1. 라이브러리 로드 및 데이터 준비
아래와 같이 코드 실행에 필요한 라이브러리를 로드합니다.
### 라이브러리 로드
library(tidymodels)
library(tidyverse)
library(tidy.outliers)
library(baguette)
library(embed)
library(earth)
library(liver)
이번 모델링에는 하이퍼파라미터가 다수 존재하기 때문에, Train/Test set으로 분리한 후에 Train Data에 K=5인 k-fold CV를 적용하였습니다.
### 데이터 로드 및 분리
data(churn)
churn_data <- churn %>%
mutate_if(is.ordered, factor, ordered = FALSE)
churn_split <- initial_split(churn_data, strata = churn, prop = 3/4)
churn_train <- training(churn_split)
churn_folds <- churn_train %>% vfold_cv(v = 5)
churn_test <- testing(churn_split)
2. EDA(Explorative Data Analysis)
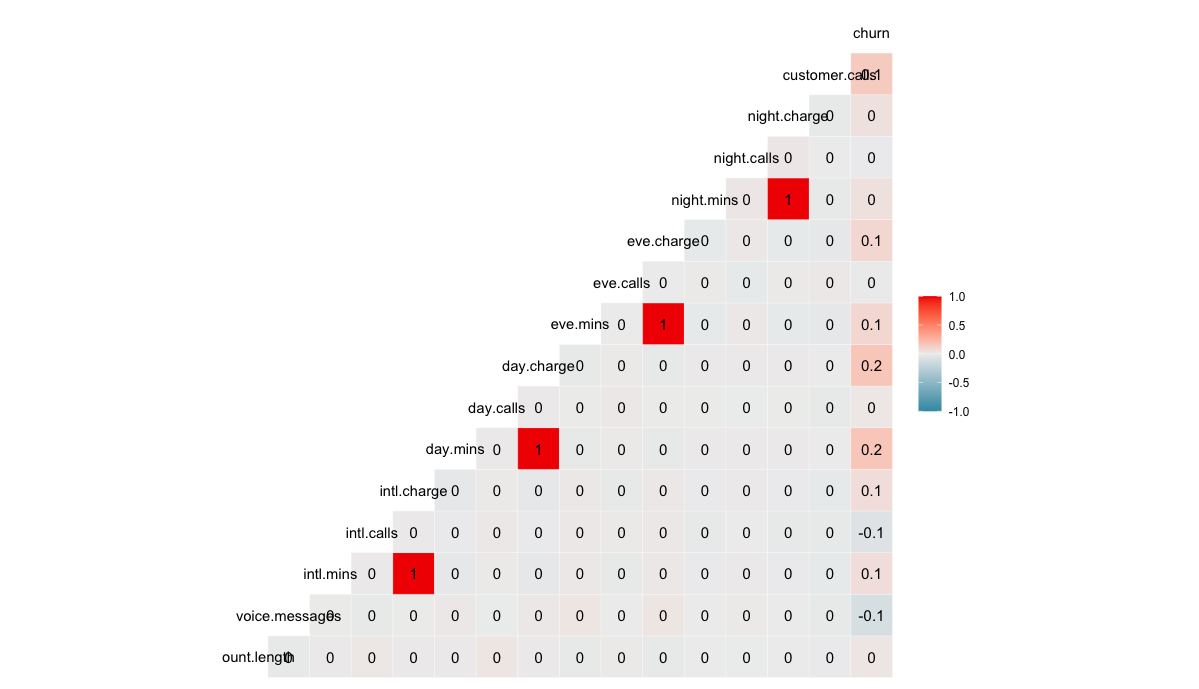
모델링을 하기전에 EDA를 간단하게 진행하였습니다. 우선 상관계수를 분석해보았는데, 1에 가까운 상관계수를 가지는 쌍이 4군데가 눈에 띄네요. 전처리로 PCA를 포함한 차원축소를 고려해봐야 할 듯 합니다.
GGally::ggcorr(churn %>% mutate(churn = ifelse(churn=="no",0, 1)) %>% keep(is.numeric),
angle=90, label=T, nbreaks = 10)
GGally::ggcorr(churn %>% mutate(churn = ifelse(churn=="no",0, 1)) %>% keep(is.numeric),
method = c("pairwise", "spearman"), label=T)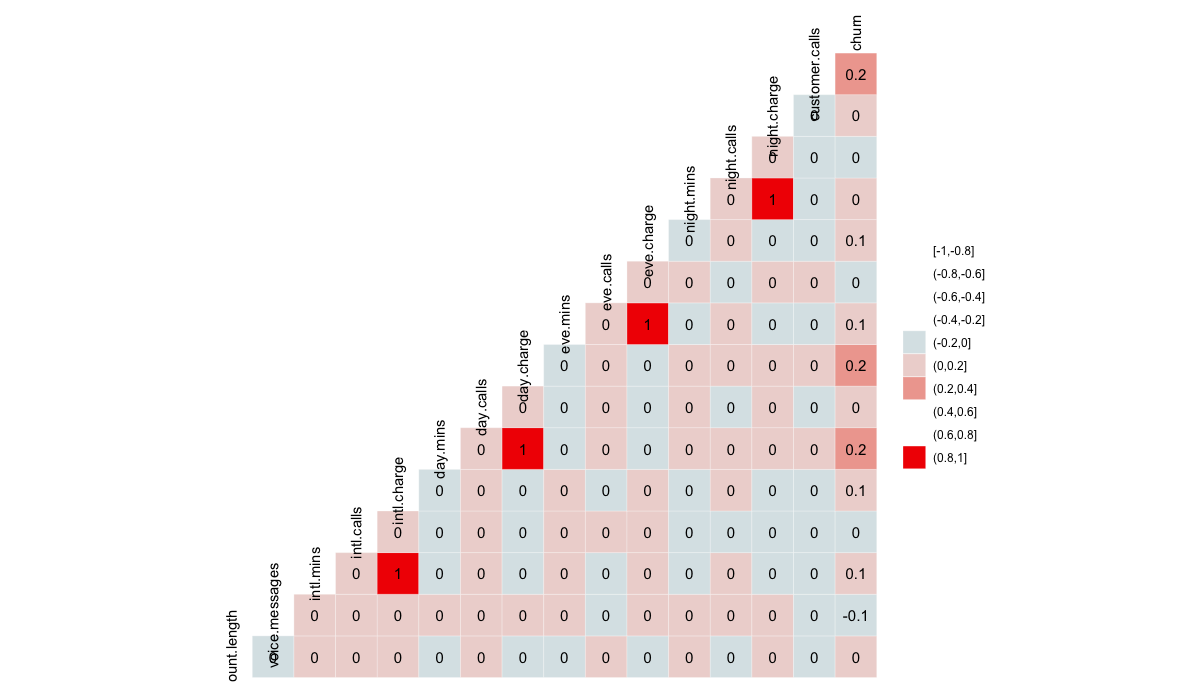
결측치를 위치랑 변수별로 보여주는 missmap 함수를 통해 시각화를 진행하였습니다. 다행히도 결측치는 없으므로 결측치 처리는 고려하지 않아도 될 것 같습니다.
Amelia::missmap(churn)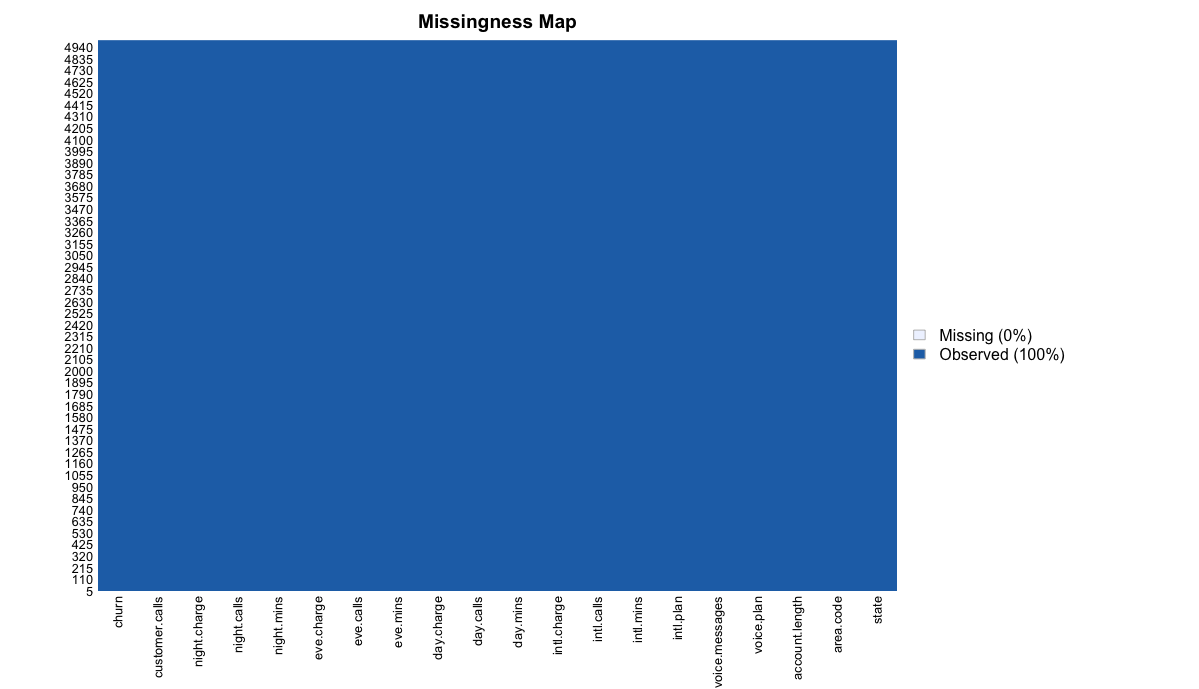
LV 박스 상자 그림을 통해 변수들의 스케일링을 비교해 보았습니다. 일반적으로 트리기반의 모델은 스캐일링에 Robust하다고 알려졌지만, 일부 극단적인 규모 차이에서 스캐일링 후 성능이 좋아졌다는 논문이 있으므로 추후에 정규화를 고려해보도록 하겠습니다.
churn %>% keep(is.numeric) %>% reshape2::melt() %>%
ggplot(mapping=aes(x=variable, y=value)) + lvplot::geom_lv()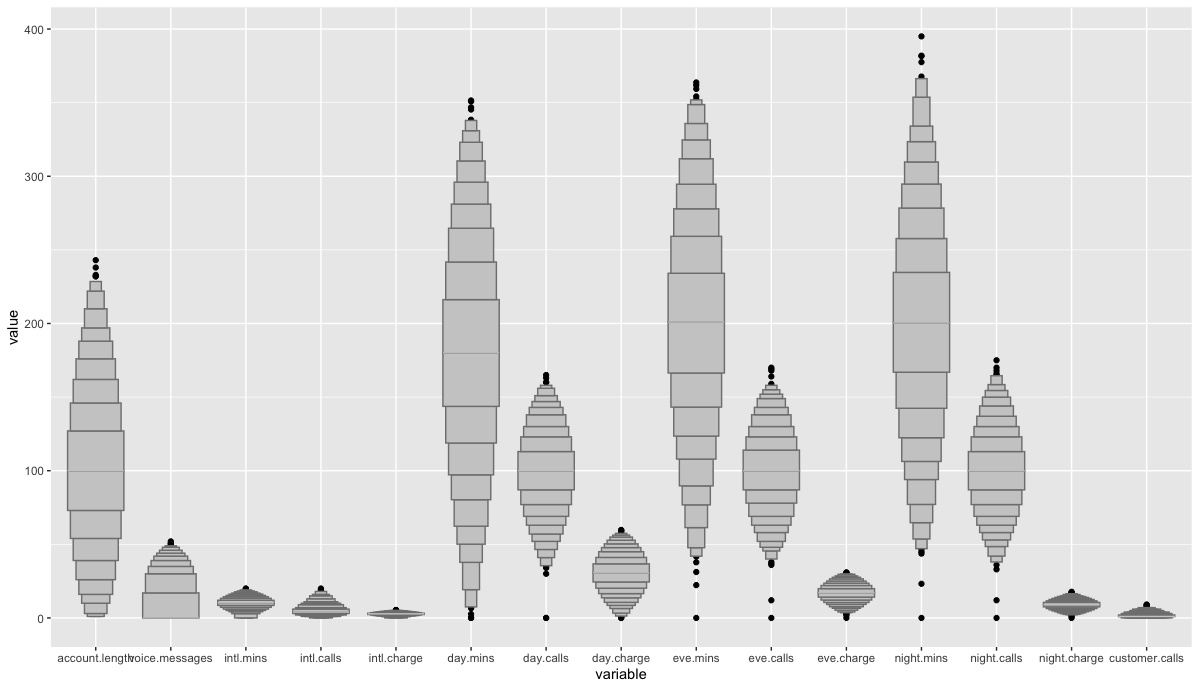
마지막으로 반응변수(churn)은 범주형 변수로 데이터 불균형 확인을 위해 시각화를 아래와 같이 하였습니다.
범주간의 관측치 수에 차이가 있으므로 Oversampling 혹은 UnderSampling을 고려해봅시다.
churn %>% ggplot(mapping=aes(x=fct_rev(churn), fill = churn)) + geom_bar()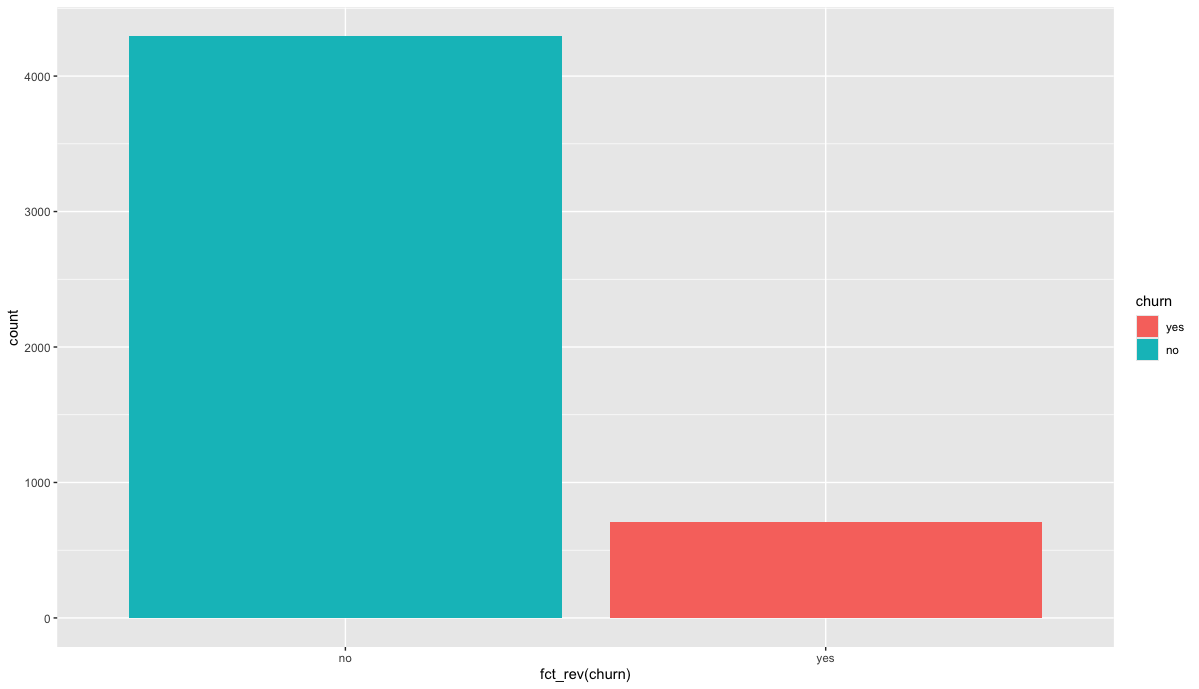
3. Modeling
모델에 필수적인 전처리기(Preprocessing)을 구성하는 Recipe 객체를 만들었으며 앞선 EDA의 결과로 고려하기로 한 차원축소(PCA)와 이상치 제거의 효과를 따로 측정하기 위해서 서로 다른 Recipe를 생성하였습니다.
이전에 언급한 것 처럼 트리모델은 스케일링에 영향을 받는 편은 아니지만 선택적으로 표준화(Standardization)을 진행하였으며 이진형 반응변수(churn)의 범주별로 관측치수에 차이가 있어서 Borderline-SMOTE기법을 적용하여 경계부분의 소수클래스 데이터를 보강하였습니다.
### Recipe Object
# 기본 레시피
basic_recipe <- recipe(churn ~ ., data = churn_train) %>%
step_rm(area.code) %>%
step_other(all_nominal_predictors(), -all_outcomes()) %>% # 범주 통합
step_dummy(all_nominal_predictors(), -all_outcomes()) %>% # One-Hot Encoding
step_center(all_numeric_predictors()) %>% # Standarization
step_scale(all_numeric_predictors()) %>% # Standarization
step_zv(all_predictors()) %>% # Zero-variance 변수 제거
themis::step_bsmote(all_outcomes()) # OverSampling Using Borderline-Smote
# 전처리 레시피 1 (이상치 제거, 변환)
recipe1 <- basic_recipe %>%
step_outliers_maha(all_numeric(), -all_outcomes()) # Anomraly Deleteion
# 전처리 레시피 2 (차원축소)
recipe2 <- basic_recipe %>%
step_pca(num_comp = tune())
# 전처리 레시피 3 (ALL)
total_recipe <- recipe1 %>%
step_pca(num_comp = tune())
이번 포스팅에서는 Bagging(Bootstrap Aggregation) Method를 적용한 MARS 모델, NN모델, Tree모델(CART, C5.0)에 대해 모델링을 진행하였습니다.
### 모델 스펙 설정
# bag_mars
bag_mars_spec <- bag_mars(
prod_degree = tune(id="prod_degree"), # 기저함수 최대 차수 (1~3)
num_terms = tune(id="num_terms")) %>%
set_engine("earth") %>%
set_mode("classification")
# bag_mlp
bag_mlp_spec <- bag_mlp(
hidden_units = tune("hidden_units"), # 은닉층 노드 수
penalty = tune("penalty"), # 가중치 규제
epochs = tune("epochs")) %>% # 학습 반복 횟수
set_engine("nnet") %>%
set_mode("classification")
# bag_tree (rpart)
bag_tree_rpart_spec <- bag_tree(
tree_depth = tune("tree_depth"), # 트리 깊이
min_n = tune("min_n"), # 최소 노드 관측치 수
cost_complexity = tune("cost")) %>% # Cost-Complexity
set_engine("rpart") %>%
set_mode("classification")
# bag_tree (C5.0)
bag_tree_c50_spec <- bag_tree(
min_n = tune("min_n")) %>%
set_engine("C5.0") %>%
set_mode("classification")
모델 명세와 전처리기를 생성하였으므로 workflow set을 아래와 같이 생성할 수 있습니다.
# workflow_set 적용
churn_workflows <- workflow_set(
preproc = list(basic = basic_recipe,
recipe1 = recipe1,
recipe2 = recipe2,
total = total_recipe),
models = list(
mars = bag_mars_spec,
mlp = bag_mlp_spec,
tree_rpart = bag_tree_rpart_spec,
tree_c50 = bag_tree_c50_spec))
튜닝이 필요한 워크플로의 하이퍼파라미터 수정을 위해 반복문을 사용하였고, 차원축소가 포함된 모델의 하이퍼파라미터를 지정하여 업데이트 진행하였습니다. param_list에 있는 객체는 하이퍼파라미터를 수정한 객체를 가지고 있으므로 option_add 함수를 통해서 반복적으로 workflow set에 있는 객체에 수정된 하이퍼파라미터를 추가해주었습니다. (수정해서 option열에 opts[1]로 바뀜)
param_list <- list()
for(name in churn_workflows$wflow_id){
workflow_obj <- churn_workflows %>% extract_workflow(id = name)
param_list[[name]] <- workflow_obj %>% extract_parameter_set_dials()
if(str_detect(name, pattern = "recipe2_*")){
param_list[[name]] <- param_list[[name]] %>% update(num_comp = num_comp(c(1, ncol(churn_train)-1)))
} else if(str_detect(name, pattern = "total_")){
param_list[[name]] <- param_list[[name]] %>% update(num_comp = num_comp(c(1, ncol(churn_train)-1)))
}
}
for(i in seq_along(param_list)){
churn_workflows <- churn_workflows %>% option_add(param_info = param_list[[i]], id = names(param_list)[i])
}
이제 모델과 전처리기가 준비된 워크플로우셋의 준비를 완료하여, 각 워크플로별로 함수를 지정하는 workflow_map 함수를 사용해서 Grid Search(그리드서치) 방식으로 1차적으로 하이퍼파라미터 튜닝을 진행하였습니다.
# Grid search를 통한 하이퍼파라미터 튜닝 수행
grid_ctrl <- control_grid(save_pred = F, parallel_over = "everything", save_workflow = T, verbose = T)
grid_results <- churn_workflows %>% arrange(desc(wflow_id)) %>%
workflow_map(fn="tune_grid", resamples = churn_folds, grid = 25, control = grid_ctrl, verbose=T)
grid_results %>% rank_results() %>% head(20)
튜닝된 결과를 아래와 같이 시각화하였고, 이진 분류 문제이므로 brier score를 기준으로 정렬하였습니다. Decision Tree 기반의 Bagging 방법이 MARS 기반 Bagging, NN 기반 Bagging 방법보다 우수한 것을 확인할 수 있습니다.
상위 모델에 대해서 Accuracy(정확도)는 95%정도 나오는 것을 확인할 수 있습니다.
grid_results %>% autoplot(rank_metric = "brier_class")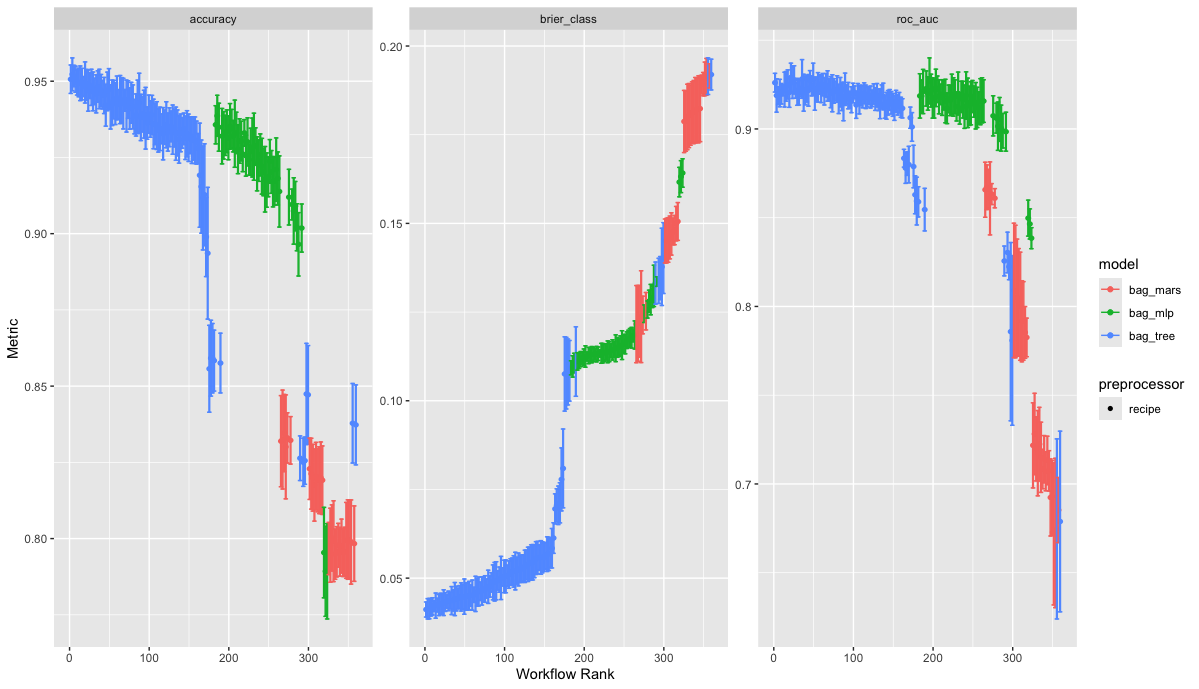
이제, 그리드서치를 통해서 각 모델별로 특정 하이퍼파라미터 값에서의 성능을 구했으므로 상위 5개의 모델을 선택해서 Iterative Search 방식의 Bayesian Optimization을 사용해 좀 더 구체적으로 하이퍼파라미터를 튜닝하였습니다. (tune_bayes의 initial 인자로는 Grid Search의 결과를 활용하였습니다.)
# 상위 5개 모델 선택
top5_model <- grid_results %>% rank_results(rank_metric = "brier_class") %>%
filter(.metric == "brier_class") %>% arrange(mean) %>% slice_head(n=5)
# 하이퍼파라미터 튜닝
metrics = top5_model$wflow_id %>% map(~{
wf <- extract_workflow(grid_results, id=.x)
tune_bayes(wf, resamples = churn_folds, iter = 25,
initial = grid_results %>% filter(wflow_id == .x) %>% pull(result) %>% .[[1]],
metrics = metric_set(roc_auc, brier_class),
control = control_bayes(no_improve = 8, verbose_iter = T, save_workflow = T))})
# 최적의 파라미터 확인
metrics %>% map(select_best, metric = "brier_class")
최적화된 하이퍼파라미터를 finalize_workflow 함수를 사용해서 기존 워크플로에 통합시켰으며 last_fit 함수를 사용해 튜닝된 결과를 이용하여 training data를 학습하여 test data에 대한 성능을 반환하도록 하였습니다.
top5_model_fianl_score <- top5_model %>% mutate(best_param = metrics %>% map(select_best, metric = "brier_class")) %>%
mutate(wf = map2(.x=wflow_id, .y=best_param, ~grid_results %>% extract_workflow(id=.x) %>% finalize_workflow(.y))) %>%
mutate(score = map(.x=wf, .f=function(wf) wf %>% last_fit(split = churn_split) ))
top5_model_fianl_score$wflow_id
top5_model_fianl_score %>% mutate(score_metric = map2(.x=wflow_id, .y=score,
~{collect_metrics(.y) %>% mutate(wflow_id = .x)})) %>%
pull(score_metric) %>% reduce(.f=bind_rows)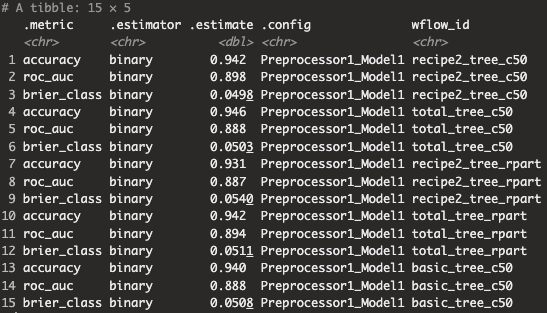
성능이 가장 좋은 "total_tree_c50" 워크플로를 최종 모델로 선정하였으며 ROC_AUC(0.889), PR_AUC(0.821), 정확도(94.6%)는 각각 아래와 같습니다.
### 예측 확인
top5_model_fianl_score$score %>% map(~collect_metrics(.)) %>% reduce(bind_rows)
final_model <- top5_model_fianl_score %>% filter(wflow_id == "total_tree_c50") %>%
pull(score) %>% .[[1]]
# Confusion Matrix
pred <- final_model$.predictions[[1]]
pred %>% conf_mat(truth = churn, estimate = .pred_class)
pred %>% yardstick::accuracy(churn, .pred_class)
# ROC-Curve
pred %>% roc_curve(truth = churn, .pred_yes) %>%autoplot()
pred %>% yardstick::roc_auc(churn, .pred_yes)
# PR-Curve
pred %>% pr_curve(truth = churn, .pred_yes) %>% autoplot()
pred %>% yardstick::pr_auc(churn, .pred_yes)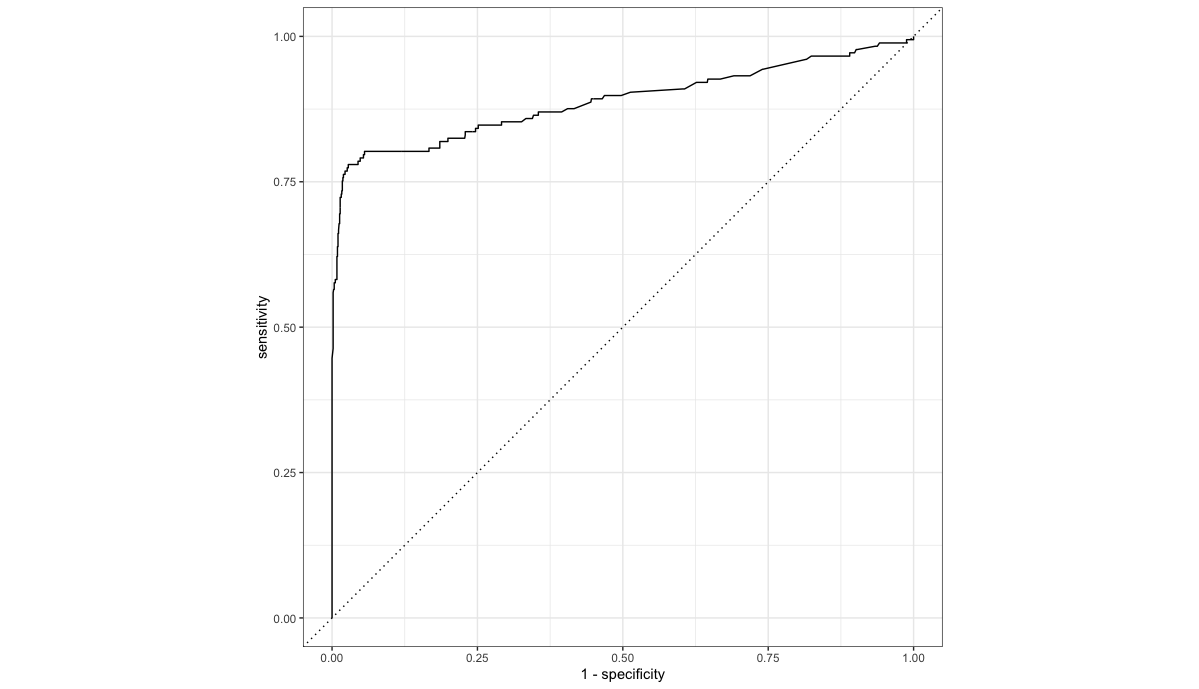
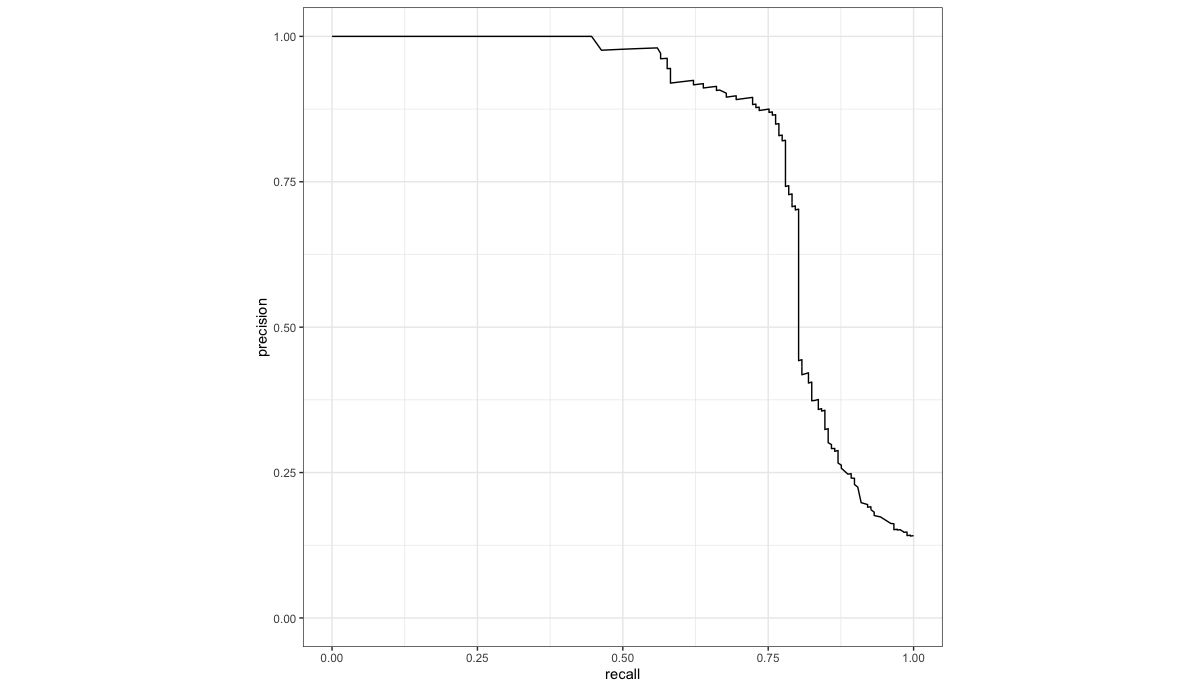
온라인 상에서 나온 결과보다 상당히 좋은 모델인 듯 합니다.
'Data Science > Modeling' 카테고리의 다른 글
| [Tidy Modeling with R] 16. 차원 축소(Dimensionality Reduction) (2) | 2024.01.07 |
|---|---|
| [Tidy Modeling with R] 15. Many Models with Workflow sets (0) | 2024.01.01 |
| [Tidy Modeling With R] 14. Iterative Search with XGBoost (2) | 2023.12.26 |
| [Tidy Modeling With R] 13. Grid Search with XGBoost (2) | 2023.12.22 |
| [Tidy Modeling with R] 12. 하이퍼파라미터 튜닝 (0) | 2023.10.11 |