안녕하세요. 오랜만에 딥러닝을 주제로 글을 작성하네요!
이번 포스팅에서는 이미지 데이터를 처리하는 방법 중 합성곱 신경망에 대해 알아보려고 합니다.
합성곱 신경망은 이미지 또는 영상과 같은 시각적 데이터를 분석하는데 주로 사용되는 인공신경망의 한 종류로 필터링 기법을 적용하여 여러가지 필터들을 생성해내고 학습을 통해 필터들의 값들을 자동으로 조정하여 원하는 결과를 출력하는 방법입니다.
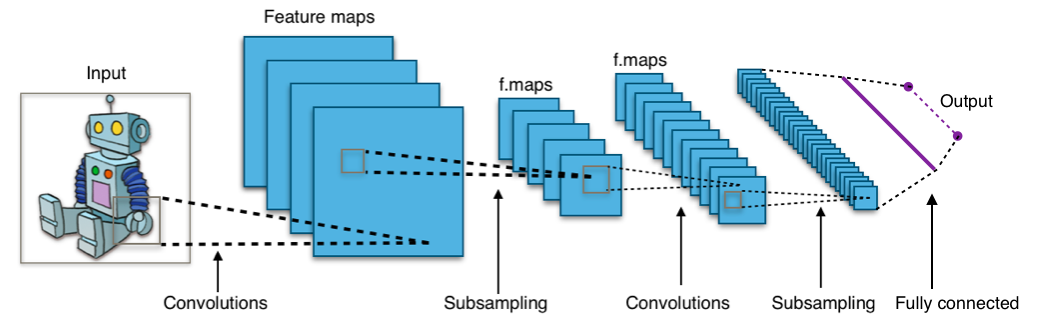
한편으로 이미지 분류를 위한 합성곱 신경망에는 크게 특징 추출기(Feature Extractor)와 분류기(Classifier)로 구분이 가능한데, 추출기에서는 이미지의 특징을 다차원으로 구분한 필터를 사용하여 새로운 이미지(feature map)를 생성합니다. 또한 추출기는 주로 합성곱 레이어와, 풀링 레이어가 혼합된 형태를 가지고 있습니다. 이때, 합성곱 레이어는 이미지 일부에 해당되는 픽셀에 해당되는 값과 주변 픽셀의 값을 사용하는데 이는 이미지 데이터에서 서로 가까이 이는 픽셀은 공간적으로 관련이 있다고 가정하기 때문입니다. 하여튼 이런 부분 이미지 값에 필터에 적용하여 이미지 특징을 추출하며 풀링 레이어에서는 이미지의 크기를 줄이면서 중요한 데이터만 남기는 서브샘플링 역할을 하고 있습니다. 각 레이어의 사용법과 파라미터는 아래 이미지에서 확인해주세요.

Fashion MNIST 데이터셋을 사용하여 CNN 모델을 학습시켜 보겠습니다.
우선 데이터를 불러와서 형태를 확인하고 시각화를 통해 어떤 데이터가 있는지 확인해 봅시다!
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_x, train_y), (test_x, test_y) = fashion_mnist.load_data()- fashion mnist 데이터를 불러오는 코드입니다.
train_x.shape
train_y.shape- train_x의 shape은 (60000, 28, 28)로 28*28 사이즈의 이미지 데이터를 60000개 가지고 있다고 볼 수 있겠습니다
- train_y의 shape은 (60000,)으로 train_x의 데이터 수에 해당하는 사이즈를 가지고 있네요!
# Min-Max Normalization
train_x = train_x / 255.0
test_x = test_x / 255.0- Min-Max Normalization을 수행하여 값들이 0~255가 아닌 0~1의 범위 내에 있도록 값을 조정하였습니다.
# 채널을 가지도록 shape 변경 (28,28) -> (28,28,1)
train_x = train_x.reshape(-1, 28, 28, 1)
test_x = test_x.reshape(-1, 28, 28, 1)- 또한, 일반적으로 이미지는 RGB 채널 3개가 있어서 (데이터수, 높이, 너비, 채널수)의 형태를 가지므로 흑백 이미지를 가지는 데이터도 유사하게 작업하기 위해 (데이터수, 높이, 너비, 1)의 형태로 바꿔주는 코드입니다.
- train_x.shape를 실행하면 (60000,28,28,1)이 나오는 것을 볼 수 있어요!
- 참고로 형태를 안바꾸고 28*28 데이터로 사용하셔도 상관없어요
# Visualization Dataset
import matplotlib.pyplot as plt
import random
plt.figure(figsize=(12,12))
for c in range(5*5) :
plt.subplot(5,5,c+1)
num = random.choice(range(len(train_x)))
plt.imshow(train_x[num].reshape(28,28), cmap="gray")
frame1 = plt.gca()
frame1.axes.xaxis.set_ticklabels([])
frame1.axes.yaxis.set_ticklabels([])
plt.show()
- 25개의 이미지를 랜덤하게 표시하는 코드입니다.
대략적으로 데이터를 scaling하고 이미지를 확인했으니 본격적으로 CNN 모델을 학습시켜 봅시다.
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=16, input_shape=(28,28,1)),
tf.keras.layers.MaxPool2D(strides=(2,2)),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=32),
tf.keras.layers.MaxPool2D(strides=(2,2)),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation="relu"),
tf.keras.layers.Dropout(rate=0.3),
tf.keras.layers.Dense(units=64, activation="relu"),
tf.keras.layers.Dropout(rate=0.3),
tf.keras.layers.Dense(units=10, activation="softmax")])
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss = tf.keras.losses.sparse_categorical_crossentropy,
metrics = ["accuracy"])
model.summary()- 앞서 설명한 것 처럼 Convolution Layer와 Pooling Layer를 혼합시켜 Feature Extractor를 구성하였습니다.
- 이때 Convolution Layer는 층을 쌓을수록 더 많은 필터를 가지도록 설정하여 많은 이미지 맵을 생성하도록 하였습니다.
- 또한, tf.keras.layers.Flatten()함수를 이용하여 Dense함수가 받아들일 수 있도록 데이터를 1차원으로 변환시켜주었습니다.
- 마지막으로 train_y, test_y가 0~9의 값을 가지므로 sparse_categorical_crossentropy 손실함수를 사용하여 적합합니다.

# Model Fitting
history = model.fit(train_x, train_y, epochs=25, validation_split=0.25,
callbacks=tf.keras.callbacks.EarlyStopping(patience=5, monitor="val_accuracy"))
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(history.history["loss"], "b-", label="loss")
plt.plot(history.history["val_loss"], "r--", label="val_loss")
plt.xlabel("Epoch")
plt.legend()
plt.subplot(1,2,2)
plt.plot(history.history["accuracy"], "b-", label="accuracy")
plt.plot(history.history["val_accuracy"], "r--", label="val_accuracy")
plt.xlabel("Epoch")
plt.legend()
plt.show()
- Train 데이터를 사용하여 학습한 결과입니다. 학습을 진행할수록 train data의 정확도는 증가하지만 validation data는 어느정도 일정한 모습을 보이고 있습니다.
model.evaluate(test_x, test_y, verbose=0)- 마지막으로 학습시키지 않은 평가용 데이터 test data를 사용하여 모델의 최종 성능을 확인해 보았습니다.
- [0.3534, 0.8898]로 모델의 손실값은 0.3534, 정확도는 88.98%로 상당히 잘 분류하는 것을 확인할 수 있습니다.
'AI > Deep Learning' 카테고리의 다른 글
| [Tensorflow] 5. 순환신경망(RNN, Recurrent Neural Network) (0) | 2023.08.21 |
|---|---|
| [밑시딥1] 챕터 5~8 요약 (0) | 2023.03.26 |
| [밑시딥1] 챕터 1~4 요약 (0) | 2023.03.26 |
| [Tensorflow] 3. 분류 (Classification) (0) | 2023.01.07 |
| [Tensorflow] 2-1 Regression with Boston housing datasets (0) | 2023.01.07 |