1. 타이디한 데이터의 특성
- 변수마다 대응되는 열이 있어야 한다.
- 관측마다 대응되는 행이 있어야 한다.
- 값마다 대응되는 하나의 셀이 있어야 한다 (= 두 개 이상의 값이 하나의 셀에 있으면 Tidy 하지 않음! )
데이터 분석에 사용할 tidyverse 라이브러리의 대부분의 함수는 Tidy한 데이터에서 효율적으로 작동하기 때문에 이러한 특성은 중요합니다. (tidyverse 패키지를 사용하면보면 왜 타이디한 데이터가 편한지 자연스럽게 알게 될 겁니다.)
2. Pivot_longer( )
열(Columns)로 흩어진 값들을 하나의 열로 나타낼 때 사용하는 함수로 기존 gather 보다 업그레이드 됨
- pivot_longer(data, cols, names_to="name", values_to="value")
- cols : <tidy-select> longer format으로 피봇할 열들을 지정 (cols_vary 인자는 행들을 어떻게 정렬할지)
- names_to : 여러 열들을 하나의 변수를 나타내는 열로 모을 때 지정할 이름
- names_transform / values_transform : 열의 유형을 변경할 때 사용하며 list(col_name = as.integer)와 같이 사용
- values_to : 값을 나타내는 변수의 이름
- values_drop_na : 피봇되면서 생기는 결측치의 행들을 제거하는 파라미터
- 참고로 변수명 외에 start_with("abc"), ends_with("xyz"), contains("ijk"), matches("regexp")와 같은 함수로 열의 이름을 지정할 수 있으며 2:5와 같이 위치를 지정할 수도 있다. (도우미함수 참고 : https://moogie.tistory.com/45 )

+ names_to 인자는 데이터의 열 이름에 저장된 정보를 사용하여 1개 이상의 열을 생성하는 역할을 합니다.
이때, 길이가 0 또는 NULL이 제공되면 열을 생성하지 않으며, 길이가 1인 경우 단일 열이 생성됩니다.
또한, 길이가 1보다 크면 여러 개의 열이 생성되는데, 열 이름을 분할하기 위해 names_sep, names_pattern을 지정해야 합니다.
iris |>
pivot_longer(cols=Sepal.Length:Petal.Width,
names_to = c("object", "property"),
names_pattern = "(.+)\\.(.+)",
values_to = "measure")
iris |>
pivot_longer(cols=Sepal.Length:Petal.Width,
names_to = c("object", NA, "property"),
names_pattern = "(.+)(\\.)(.+)",
values_to = "measure")
+ [advanced] names_to에는 추가적으로 NA와 ".value"라는 값을 사용할 수 있는데, NA는 위 예제의 두번째 코드와 같이 해당 열을 무시하며, ".value"는 아래 예시와 같이 열 이름의 해당되는 모든 요소를 출력 열의 이름으로 정의합니다.
household
household |> pivot_longer(cols = !family,
names_to = c(".value", "child"),
names_sep = "_")
3. Pivot_wider( )
원래 하나의 데이터 포인트를 구성하는 값의 일부가 여러 행으로 흩어진 경우 하나의 행으로 모으는 함수로 기존 spread 함수보다 업그레이드 됨
- pivot_wider(data, id_cols, names_from, values_from, values_fill=NULL)
- id_cols : 각 관측값을 고유하게 식별하는 열로 names_from, values_from에 포함되지 않는 열이 자동 지정됨
- names_from : 피벗 후 생성될 새로운 열의 이름을 결정하는 기준이 될 열을 지정
- values_from : 피벗 후 해당 열에 들어갈 값이 저장된 열을 지정
- values_fill : 데이터가 없을 때 (Missing Value, NA) 변환할 값
- values_fn : 출력 셀에 적용할 함수로 하나의 셀에 여러 값이 포함된 경우 사용할 수 있다.
pivot_longer와 마찬가지로 names_from과 values_from은 tidy-select 구문을 지원합니다.
이외에도, names_prefix, names_sep, names_glue 등은 열의 이름을 제어하는 파라미터이며 names_sort 인자를 사용해 데이터를 정렬시킬 수 있습니다.
table2
table2 |> pivot_wider(names_from = type, values_from = count)
- (좌) count 변수에는 하나의 변수 값이 들어있는 것이 아닌 cases, population의 변수 값이 섞여있습니다.
- (우) 여러 행으로 흩어진 값들을 하나의 행으로 모았습니다.
+ values_from에 여러 개의 열을 지정하면, 해당 값이 결과 열 이름의 앞부분에 추가됩니다.
us_rent_income |>
pivot_wider(names_from = variable,
values_from = c(estimate, moe))
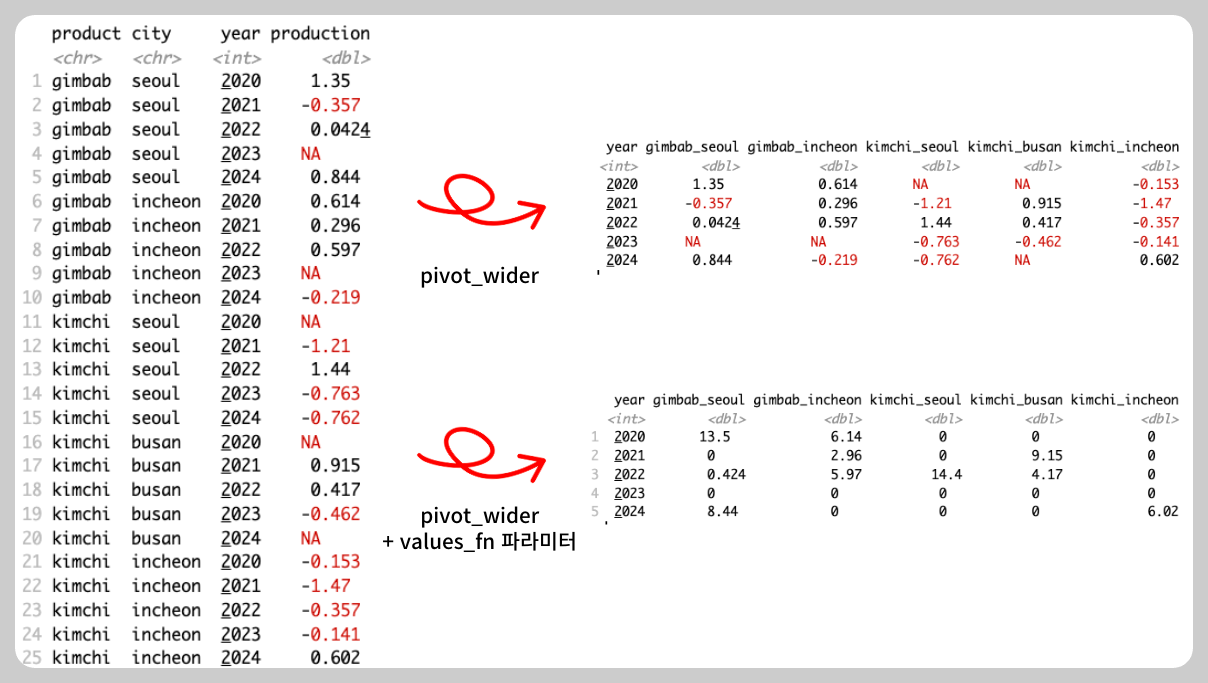
+ values_fn을 사용하여 출력 값에 함수를 적용할 수 있습니다.
production <-
expand_grid(
product = c("gimbab", "kimchi"),
city = c("seoul", "busan", "incheon"),
year = 2020:2024
) |>
filter((product == "kimchi" & city == "busan") | city %in% c("seoul", "incheon"))
production <- production |> mutate(production = sample(c(rep(NA, 5), rnorm(20)), replace = F))
production |> pivot_wider(
names_from = c(product, city),
values_from = production
)
production |> pivot_wider(
names_from = c(product, city),
values_from = production,
values_fn = ~ if_else(.x<0 | is.na(.x), 0, .x*10)
)
4. Separate 계열 함수
셀의 값이 여러개의 변수가 섞인 문자열 형태를 가지고 있는 경우 여러 개의 열로 분리하는 함수
- separate_longer(wider)_delim : Delimiter(구분자)를 통해 문자열을 분리
- separate_longer(wider)_position : 고정된 너비로 문자열을 분리
- separate_wider_regex : 정규표현식을 사용해 문자열을 분리
- cols : 분리할 열을 명시 (tidy-select 지원)
- delim : 구분자를 지정하여 값을 분리
- widths : named numeric vector(name = column name, numeric value = column width)
- patterns : named character vector (name = column name, character value = regexp)
- names : separate_wider 함수를 사용할 때 분리된 값이 들어갈 열이름 지정
table3
table3 |> separate_wider_delim(cols = rate, delim = '/', names = c("case", "population"))
table3 |> separate_longer_delim(cols = rate, delim = "/")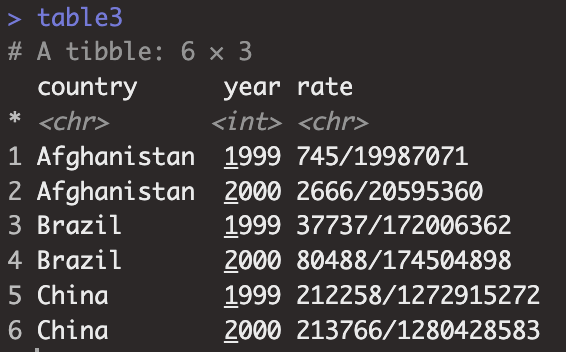


5. Unite( )
여러 열을에 있는 값을 모아 하나의 열의 값으로 결합
- unite(data, col, ..., sep = "_", remove = T, na.rm = T)
- col : 새로운 열의 이름
- dot-dot-dot(...) : <Tidy-select> 통합할 열들
- sep : 값을 하나로 합칠 때, 값 사이 들어가는 문자
table5
table5 |> unite(new_year, century, year, sep="")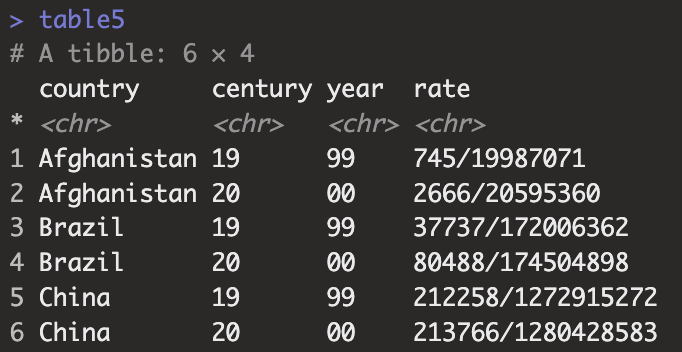

6. Complete( ) & Expand( )
주어진 변수들의 모든 값 조합을 명시적으로 표현 (implicit missing value -> exxplicit missing value)
- complete(data, ...) : ...에 나오는 각 변수들의 값의 조합을 출력함 (중복나올 수 있음)
- expand(data, ...) : ...에 나오는 각 변수들의 유일한 값의 조합을 출력함 (중복 안나옴)
팩터형(factor) 데이터에 사용할 경우 두 함수 모두 데이터에는 없더라도 모든 범주(levels)를 조합
- Helper function : crossing(de-duplicates and sorts)과 nesting(only finds combinations already present in the data)
toy <- tibble(a = c(1,1,2,3,3,3), b=c("a","a","b","b","b","c"))
toy |> complete(a,b)
toy |> expand(a,b)
toy |> complete(nesting(a,b)) # generate all combination of variables found in a dataset
toy |> expand(nesting(a,b)) # unique (a,b) value that already in the data
7. Fill( )
분할표나 사례대조연구와 같은 데이터에서 많이 나타나는 결측값이 이전 값과 연관이 있는 경우 사용
- fill(data, ..., .direction)
- .direction을 통해 어떻게 결측값을 채울지 결정 ("down", "up", "downup", "updown")
hospital <- tribble(
~name, ~qt, ~treat,
"A", 1, 2000,
NA, 2, 2500,
NA, 3, 1000,
NA, 4, 3800,
"B", 1, 650,
NA, 2, 1200,
NA, 3, 3900,
NA, 4, 1400)
hospital |> fill(name,.direction = "down")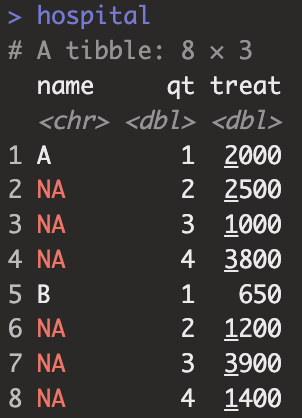

8. Drop_na( )
Missing value가 포함된 행을 제거하는 함수
- drop_na(data, ...)
- data : 데이터프레임
- dot-dot-dot(...) : <tidy-select> Missing value가 있는지 확인할 열들
참고로, dot-dot-dot(...)에 열을 지정하지 않으면 모든 열을 대상으로 수행합니다.
df <- tibble(x = c(1, 2, NA), y = c("a", NA, "b"))
df |> drop_na()
df |> drop_na(x)


- Reference
- R for Data Science (1st & 2nd) Edition - Hadely Wickham
- tidyr article (https://tidyr.tidyverse.org)
'Data Science > Manipulation' 카테고리의 다른 글
| [Data Science With R] 9. 정규표현식(Regular Expression) with Stringr (202406) (0) | 2023.04.04 |
|---|---|
| [Data Science With R] 8. 관계형 데이터 (0) | 2023.04.01 |
| [Data Science With R] 6. 파싱(Parsing) (202405) (0) | 2023.03.31 |
| [Data Science With R] 5. readr로 파일 읽기 (202503) (0) | 2023.03.31 |
| [Data Science With R] 4. 티블(Tibble) (202406) (1) | 2023.03.30 |