


이를 확인하기 위해서 ranger 패키지와 randomForest 패키지에서 제공하는 함수를 사용해 랜덤포레스트를 적합해보겠습니다.
동일한 파라미터명(trees, min_n, mtry)을 제공하였으나 실제 각 패키지의 함수에서 요구하는 파라미터명에 정확하게 원하는 값이 들어간 것을 확인할 수 있습니다.
참고로, parsnip은 모델 파라미터를 main argument, engine argument로 구분하였으며 전자는 여러 엔진에 사용할 수 있으며 후자는 특정 엔진에만 사용할 수 있는 파라미터며 set_engine 함수 내의 점점점(...)에 전달하면 됩니다.
rand_forest(trees = 1000, min_n = 3, mtry = 5) %>%
set_engine("ranger") %>%
set_mode("regression") %>%
translate()
rand_forest(trees = 1000, min_n = 3, mtry = 5) %>%
set_engine("randomForest") %>%
set_mode("regression") %>%
translate()

2. 모델 결과 확인 (Use Model Result)
모델을 구축하고 학습시켰으면 parsnip 모델 객체에 여려 값들이 저장되어 있습니다. 그중 fit, preproc, spec을 포함한 여러 정보가 있는데 가장 관심있어하는 적합 결과인 fit을 표시하기 위해서는 extract_fit_engine( ) 함수를 사용할 수 있으며 tidy( ) 함수를 통해 회귀계수 뿐만 아니라 표준오차, 통계량, 유의확률을 데이터 프레임 형식으로 제공합니다. (기존 summary는 matrix 형식 제공)
mymodel.fit$fit
mymodel.fit %>% extract_fit_engine()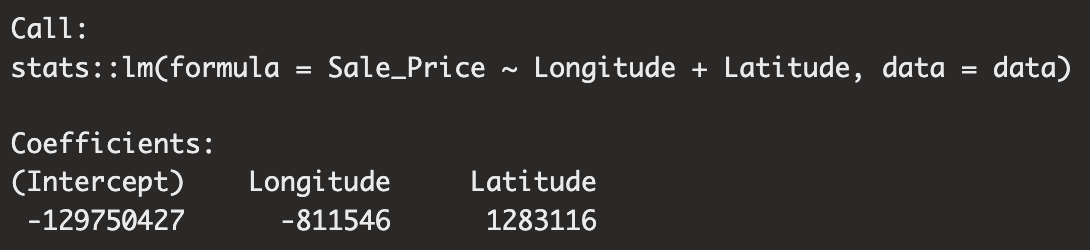
mymodel.fit %>% tidy()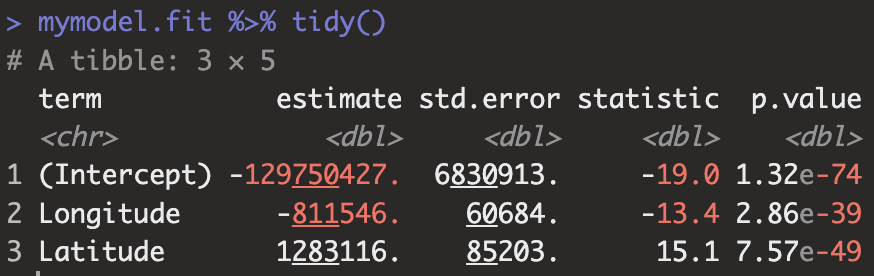
3. 예측(Predict)
Parsnip을 통해 구축하고 학습한 모델의 예측은 predict( ) 함수로 할 수 있으며 아래와 같은 특징을 가집니다.
- 반환값은 항상 tibble 객체 입니다
- 예측값이 포함된 열 이름은 항상 함수 predict의 인자 type에 따라 정해져 있습니다.
- 입력 데이터 셋의 크기만큼 예측값이 존재합니다.
아래 코드를 통해 testing set인 ames.test를 예측하면 ames.test의 데이터 개수만큼 예측값이 반환되며 예측의 행 순서는 ames.test 데이터 순서와 동일합니다.
mymodel.fit %>% predict(new_data = ames.test)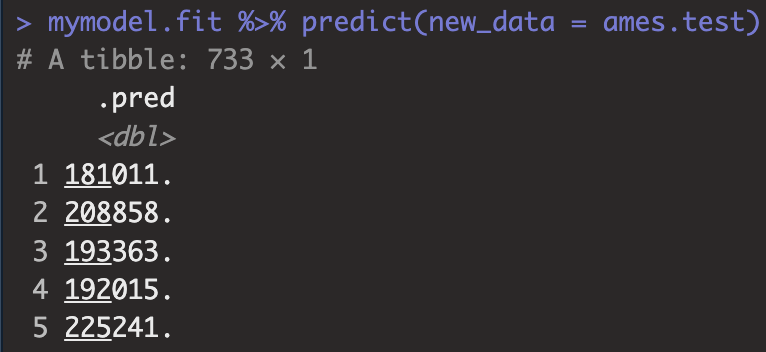
두번째 특징에서 언급했던 것 처럼, type 파리미터에 값을 조정함에 따라 원하는 출력물을 아래와 같이 얻을 수 있습니다.
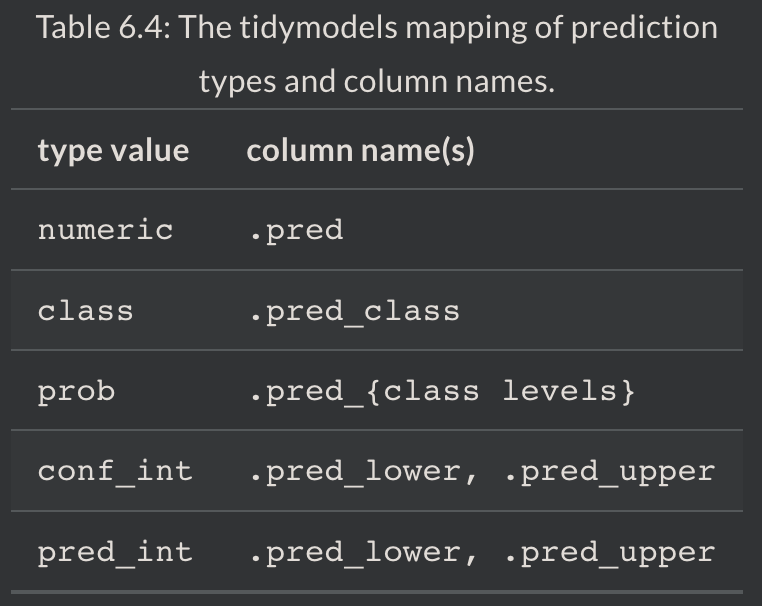
따라서 예측값과 신뢰구간을 구하고 bind_cols 함수를 사용하여 하나의 데이터 프레임으로 만들어줍니다.
ames.test %>%
bind_cols(mymodel.fit %>% predict(ames.test)) %>%
bind_cols(mymodel.fit %>% predict(ames.test, type="conf_int")) %>%
select(Sale_Price, matches("\\."))
마지막으로 parsnip에 어떤 엔진과 모델이 존재하는지 살펴보려면 parsnip_addin 함수를 사용하거나 아래 사이트를 참고해보세요!
tidymodels - Search parsnip models
To learn about the parsnip package, see Get Started: Build a Model. Use the tables below to find model types and engines. Resources Explore searchable tables of all tidymodels packages and functions. Study up on statistics and modeling with our comprehensi
www.tidymodels.org
6 Fitting Models with parsnip | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 8. Feature Engineering with Recipes (0) | 2023.09.21 |
|---|---|
| [Tidy Modeling with R] 7. Model Workflow (0) | 2023.09.13 |
| [Tidy Modeling with R] 5. 데이터 분할 (1) | 2023.09.10 |
| [Tidy Modeling with R] 4. 부동산 데이터 탐색적 분석 (1) | 2023.09.10 |
| [Tidy Modeling with R] 3. 모델링 기본 원리 (0) | 2023.09.09 |