4. EDA
본 포스팅에서는 모델링에 활용할 미국 아이오와주 에임스(Ames) 지역의 주택 가격 데이터를 살펴보겠습니다.
전체적인 흐름은 『Tidy Modeling with R』의 4장을 참고했으며, 이해를 돕기 위해 필요한 설명을 추가했습니다.
4 The Ames Housing Data | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
EDA(Exploratory Data Analysis)는 데이터의 품질을 검증하고, 모델링을 위한 전처리 조건을 확인하는 과정을 말합니다.
이 단계에서는 주로 요약통계, 시각화를 많이 사용하게 됩니다.
단순히 데이터를 보는 것을 넘어, 결측치나 클래스 불균형을 어떻게 처리할지 고민하는 과정에서 데이터에 대한 이해도를 높이고 인사이트를 얻을 수 있습니다. 신뢰할 수 있는 모델을 만들기 위해 모델링 구축보다 더 많은 시간을 투자해야 하는 중요한 단계입니다.
4.1 데이터 구조
데이터를 불러온 후 가장 먼저 할 일은 전체적인 구조를 파악하는 것입니다.
R에서는 대표적으로 `str`, `head`, `tail`, `summary` 함수 등을 사용하지만, 개인적으로는 skimr 패키지의 `skim` 함수를 추천합니다.
library(tidyverse)
library(tidymodels)
library(modeldata)
data(ames, package = "modeldata")
head(ames)
`skim` 함수를 사용하게 되면 변수 타입(numeric, factor)에 따라 요약 통계량을 분리해 표시해주고 히스토그램을 포함한 깔끔한 UI를 제공해 분포와 특성을 직관적으로 파악하기 편리합니다.
library(skimr)
skim(ames)

[데이터 타입 검증] 현재는 패키지에 내장된 정제된 데이터를 사용하고 있지만, 실제로는 CSV 파일 등을 직접 로드하는 경우가 많습니다. 이때 의도치 않게 숫자가 문자로 인식되는 등 파싱(Parsing) 오류가 발생할 수 있습니다.
따라서 `glimpse` 함수를 활용해 각 변수의 타입이 올바르게 설정되었는지 확인하는 습관을 들이는 것이 좋습니다.
glimpse(ames, width = 60)
확인 결과, 각 열이 적절한 타입으로 설정되어 있음을 알 수 있습니다.
`Ames` 데이터셋은 총 2930개의 행과 74개의 변수(열)로 구성되어 있으며, 주요 변수는 다음과 같습니다.
- 주택 특성 : 침실, 차고, 벽난로, 수영장, 현관
- 위치 정보
- 부지 정보 : 구역, 형태, 크기 등
- 품질 등급
- 판매 가격 : 반응변수(y)
4.2. 반응변수 분석
다음으로 모델링의 목표인 반응변수(Sale_Price)의 분포를 살펴보겠습니다.
반응 변수의 형태는 모델 선택과 전처리 방향을 결정하는 중요한 기준이 됩니다.
예를 들어 0과 1로 이루어진 이진형 변수라면 로지스틱 회귀를 연속형이라면 회귀모델을 사용해야하겠죠.
ames |>
ggplot(mapping=aes(x=Sale_Price)) +
geom_histogram(aes(y=after_stat(density)), bins = 100, color = "white") +
geom_density(color="red")
그래프를 보면 데이터가 왼쪽으로 치우치고 오른쪽 긴 고리를 가지는 right-skewed 분포임을 알 수 있습니다.
많은 경우에 데이터가 정규성을 따르는 경우 성능이 좋습니다.
따라서 지금 처럼 분포가 한쪽으로 치우치거나 분산이 일정하지 않은 경우에는 변환을 생각해볼 수 있는데요.
대표적으로 로그변환, 제곱근변환, Box-Cox 변환이 있습니다. 변환을 통해 분산을 안정화하고, 정규성을 향상할 수 있습니다.
오늘 적용할 박스콕스 변환의 식은 아래와 같습니다.
$$ x \text{ > 0에 대해 } g(x) = \begin{cases} \frac{x^\lambda - 1}{\lambda} &\text{if} \; \lambda \; \neq \; 0 \\ log(x) & \text{if} \; \lambda \; = \; 0 \end{cases} $$
R에서는 아래와 같이 <forecast> 패키지의 BoxCox 함수를 사용해서 적합할 수 있습니다.
library(forecast)
BoxCox.lambda(ames$Sale_Price)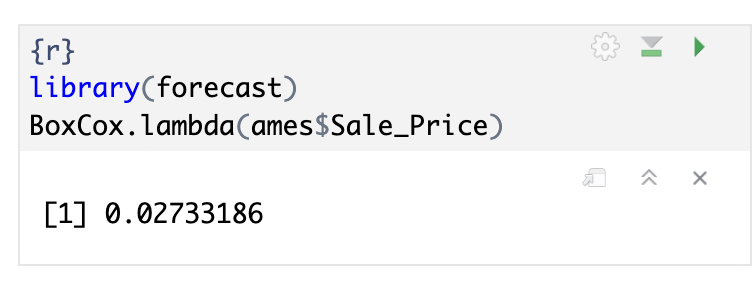
확인 결과 $\lambda = 0.02$로 0에 매우 가깝게 나오는 것을 확인할 수 있습니다.
따라서 로그변환 적용하기 전후를 비교해보도록 하겠습니다.
library(patchwork)
ames |>
ggplot(mapping=aes(sample=Sale_Price)) +
geom_qq(alpha=0.2) + geom_qq_line(color="red") +
labs(title = "로그변환 전 Sale_Price QQ Plot") -> p1
ames |>
ggplot(mapping=aes(sample=log(Sale_Price))) +
geom_qq(alpha=0.2) + geom_qq_line(color="red") +
labs(title = "로그변환된 Sale_Price QQ Plot") -> p2
p1 + p2
- Before: 데이터 점들이 붉은 실선(정규분포 기준선)에서 휘어져 있어 정규성을 크게 벗어난 모습입니다
- After: 로그 변환 후, 데이터 점들이 붉은 실선을 따라 직선에 가깝게 정렬되었습니다. 양쪽 끝 부분에서 약간의 이탈이 있지만, 전반적으로 정규성이 크게 개선되었음을 확인할 수 있습니다.
변환을 통해 모델의 성능(정규성)은 높일 수 있지만, 해석력(Interpretability)은 다소 떨어질 수 있습니다.
예를 들어, 모델이 예측한 값은 '로그가 취해진 집값'이므로, 이를 실제 금액으로 해석하려면 다시 지수 변환($\exp$)을 해주는 과정을 거쳐야 합니다.
ames <- ames |> mutate(Sale_price = log(Sale_Price))
4.3 결측값 (Missing Values)
결측치는 요약통계, 시각화를 왜곡하고 모델링 성능을 저하할 수 있는 만큼 초기에 확인하고 처리해야 합니다.
R에서는 다음과 같이 결측치의 현황을 파악할 수 있습니다.
- `sum(is.na(df))` : 전체 데이터셋의 총 결측치 개수
- `map_df(df, ~sum(is.na(.)))` : 각 열별 결측치 개수
- `df[ !complete.cases(df), ]` : 결측치가 하나라도 존재하는 행 추출
여기서는 결측 패턴의 분포를 확인하기 위해서 `naniar::vis_miss` 함수를 사용했습니다.
library(naniar)
vis_miss(ames)
다행히도 `Ames` 데이터 셋에서는 결측치가 발생하지 않았습니다.
실제 현업 데이터를 사용하게 되면 다수의 결측치를 마주하게 됩니다. 결측치가 발생했을 때의 구체적인 처리 방법(삭제, 대치 등)은 추후 별도의 포스팅으로 다루겠습니다.
(참고 : 4.1 데이터 구조 파트에서도 `skim()` 함수로도 결측치 개수를 확인할 수 있습니다.)
4.4 설명변수
4.4.1 불필요한 변수 제거
데이터에는 많은 변수가 존재하지만, 실제로 성능에 영향을 주는 변수는 많지 않습니다.
따라서 모델링에 도움이 되지 않는 변수를 선별해서 추후 분석에서 제외하는 습관이 중요합니다.
여기서는 `Utilities` 변수를 분석에서 제외하였는데요.
데이터 분포를 확인해 본 결과, 전체 2930건 중 약 99.9%인 2927건이 `AllPub`이라는 하나의 값에 편중되어 있었습니다.
이처럼 분산(Variance)가 거의 없는 변수(Near Zero Variance)는 모델이 패턴을 학습하는 데 유의미한 정보를 제공하지 못하므로 제거하는 것이 효율적입니다.

4.4.1 산점도 행렬
변수 간의 관계를 한눈에 파악하기 위해 산점도 행렬을 그려보겠습니다.
여러 함수가 존재하지만 개인적으로 패키지의 그래픽 문법을 사용할 수 있어서 다양한 표현이 가능한 `GGally::ggpairs` 함수를 추천합니다.
모든 변수를 시각화하면 가독성이 떨어져, 주요 변수만 추려서 확인해봤습니다.
library(GGally)
GGally::ggpairs(data = ames |> select(Lot_Area, Year_Built, Year_Sold, Gr_Liv_Area,
Garage_Area, Pool_Area, Sale_Price, Longitude, Latitude), progress = F)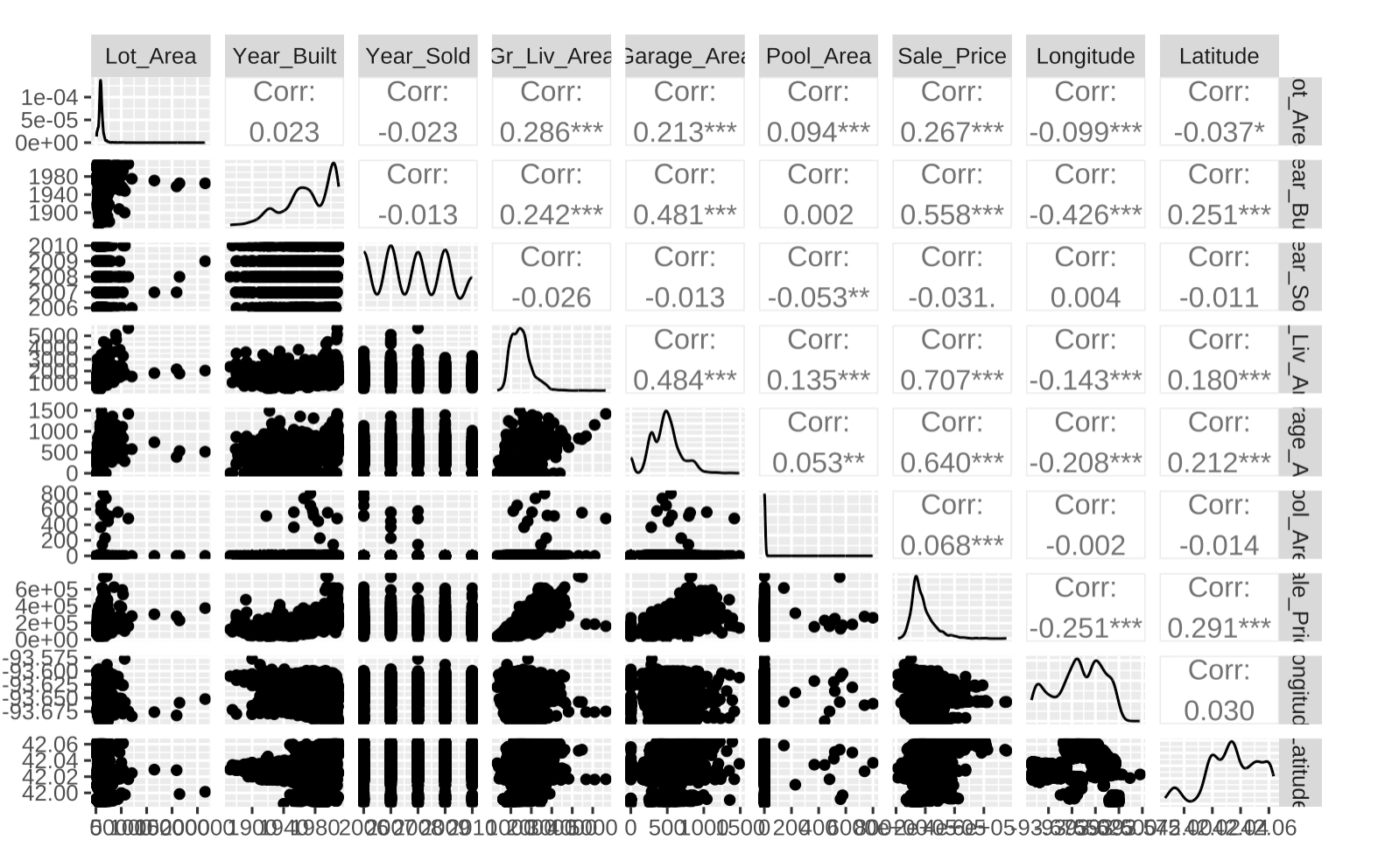
`Lot_Area`나 `Pool_Area`의 경우 대부분의 값이 0이나 특정 구간에 몰려 있고, 일부 극단값이 존재하는 Skewed 분포를 보입니다.
4.4.2 상관관계 시각화
마지막으로 변수 간 상관관계를 확인합니다.
GGally::ggcorr(ames |> select(Lot_Area, Year_Built, Year_Sold, Gr_Liv_Area,
Garage_Area, Pool_Area, Sale_Price, Longitude, Latitude),
label = T, label_round = 2)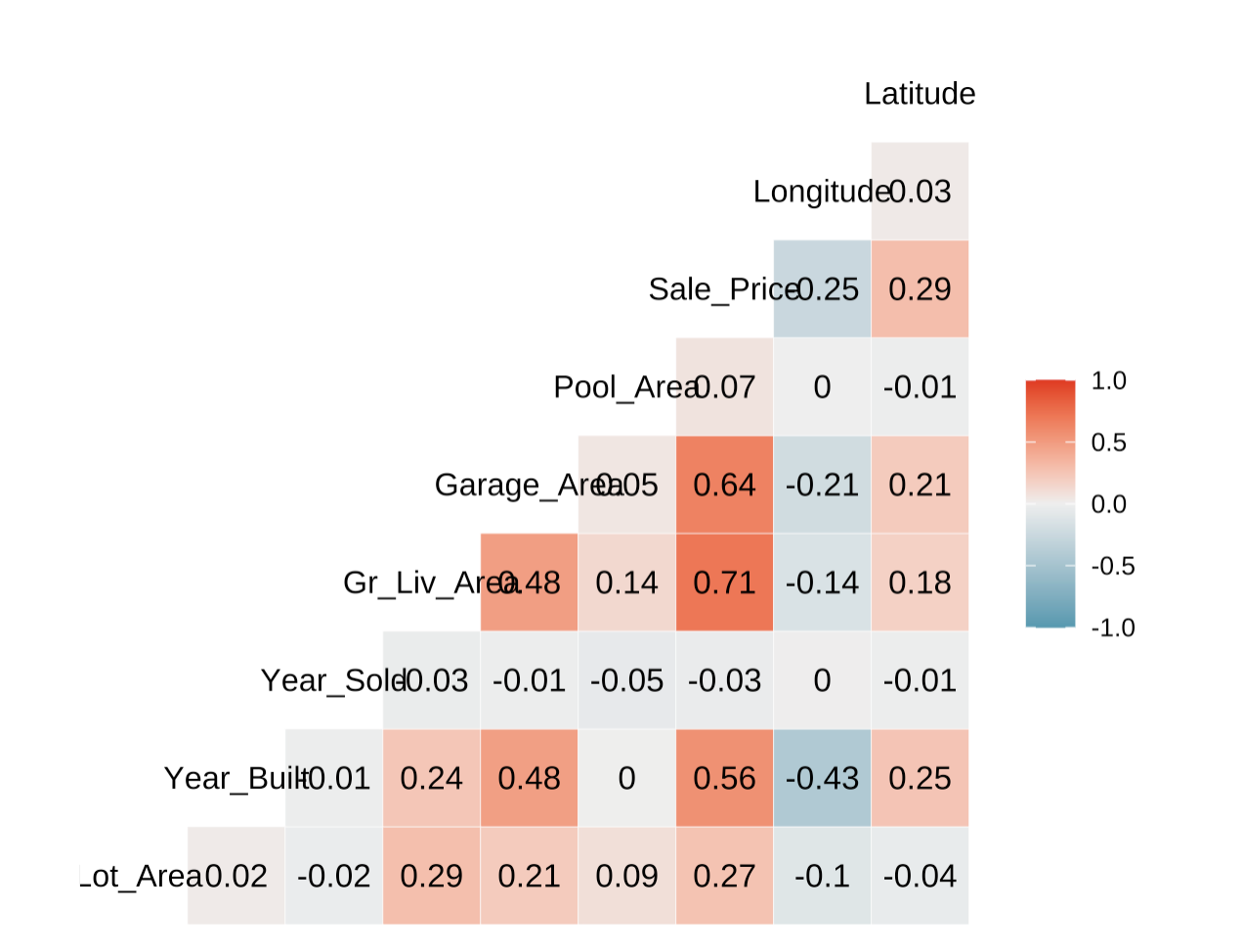
반응변수인 `Sale_Price`는 `Garage_Area`(차고면적), `Gr_Liv_Area`(거주면적), `Year_Bulit`(건축연도)와 뚜렷한 양의 상관관계를 보이고 있습니다.
또한, 설명변수끼리도 높은 상관관계를 보이는 쌍들이 존재해 추후 모델링 시 다중공선성 문제가 발생할 수 있으므로 주의 깊게 살펴볼 필요가 있음을 암시합니다.
4.5 지리적 정보 시각화
집 값은 지리적 요소에 영향을 많이 받는 것으로 알려져 있습니다.
`Ames` 데이터셋에는 `Neighborhood`와 `longitude`(경도), `latitude`(위도) 변수가 지리적 정보에 해당되는데요.
이를 <ggmap> 패키지를 활용하여 시각적으로 표현했습니다.
1. (지도 중심 좌표 설정) 적절한 지도를 불러오기 위해서 아래와 같이 위도와 경도의 중앙값을 구해주었습니다.
center <- ames |> summarise(lon = median(Longitude),lat = median(Latitude))
print(center)
2. (API 키 발급 및 설정) 지도 시각화를 위해 <ggmap> 패키지를 로드했습니다.
사용하기 앞서 Google Cloud Platform (GCP)에서 API 키를 발급받아야 합니다. (결제 계정 등록이 필요합니다!)
설정 후 아래 사진과 같이 API 및 서비스 접속하신 다음에 사용자 인증 정보탭에 API키 - 키표시 누르면 API를 확인할 수 있습니다.

library(ggmap)
ggmap::register_google(key = "API키를 입력하세요")
ggmap_hide_api_key()
mymap <- get_googlemap(center=c(center$lon, center$lat), urlonly = F,
maptype = "hybrid", zoom = 12, color="color", source="google",
extent = "device")
ggmap(mymap) +
geom_point(data=ames, mapping=aes(x=Longitude, y=Latitude, color=Neighborhood), alpha=0.2) +
theme(legend.position = "none")

- `ggmap::get_googlemap`을 통해 시각화 할 지도 이미지를 불러옵니다.
- `ames`에 존재하는 위도와 경도를 사용해 위치를 표현했으며 Neighborhood 변수를 통해 색을 지정하였습니다.
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 6. Model Fitting with parsnip (0) | 2023.09.11 |
|---|---|
| [Tidy Modeling with R] 5. 데이터 분할 (1) | 2023.09.10 |
| [Tidy Modeling with R] 3. 모델링 기본 원리 (0) | 2023.09.09 |
| [Tidy Modeling with R] 2. Tidyverse (0) | 2023.09.07 |
| [Tidy Modeling with R] 1. 모델링을 위한 소프트웨어 (0) | 2023.09.07 |