안녕하세요. R을 활용한 데이터 사이언스를 포스팅한지 벌써 6개월 정도 되었네요.
"R을 활용한 데이터과학(R4DS)" 책은 3년전부터 공부한 책이였지만 중간중간 어려서워서 나중에 다시 돌아와서 보기도 했었고, 5번정도 복습을 했지만 다시 볼때마다 유용한 내용이 많이 있었습니다.
특히 다양한 경험과 배움속에서 R 프로그래밍 역량을 좀 더 높여준 책이라서 저자와 번역가님에게 정말 감사드립니다.
하여튼 해당 책을 위주로 요약해서 포스팅하는 것은 이번이 마지막이지만, 요약 하지 않은 파트도 정말 도움이 많이되어 R을 사용한 데이터 사이언스에 관심있으신 분들은 한번쯤 구매해서 읽어보시면 많은 도움을 받을 수 있지 않을까 싶습니다.
Data Science With R의 마지막 포스팅은 리스트-열입니다.
데이터프레임은 다른 열끼리 다른 타입을 가져도 되지만 한가지 열에서는 같은 타입의 벡터를 가져야 한다는 점은 대부분 알고 계실거라고 생각합니다. 벡터는 크게 원자벡터와 리스트로 구분하는데, 원자 벡터의 유형은 논리형(Logical), 정수형(Integer), 실수형(Double), 복소수형(Complex), 원시형(Raw), 문자형(Character)이 있습니다. 리스트는 재귀(Recursive) 벡터라고 하는데 이는 리스트안에 다른 리스트가 포함될 수 있어서 그렇습니다. 즉 리스트도 벡터이므로 is.vector를 적용하면 참이 나오는 것을 확인할 수 있습니다.
이때, 데이터프레임은 리스트로 구성된 열을 가질 수 있는데 이를 리스트 열이라고 합니다...
백문이 불여일견이라고 했었나요. 우선 코드를 보면서 리스트열이 어떤 구조인지 확인해봅시다.
mpg_nested <- mpg %>%
group_by(manufacturer) %>% nest()
nest 함수를 이용해서 데이터를 중첩할 수 있는데, 위 코드에서는 manufacturer(제조사)를 기준으로 다른 데이터를 중첩해보았습니다.
우선 중첩된 데이터(중간이미지)를 보면 manufacturer이 열에 남아있고 나머지 변수들은 전부 data 내부의 데이터프레임에 포함되어 있습니다. 또한, manufacturer(제조사)가 audi(아우디)인 data를 확인해보면(오른쪽 이미지) 다른 제조사의 값이 들어가 있는 것이 아닌, 아우디의 데이터만 포함하고 있습니다. 즉, data는 데이터프레임의 리스트열이며 제조사를 제외한 변수를 포함하고 있는 데이터프레임으로 구성되어 있습니다.
이상태에서 각 제조사마다 hwy와 cty의 회귀모델을 적합해보겠습니다.
manufacturer_model <- function(df){lm(hwy~cty, data=df)}
mpg_nested %>%
mutate(model = purrr::map(data, manufacturer_model))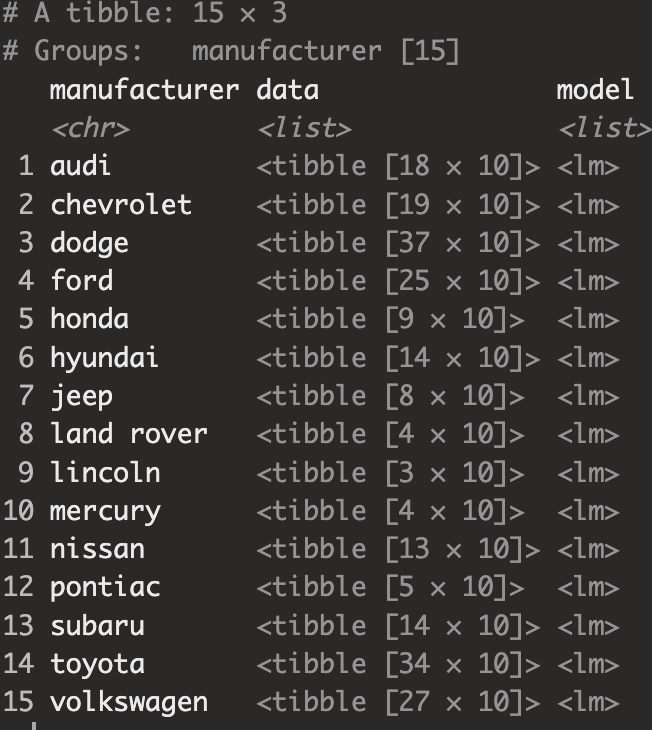
이렇게 하면 각 제조사별 고속도로 주행속도(hwy)와 시내 주행속도(cty)의 선형모형을 얻을 수 있습니다.
즉, 제조사수에 해당하는 15개의 회귀모형이 생성된 것을 볼 수 있습니다.
이제 제조사에 해당하는 데이터와 선형모델이 리스트열로 들어가 있으므로 예측값을 구해봅시다.
mpg_nested_pred <- mpg_nested %>%
mutate(lm_model = purrr::map(data, manufacturer_model)) %>%
mutate(pred = purrr::map2(data, lm_model, add_predictions))
- 기존 데이터프레임(data)에 예측값을 추가하여 pred에 해당하는 데이터프레임의 변수의 수가 1개 증가했습니다.
또한, 리스트열은 시각화할 때 어려운 점이 있어서 이제 unnest 함수를 사용해서 중첩을 풀어줍시다.
파라미터 cols를 사용해서 어떤 변수의 리스트열을 풀지 정할 수 있어서 여기서는 예측값이 포함된 pred 데이터만 풀어봅시다.
mpg_pred <- mpg_nested_pred %>% unnest(cols=c(pred))
각 제조사별 예측한 회귀선과 실제 데이터를 시각화하면 다음과 같습니다.
mpg_pred %>%
ggplot(mapping=aes(x=cty, hwy)) +
geom_point(alpha=0.6) +
geom_line(mapping=aes(x=cty, y=pred), color="red") +
facet_wrap(~manufacturer, ncol=4)
책에는 좀 더 복잡하고 자세한 설명이 나와 있으므로 관심있으신 분들을 한번 확인해보세요!
'Data Science > Manipulation' 카테고리의 다른 글
| [EDA] 상관계수 시각화 (Visualization of Correlation Coefficient) with R (0) | 2024.09.27 |
|---|---|
| [R] slice함수 : 위치를 이용한 행 선택 (Subset rows using position) (2) | 2023.09.06 |
| [R] all_of와 any_of를 사용한 변수 선택 (조건을 이용한 선택 추가) (1) | 2023.07.29 |
| [Data Science With R] 15. Modelr을 활용한 모델 생성 (0) | 2023.05.17 |
| [Data Science With R] 14. 반복수행 with purrr (0) | 2023.04.18 |