0. R Modeling Fundamentals
Base R을 활용해 모델 생성, 학습, 예측 과정을 진행합니다.
본문에는 없지만 이해를 위해서 Formula에 대해 조금 구체적으로 작성하였습니다.
3 A Review of R Modeling Fundamentals | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
3.1 Formula
3.1.1. 기본
모델링 학습 단계에서 반응변수(`y`)와 설명변수(`X`)에 어떤 변수가 들어갈지 설정해야 합니다.
선형회귀 함수 `lm`을 포함한 대부분의 모델링 함수에는 formula 파라미터를 통해 이를 설정할 수 있습니다.
- $ y \sim x $
위 formula는 물결표(~) 왼쪽에 있는 `y`는 반응변수로 오른쪽에 있는 `x`는 설명변수로 설정하겠다는 의미입니다.
이처럼 formula 항을 통해 변수간의 관계를 상징적(Symbolic)으로 표현할 수 있습니다.
3.1.2 설명변수가 여러개 존재할 때 (Feat. 범주형 변수 처리)
만약 여러개의 설명변수를 설정하고 싶으면 아래와 같이 나타낼 수 있습니다.
- $y \sim x_1 + x_2$
$x_1$과 $x_2$를 설명변수로 설정하지만, 두 설명변수 간에는 추가적인 관계를 포함하지 않습니다.
여기서 $x_2$가 문자형 변수라면 어떻게 할까요?
대부분의 모델은 문자열을 제대로 처리할 수 없습니다. 따라서 문자형 변수를 처리할 수 있도록 변환해줘야 합니다.
대표적으로 더미변수가 있는데요, 특정 범주에 속하는지 여부를 나타내는 항을 나타냅니다.
R에서는 처음 문자열(범주)를 기준으로 두고 그다음 값부터 더미변수로 추가합니다.
이는 아래 사진처럼 내부적으로 기존 데이터(왼쪽)을 오른쪽과 같이 처리됨을 의미합니다.

Species가 O. niveus인지 나타내는 더미변수가 생성되었으므로 종이 다르다면 다른 절편을 가지게 됩니다.
이러한 방식으로 여러개의 설명변수를 추가할 수 있으며 설명변수로 범주형 변수를 추가하는 경우 (범주수-1) 개의 더미변수로 변환됩니다.
(범주의 수만큼 더미변수를 생성하면 디자인 행렬 X의 열이 선형 종속 관계에 있어서 Full rank가 안 나옵니다.
Full rank가 아니면 역행렬이 존재하지 않아 일반해를 구할 수 없게 됩니다. 따라서 (범주수-1) 개의 더미변수를 만들어야 합니다.)
3.1.3 상호작용항
또한, 상호작용항(Interaction)을 추가하기 위해 다음과 같은 3개의 formula를 적용할 수 있습니다.
- $y \sim x_1 + x_2 + x_1:x_2$
- $y \sim (x_1 + x_2) \text{^} 2$
- $y \sim x_1*x_2$
개인적으로 2번째 방식을 선호하지만 다양하게 사용합니다. 이 경우 아래와 같이 내부적으로 처리됩니다.

3.1.4 그외 Formula 기능
추가적으로 formula는 표시변수(Indicate Variable)를 자동으로 생성할 뿐만 아니라 아래와 같은 편의성을 제공합니다.
- In-Line 함수를 formula에 사용할 수 있습니다. (Eg. $ y \sim log(x) $ )
- R은 formula 내부에 사용할 수 있는 다양한 함수를 제공하고 있습니다. (Eg. poly, ns function)
- 많은 변수가 있는 경우 dot(.)을 사용한 축약 표현을 통해 반응 변수를 제외한 모든 변수들을 지칭할 수 있습니다.
- `I( )` 함수를 사용해 수식 표현을 그대로 포함할 수 있습니다.
- 빼기(-) 기호를 사용해 특정 변수를 표현식에서 제거할 수 있습니다.
참고로 $y \sim x + x^2$은 $y \sim x$와 같으므로 $y \sim x + I(x^2)$ 로 해야합니다.
이는 formula가 symbolic 해서 `^` 기호가 다항식을 의미하는 것이 아닌 관계를 나타내는 기호이기 때문입니다.
3.2 예시
3.2.1 데이터 시각화 및 가설 설정
본문과 동일하게 주변 온도와 귀뚜라미가 1분당 울음소리 횟수 간의 관계에 대한 실험 데이터를 사용해 보겠습니다. 데이터는 두 종의 귀뚜라미(O. exclamationis와 O. niveus)에 대해 수집되었습니다.
<ggplot2> 패키지를 사용해 온도와 1분당 울음소리 속도(이하 속도) 간의 관계를 종(Species)에 따라 시각화할 수 있습니다.
비록 O.exclamationis 종에서 오른쪽 끝부분에서 비선형적인 관계가 일부 있으나 대체적으로 온도와 속도는 상당히 선형적인 경향을 보이는 것을 확인할 수 있습니다.
crickets |>
ggplot(mapping = aes(x=temp, y=rate)) +
geom_point(aes(color = species, shape = species), size=2) +
geom_smooth(method = "loess", aes(color = species, linetype = species), se = F) +
scale_color_brewer(palette = "Paired") +
theme(legend.position = "top") +
labs(x = "Temperature (C)", y = "Chirp Rate (per minute)")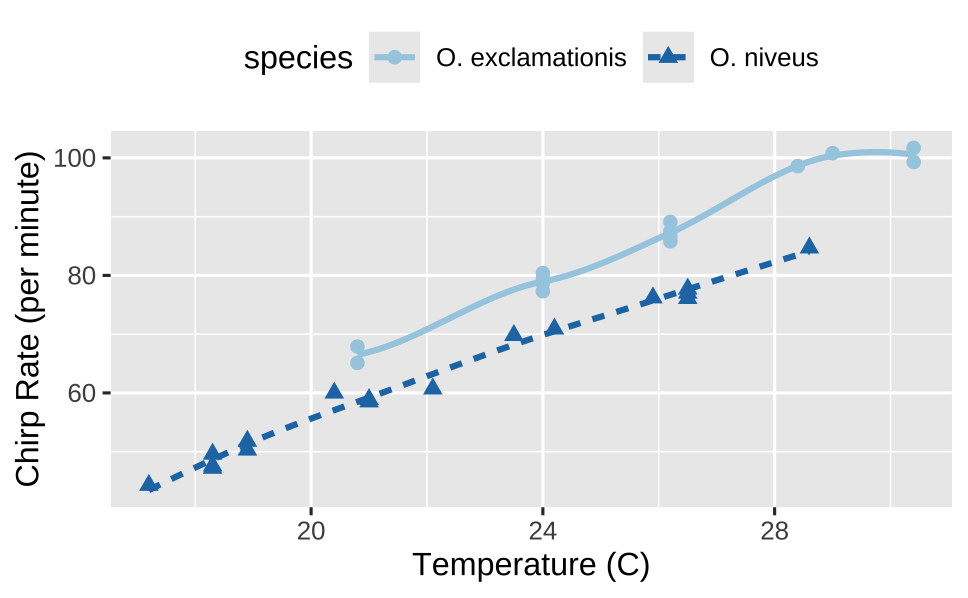
여기서 크게 3가지의 가설을 설정해 볼 수 있습니다.
- Rate와 Temp가 선형적인가?
- 상호작용항은 필요한가?
- 종에 따라 Rate에 차이가 있는가?
3.2.2 선형적인가?
우선 $H_0$ : Rate와 Temp가 선형적이다 를 확인하기 위해 상호작용항이 포함된 모델을 생성합니다.
interaction_fit <- lm(rate ~ temp * species, data = crickets)
interaction_fit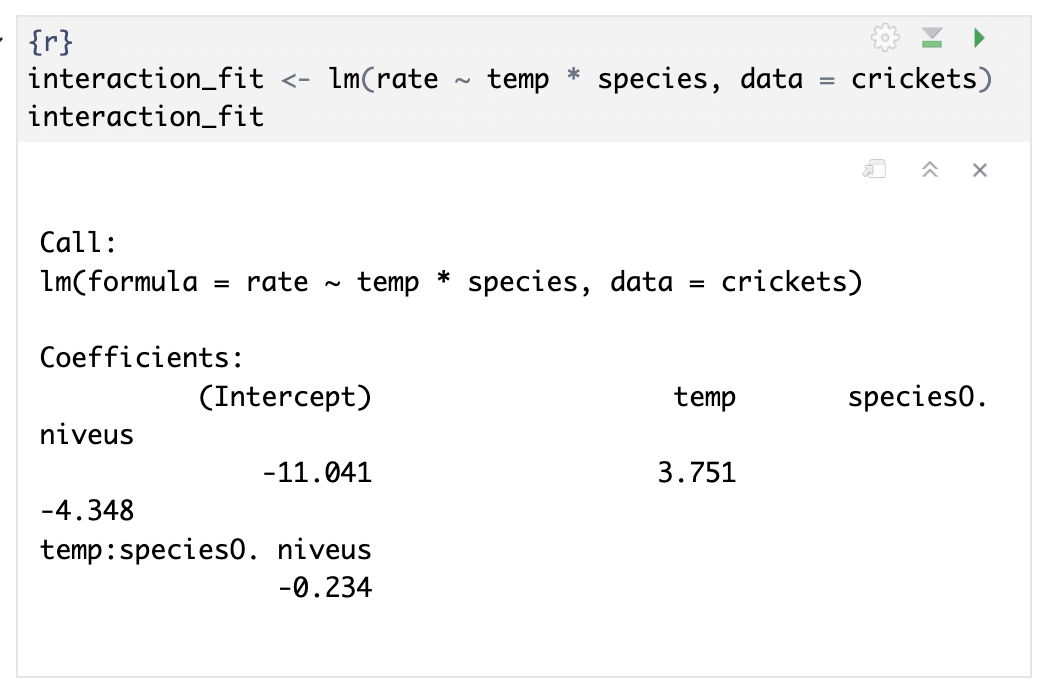

잔차–예측값 플롯에서 뚜렷한 패턴이 관찰되지 않았고, Q-Q plot 및 Shapiro–Wilk 검정 결과 잔차가 정규성을 위배하지는 않는 것으로 나타났습니다.
따라서 상호작용항이 포함된 선형회귀모형은 선형성 및 정규성 가정을 충족하며, 데이터는 선형모델로 해석 가능합니다.
3.2.3 상호작용항이 필요한가?
상호작용항이 있는 모델에서 상호작용이 필요한지 검정하기 위해 주효과(Main effect)만 추가한 모델을 생성합니다.
main_effect_fit <- lm(rate ~ temp + species, data = crickets)
main_effect_fit
이제 anova 함수를 사용해 검정할 수 있습니다.
원리는 Full model (여기서는 상호작용항 포함된 모델)에서 Reduced Model (여기서는 주효과만 포함된 모델)로 축소시킬 수 있는지 통계적으로 검정합니다.
구체적으로는 잔차제곱합(RSS)과 자유도의 차이를 사용합니다.
물론 Full Model이 추가적인 항이 포함되어 있어서 RSS가 낮게 나오지만 자유도를 통해 보정함으로써 실제로 유의한 지를 판단합니다.
anova(main_effect_fit, interaction_fit)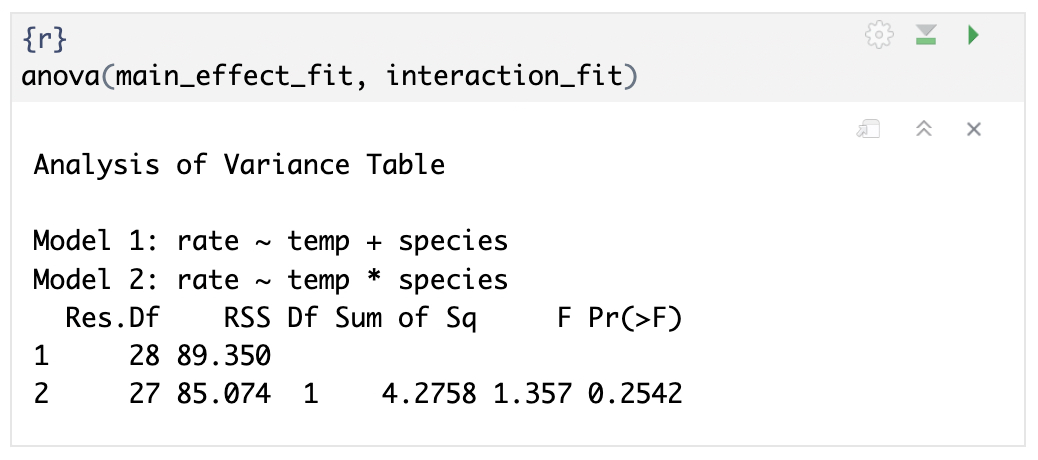
p-value가 0.25로 유의 수준($\alpha$, 0.05) 보다 크므로 귀무가설을 채택합니다.
즉, Full model에서 Reduced Model로 축소할 수 있다는 결론을 얻을 수 있습니다.
3.2.4 종에 따라 차이가 있는가?
따라서, 상호작용항이 없는 주효과만 포함된 모델에서 회귀계수와 통계량을 summary 함수를 통해 살펴보면 아래와 같습니다.
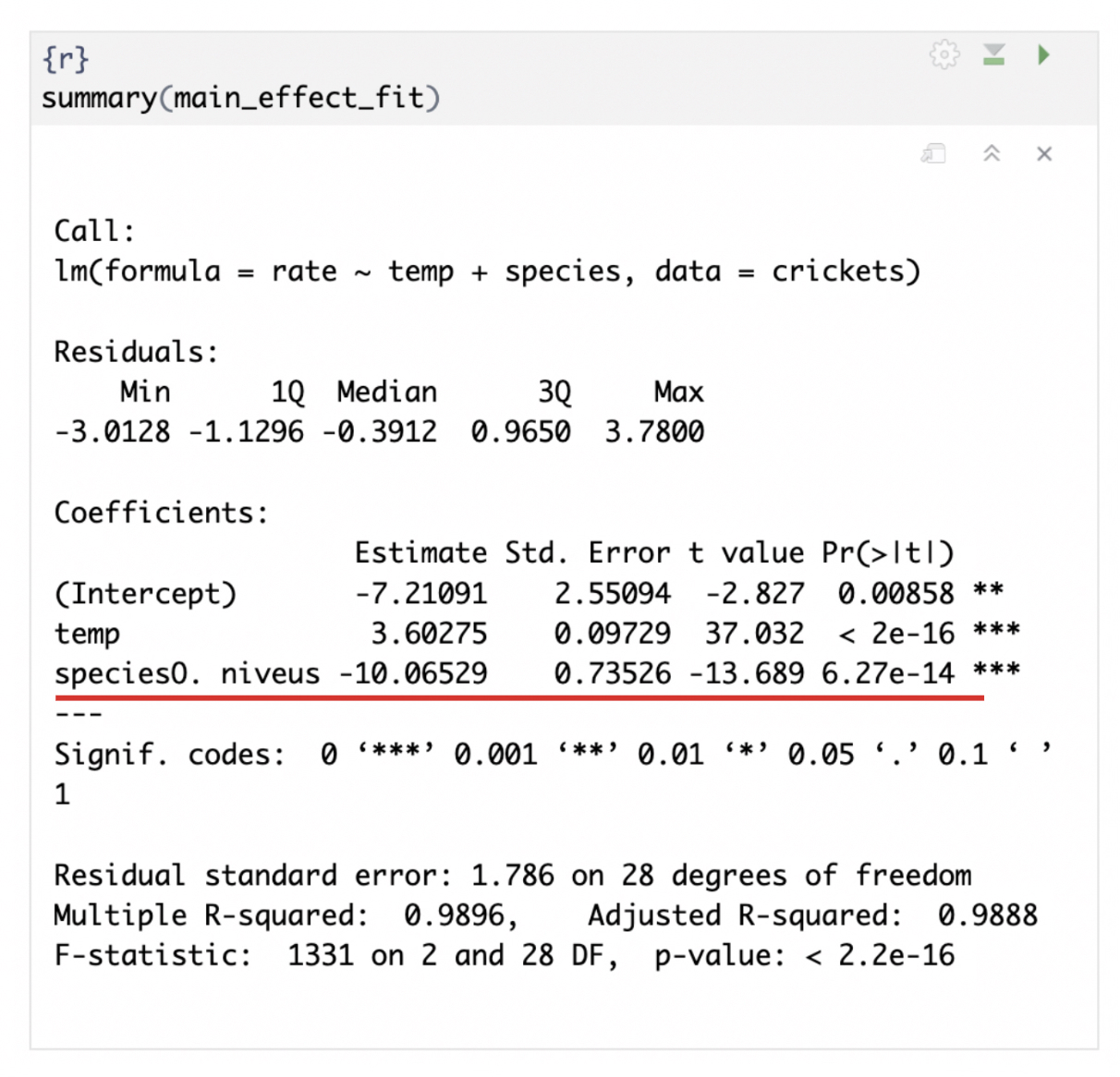
만약 종에 따라 Rate에 차이가 있다면 더미변수의 계수가 0이 되어야 합니다.
하지만, 계수의 p-value가 유의 수준인 0.05보다 작으므로 계수가 0이라고 할 수 없습니다.
따라서 종에 따라 차이가 존재하고 특히 0. niveus 종인 경우에 동일한 조건에서 Rate가 10.06만큼 낮은 것을 확인할 수 있습니다.
참고로 위 식에서 $rate = 3.6 * temp-10*I(species == 0.niveus)-7.2$라는 수식을 얻을 수 있습니다.
3. 3 참고
상호작용항이 있는 모델과, 상호작용항이 없는 주효과만 있는 모델 중 어느 것을 선택해야 할까요?
한 가지 방법은 가능도비 검정(likelihood ratio test)을 이용하여 복잡한 모델과 단순한 모델의 가능도비를 계산하는 것으로 귀무가설은 "단순한 모델이 복잡한 모델처럼 데이터를 잘 설명한다"입니다.
따라서 귀무가설을 채택하면 모델을 복잡한 모델에서 단순한 모델로 축약할 수 있으며, 귀무가설을 기각하면 복잡한 모델에서 단순한 모델로 축약할 수 있는 증거가 없으므로 복잡한 모델을 쓰는 것이 맞습니다.
다만 해당 내용은 통계파트에서 다루는 것이 적절하다고 생각해서 자세한 내용은 생략하겠습니다.
R에서는 anova함수 또는 lrtest 함수를 사용해서 검정을 수행할 수 있습니다.
main_effect_fit <- lm(rate~temp+species, data=crickets)
anova(interaction_fit1, main_effect_fit, test="LRT")
lmtest::lrtest(main_effect_fit, interaction_fit1)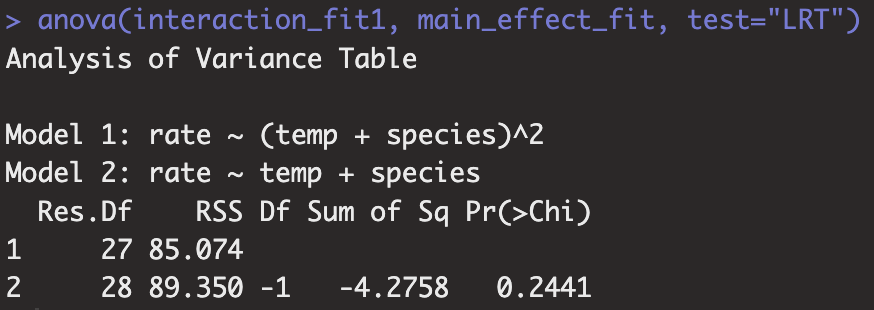

각각 0.2441, 0.2176의 유의확률을 가지므로 0.05 유의수준하에서 귀무가설을 채택할 수 있습니다. 따라서 단순한 모델인 교호작용항이 없는 모델이 복잡한 모델인 교호작용항이 있는 모델처럼 데이터를 잘 적합하므로 상호작용항이 모델에 유의하지 않음을 알 수 있습니다.
+ 2025.10 내용변경(구성 변경 및 예시 추가)
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 5. 데이터 분할 (1) | 2023.09.10 |
|---|---|
| [Tidy Modeling with R] 4. 부동산 데이터 탐색적 분석 (1) | 2023.09.10 |
| [Tidy Modeling with R] 2. Tidyverse (0) | 2023.09.07 |
| [Tidy Modeling with R] 1. 모델링을 위한 소프트웨어 (0) | 2023.09.07 |
| [Tidy Modeling with R] 0. 서론 (1) | 2023.09.07 |