모델을 구축하는 과정에는 파라미터 추정, 모델 선택, 하이퍼파라미터 튜닝, 성능 평가 등 여러 단계가 포함됩니다.
사용할 수 있는 데이터의 양은 유한하다는 점입니다.
『Tidy Modeling with R』 에서는 이를 Data Budget(데이터 예산)이라는 개념으로 설명합니다.
한정된 데이터를 여러 단계에서 반복적으로 사용하게 되면, 모델의 성능이 제대로 나오지 않을 위험이 커지게 됩니다.
예를 들어, 모델 학습에 사용한 데이터를 그대로 평가에 사용한다면 실제보다 훨씬 좋아 보이는 성능이 측정될 수 있습니다.
이는 시험 문제를 미리 알고 푸는 것과 유사하며, 정보 누수(data leakage)의 대표적인 사례입니다.
이번 블로그에서는 이러한 문제를 방지하기 위한 데이터 분할(data splitting)을 살펴봅니다.
5 Spending our Data | Tidy Modeling with R
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. This book provides a thorough introduction to how to use tidymodels, and an outline of good methodology and statistical practice for phases
www.tmwr.org
0. 요약
- 1. `rsample::initial_split` -단순 무작위 추출법(Simple Random Sampling) 활용
- 2. `rsample::initial_split(strata)`-계층 추출법(Stratified Sampling) 활용
- 3. `rsample::initial_time_split` - 시계열 데이터 분할
- 4. `rsample::initial_validation_split` - train/validation/test split
- 5. `rsample::vfold_cv` - K Fold 교차검증 (Chapter 10)
1. 초기 데이터 분할을 위한 일반적인 방법
1. 기본 개념
모델 검증을 위한 기본 접근 방식은 전체 데이터를 Training set(훈련셋)과 Testing set(테스트셋) 두가지 셋으로 나누는 것입니다.
훈련 데이터는 일반적으로 데이터의 대부분을 차지하고 있으며 모델을 개발하거나 최적화하는데 사용합니다.
반면 테스트 데이터는 데이터의 작은 부분으로 최종적으로 선택된 하나 또는 두개의 모델에 대해 성능을 확인하는데 사용됩니다.
따라서 테스트 데이터는 한 번만 사용되는 것이 적절합니다.
2. 단순 무작위 추출
만약, 전체 데이터의 80%를 Training set, 나머지 20%를 Testing set에 할당한다고 가정해봅시다.
가장 일반적인 방법은 단순 무작위 추출법(Simple Random Sampling)을 사용하는 것입니다.
이를 R에서는 `rsample::initial_split` 함수를 통해 구현할 수 있는데, 인수로 데이터 프레임과 훈련 데이터 셋에 할당할 비율을 지정하면 됩니다.
이제 Ames housing data set을 이용하여 Training set에 80%, Testing set에 20%를 할당해봅시다.
library(tidymodels)
library(tidyverse)
ames_split <- rsample::initial_split(ames, prop=0.8)
ames_split
initial_sample을 사용한 결과를 보면 rsplit 클래스를 가지는 리스트를 반환하는데요.
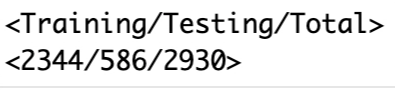
전체 2930개의 데이터에서 2344개의 데이터가 Training set, 586개의 데이터가 Testing set에 할당된 것을 알 수 있습니다.
여기서 개별 데이터 셋을 얻기 위해 `training( )`, `testing( )` 함수를 사용하면 됩니다.
ames_train <- ames_split |> training()
ames_test <- ames_split |> testing()
dim(ames_train)
dim(ames_test)분리된 training set과 testing set은 기존 데이터의 모든 열을 포함하고 있지만, 서로 중복되는 행을 가지지 않습니다.
3. 계층 추출
참고로 단순 무작위 추출법은 대부분의 경우에 적절한 접근 방법이지만 예외가 있습니다.
클래스 불균형(Class imbalance, 범주별로 빈도의 차이가 존재)이 심하다면 단순 무작위 추출법을 사용할 때,
소수 클래스(Minority Class)가 Training set이나 Testing set 중 한쪽에만 몰려서 아예 포함되지 않는 문제가 발생할 수 있습니다.
이는 모델 학습이나 평가시 문제를 발생할 수 있으므로 Stratified sampling(계층 샘플링)을 사용하는 것이 적절합니다.
왜냐하면 Train/Test 분할이 각 클래스별로 수행 후 결합되므로 Training set과 Testing set의 분포가 비슷해지기 때문입니다.
참고로 회귀 문제에서는 데이터를 특정 분위수를 사용해 구간을 분류하고 각 구간에 단순 샘플링을 적용한 후 결합합니다.
Stratified sampling은 `rsample::initial_split`에서 `strata`에 계층 샘플링이 적용될 변수를 지정함으로써 수행할 수 있습니다.
다음과 같은 성별을 나타내는 gender와 값을 나타내는 value가 있는 데이터 프레임을 생성해 봅시다.
아래 시각화처럼 여성의 데이터수는 3개, 남성의 데이터수는 27개로 클래스 불균형이 있는 데이터프레임입니다.
imbalance_df <- tibble(gender=rep(c("male","female"), times=c(27,3)),
value = rnorm(30))
imbalance_df |>
ggplot(mapping=aes(x=gender, fill=gender)) +
geom_bar() +
scale_fill_manual(values=c("male"="skyblue", "female"="pink"))
만약 해당 데이터를 단순 무작위 추출법을 사용하여 분할하면 어떻게 될까요?
imbalance_df.split <- imbalance_df |> rsample::initial_split(prop=0.7)
imbalance_df.split |> training() |> count(gender)
결과처럼 훈련데이터에 여성 데이터가 하나도 없는 결과가 나올 수도 있습니다.
이러면 모델 적합을 하더라도 여성 데이터가 없어서 여성 데이터를 예측할 때 문제가 될 수 있겠죠?
따라서 클래스 불균형이 있는 경우에는 다음과 같이 적합할 수 있습니다.
imbalance_df.split <- imbalance_df |> rsample::initial_split(prop=0.8, strata=gender)
imbalance_df.split |> training() |> count(gender)
마지막으로 시계열 데이터 분할도 생각할 수 있는데,
시계열 특성상 시간을 무작위로 나누는 것보다 시간 순서를 유지하여 분할하는것이 일반적이라
`initial_split` 함수보다는 `initial_time_split` 함수를 사용하여 분할하는 것이 좋습니다.
2. 검증 데이터 셋
앞서 최종 모델의 성능을 평가하는 데이터로 Testing set을 언급했습니다.
여기서 "테스트 데이터까지 성능을 측정하지 않으면 그 전까지 모델을 어떻게 평가하나요?"라는 궁금증이 생길 수 있습니다.
실제 딥러닝 분야에서 해당 질문에 대한 답으로 Validation set을 말합니다.
Validation set은 검증 데이터 셋으로 훈련중인 모델의 성능을 측정하는데 사용합니다.
Train/Validation/Test split는 R에서 `rsample::initial_validation_split`을 사용해서 구현할 수 있습니다.
ames_val_split <- ames |> initial_validation_split(prop=c(0.6, 0.2))
ames_val_split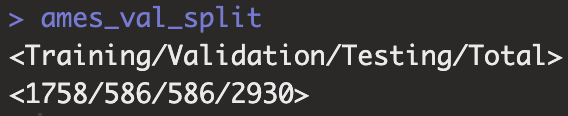
`initial_split`와 비슷하게 rsplit class를 가지는 리스트가 반환되며 Training set에는 1758(60%), Validation set에는 586(20%), Testing set에는 586(20%)개의 데이터가 할당 된것을 볼 수 있습니다.
여기서 데이터를 얻기 위해 `training( )`, `validation( )`, `testing( )` 함수를 사용하면 됩니다.
ames_train <- ames_val_split |> training()
ames_validation <- ames_val_split |> validation()
ames_test <- ames_val_split |> testing()
3. 다수준(Multi-level) 데이터
데이터 분할 방법을 선택할 때는 각 관측치가 서로 독립적이라는 가정이 성립하는지를 먼저 확인해야 합니다.
종단적 연구, 동일 객체의 반복 측정, 또는 계층 구조를 가지는 데이터의 경우 관측치 간 상관성이 존재할 수 있습니다.
이때 모델을 새로운 그룹에 일반화할 목적이라면, 단순 무작위 샘플링보다는 그룹 단위 분할(group-based sampling)을 적용하는 것이 적절합니다.
4. 데이터 분할 고려사항
- 모델 구축 단계에서 Testing set의 정보를 일절 사용하지 않아야함
- Training set과 Testing set은 별개의 객체에 저장해서 정보 유출 문제를 방지
- Testing set과 유사한 Training set으로 학습하는 경우에도 Testing set의 정보를 사용한 것으로 간주
- Testing set은 모델이 실제로 만날 데이터를 반영하고 있어야 한다.
- Testing set으로 최종 성능 평가를 마친 이후, 실제 배포용 최종 모델에 한해 Train, Validation, Test 데이터를 모두 사용해 재훈련할 수 있습니다.
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 7. Model Workflow (0) | 2023.09.13 |
|---|---|
| [Tidy Modeling with R] 6. Model Fitting with parsnip (0) | 2023.09.11 |
| [Tidy Modeling with R] 4. 부동산 데이터 탐색적 분석 (1) | 2023.09.10 |
| [Tidy Modeling with R] 3. 모델링 기본 원리 (0) | 2023.09.09 |
| [Tidy Modeling with R] 2. Tidyverse (0) | 2023.09.07 |